







文件处理模型
输入,处理,输出。
输入:读取4个队员的训练数据,读取4个文件
james.txt 2-34,3:21,2,34,2.45,3.01,2:01,2:01,3:10,2-22
sarah.txt 2:58,2.58,2:39,2-25,2:55,2:54,2.18,2:55,2:55
julie.txt 2.59,2.11,2:11,2:23,3-10,2-23,3:10,3.21,3-21
mikey.txt 2:22,3.01,3:01,3.02,3:02,3.02,3:22,2.49,2:38
处理:标准化数据,切分数据,top3(最快的3个时间)
输出:将每个人的信息打印在屏幕上显示
kelly教练,每次训练结束后,还要同步更新4个文件太麻烦了,把所有记录写在一个文件中吧,这个对于你来说应该不难吧?
In [ ]
f = open('work/train_data_cor.txt')
line = f.readline()
print(line)
line = f.readline()
print(line)
f.close()
james,2004-5-21,2.34,3:21,2.34,2.45,3.01,2:01,2:01,3:10,2-22
julie,2006-5-9,2.59,2.11,2:11,2:23,3-10,2-23,3:10,3.21,3-21
open() 为bif(内置函数),参数有多个,必须的是文件路径。 返回的一个文件对象。
file.readline(),读取文件中的一行。
In [ ]
import sys
#读取整个文件内容
f = open('work/train_data_cor.txt')
line = f.readline()
while(line != ''):
print(line)
line = f.readline()
f.close()
james,2004-5-21,2.34,3:21,2.34,2.45,3.01,2:01,2:01,3:10,2-22
julie,2006-5-9,2.59,2.11,2:11,2:23,3-10,2-23,3:10,3.21,3-21
sarah,2004-3-8,2:58,2.58,2:39,2-25,2-55,2:54,2.18,2:55,2:55
mikey,2003-9-10,2:22,3.01,3:01,3.02,3:02,3.02,3:22,2.49,2:38
In [ ]
#更好的方式
f = open('work/train_data_cor.txt')
for line in f:
print(line)
f.close()james,2004-5-21,2.34,3:21,2.34,2.45,3.01,2:01,2:01,3:10,2-22
julie,2006-5-9,2.59,2.11,2:11,2:23,3-10,2-23,3:10,3.21,3-21
sarah,2004-3-8,2:58,2.58,2:39,2-25,2-55,2:54,2.18,2:55,2:55
mikey,2003-9-10,2:22,3.01,3:01,3.02,3:02,3.02,3:22,2.49,2:38
如果数据有问题呢?
In [ ]
f = open('work/train_data_wrg.txt')
for line in f:
data = line.strip().split(',')
print('姓名:'+data.pop(0)+'生日:'+data.pop(0)+'时间:'+str(data))
f.close()姓名:james生日:2004-5-21时间:['2.34', '3:21', '2.34', '2.45', '3.01', '2:01', '2:01', '3:10', '2-22']
姓名:julie生日:2006-5-9时间:['2.59', '2.11', '2:11', '2:23', '3-10', '2-23', '3:10', '3.21', '3-21']
---------------------------------------------------------------------------IndexError Traceback (most recent call last)<ipython-input-14-a51a9349f79f> in <module> 3 data = line.strip().split(',') 4 ----> 5 print('姓名:'+data.pop(0)+'生日:'+data.pop(0)+'时间:'+str(data)) 6 f.close() IndexError: pop from empty list
有两种解决办法:
1.使用异常跳过有问题的数据 2.增加代码判断
In [ ]
#使用异常
f = open('work/train_data_wrg.txt')
for line in f:
data = line.strip().split(',')
try:
print('姓名:'+data.pop(0)+'生日:'+data.pop(0)+'时间:'+str(data))
except:
pass
f.close()姓名:james生日:2004-5-21时间:['2.34', '3:21', '2.34', '2.45', '3.01', '2:01', '2:01', '3:10', '2-22']
姓名:julie生日:2006-5-9时间:['2.59', '2.11', '2:11', '2:23', '3-10', '2-23', '3:10', '3.21', '3-21']
姓名:sarah生日:2004-3-8时间:['2:58', '2.58', '2:39', '2-25', '2-55', '2:54', '2.18', '2:55', '2:55']
姓名:mikey生日:2003-9-10时间:['2:22', '3.01', '3:01', '3.02', '3:02', '3.02', '3:22', '2.49', '2:38']
In [ ]
#代码判断
f = open('work/train_data_wrg.txt')#1
for line in f:#2
data = line.strip().split(',')
if len(data) != 1:
print('姓名:'+data.pop(0)+'生日:'+data.pop(0)+'时间:'+str(data))
f.close()#3
姓名:james生日:2004-5-21时间:['2.34', '3:21', '2.34', '2.45', '3.01', '2:01', '2:01', '3:10', '2-22']
姓名:julie生日:2006-5-9时间:['2.59', '2.11', '2:11', '2:23', '3-10', '2-23', '3:10', '3.21', '3-21']
姓名:sarah生日:2004-3-8时间:['2:58', '2.58', '2:39', '2-25', '2-55', '2:54', '2.18', '2:55', '2:55']
姓名:mikey生日:2003-9-10时间:['2:22', '3.01', '3:01', '3.02', '3:02', '3.02', '3:22', '2.49', '2:38']
In [ ]
#clean的写法,三行变一行
with open('work/train_data_cor.txt') as f:
for line in f:
data = line.strip().split(',')
print('姓名:'+data.pop(0)+'生日:'+data.pop(0)+'时间:'+str(data))
姓名:james生日:2004-5-21时间:['2.34', '3:21', '2.34', '2.45', '3.01', '2:01', '2:01', '3:10', '2-22']
姓名:julie生日:2006-5-9时间:['2.59', '2.11', '2:11', '2:23', '3-10', '2-23', '3:10', '3.21', '3-21']
姓名:sarah生日:2004-3-8时间:['2:58', '2.58', '2:39', '2-25', '2-55', '2:54', '2.18', '2:55', '2:55']
姓名:mikey生日:2003-9-10时间:['2:22', '3.01', '3:01', '3.02', '3:02', '3.02', '3:22', '2.49', '2:38']
如果文件不存在呢?
f = open('work/train_data1.txt') for line in f:
data = line.strip().split(',')
if len(data) != 1:
print('姓名:'+data.pop(0)+'生日:'+data.pop(0)+'时间:'+data)
f.close()
file对象的函数列表
In [ ]
with open('work/train_data.txt') as f:
data = f.read()
print('整个文件\n'+data)
f.seek(0)
data = f.read(10)
print('读取指定大小的文件内容\n'+data)
print(f.tell())
整个文件
james,2004-5-21,2.34,3:21,2.34,2.45,3.01,2:01,2:01,3:10,2-22
julie,2006-5-9,2.59,2.11,2:11,2:23,3-10,2-23,3:10,3.21,3-21
kenny
sarah,2004-3-8,2:58,2.58,2:39,2-25,2-55,2:54,2.18,2:55,2:55
mikey,2003-9-10,2:22,3.01,3:01,3.02,3:02,3.02,3:22,2.49,2:38
读取指定大小的文件内容
james,2004
10
如何写入文件内容呢?
In [ ]
f = open('work/data.txt','w')
f.write('this is file content')
f.close()Help on built-in function close:
close() method of _io.TextIOWrapper instance
Flush and close the IO object.
This method has no effect if the file is already closed.
open('work/data.txt','w')第一个参数文件路径,第二个参数打开文件的模式
f.write('this is file content')参数为写入的内容 f.close()关闭文件
对象转JSON
In [ ]
import json
class Athlete(json.JSONEncoder):
def __init__(self,a_name,a_dob=None,a_times=[]):
self.name = a_name
self.dob = a_dob
self.times = a_times
def top3(self):
return sorted(set([self.sanitize(t) for t in self.times]))[0:3]
def sanitize(self,time_string):
if '-' in time_string:
splitter = '-'
elif ':' in time_string:
splitter = ':'
else:
return (time_string)
(mins,secs) = time_string.split(splitter)
return (mins+'.'+secs)
with open('work/train_data_cor.txt') as f:
data = f.readline().strip().split(',')
ath = Athlete(data.pop(0),data.pop(0),data)
print(ath)
ath_json = json.dumps(ath.__dict__)
<__main__.Athlete object at 0x7fdd6cc6a450>
内中的json形式的变量保存到文件
In [ ]
with open('work/json.txt','w') as f:
json.dump(ath_json,f)
读取json文件内容
In [ ]
with open('work/json.txt') as f:
ath = json.load(f)
print(ath)
{"name": "james", "dob": "2004-5-21", "times": ["2.34", "3:21", "2.34", "2.45", "3.01", "2:01", "2:01", "3:10", "2-22"]}
目录访问
In [ ]
import os
#返回当前工作目录
current_path = os.getcwd()
print('当前路径:'+current_path)In [ ]
#改变当前工作目录
os.chdir('/home/aistudio/work')
#运行mkdir命令
os.system('mkdir today')In [ ]
from pathlib import Path
#返回当前绝对路径
abs_path = os.path.abspath('')
print('abs_path:'+abs_path)
#路径是否存在
Path(abs_path).exists()In [ ]
print('当前路径:'+os.getcwd())
listdir = os.listdir()
#返回当前路径下文件和文件夹名
print(listdir)
In [ ]
#是否为文件夹
os.path.isdir('/home/aistudio/work/today')问题:显示work路径下的所有类型为txt的文件
In [ ]
import os
listdir = os.listdir('/home/aistudio/work')
target = []
for name in listdir:
#防止文件名与文件夹名一样的情况
# print(os.path.isfile(name))
temp = name.split('.')
(filename,filetype) = (temp.pop(0),temp.pop(0))
if filetype == 'txt':
target.append(name)
# print('name:%s,type:%s' %(filename,filetype))
print(target)问题:temp = name.split('.')在name为dir1时出现问题
In [ ]
import os
path = '/home/aistudio/work'
listdir = os.listdir(path)
target = []
for name in listdir:
#防止文件名与文件夹名一样的情况
# print(os.path.isfile(name))
if os.path.isfile(path+'/'+name):
temp = name.split('.')
(filename,filetype) = (temp.pop(0),temp.pop(0))
if filetype == 'txt':
target.append(name)
# print('name:%s,type:%s' %(filename,filetype))
print(target)如果dir1中包含文件呢?
In [ ]
import os
target = []
path = '/home/aistudio/work'
listdir = os.listdir(path)
for name in listdir:
#防止文件名与文件夹名一样的情况
if os.path.isfile(path+'/'+name):
temp = name.split('.')
(filename,filetype) = (temp.pop(0),temp.pop(0))
if filetype == 'txt':
target.append(name)
else:
#如果是文件夹,需要读取该文件夹的列表
dir_path = path+'/'+name
listdir = os.listdir(dir_path)
for name in listdir:
#防止文件名与文件夹名一样的情况
if os.path.isfile(dir_path+'/'+name):
temp = name.split('.')
(filename,filetype) = (temp.pop(0),temp.pop(0))
if filetype == 'txt':
target.append(name)
print('结果:'+str(target))如果dir1中又包含文件夹该怎么办呢?
有重复的代码,我们就会想到循环
In [ ]
import os
def recur(path):
listdir = os.listdir(path)
for name in listdir:
if name[0] is '.' or name[0] is '_':
continue
next_path = path+'/'+name
if os.path.isfile(next_path) :
# print(next_path + '=====isfile')
temp = name.split('.')
(filename,filetype) = (temp.pop(0),temp.pop(0))
if filetype == 'txt':
target.append(name)
else:
recur(next_path)
return os.path.dirname(next_path)
path = '/home/aistudio/work'
target = []
recur(path)
print(target)
怎么一步一步运行程序,并观察程序中变量的值
In [ ]
import pdb
import os
def recur(path):
listdir = os.listdir(path)
for name in listdir:
if name[0] is '.' or name[0] is '_':
continue
next_path = path+'/'+name
if os.path.isfile(next_path) :
# print(next_path + '=====isfile')
temp = name.split('.')
(filename,filetype) = (temp.pop(0),temp.pop(0))
if filetype == 'txt':
target.append(name)
else:
recur(next_path)
return os.path.dirname(next_path)
if __name__ == '__main__':
pdb.set_trace()
path = '/home/aistudio/work'
target = []
recur(path)
print(target)
In [ ]
#制造数据
with open('work/loren.txt','w+') as f:
for i in range(5000000):
f.write('loren,2011-11-3,270,3.59,4.11,3:11,3:23,4-10,3-23,4:10,4.21,4-21')
f.write('\n')In [ ]
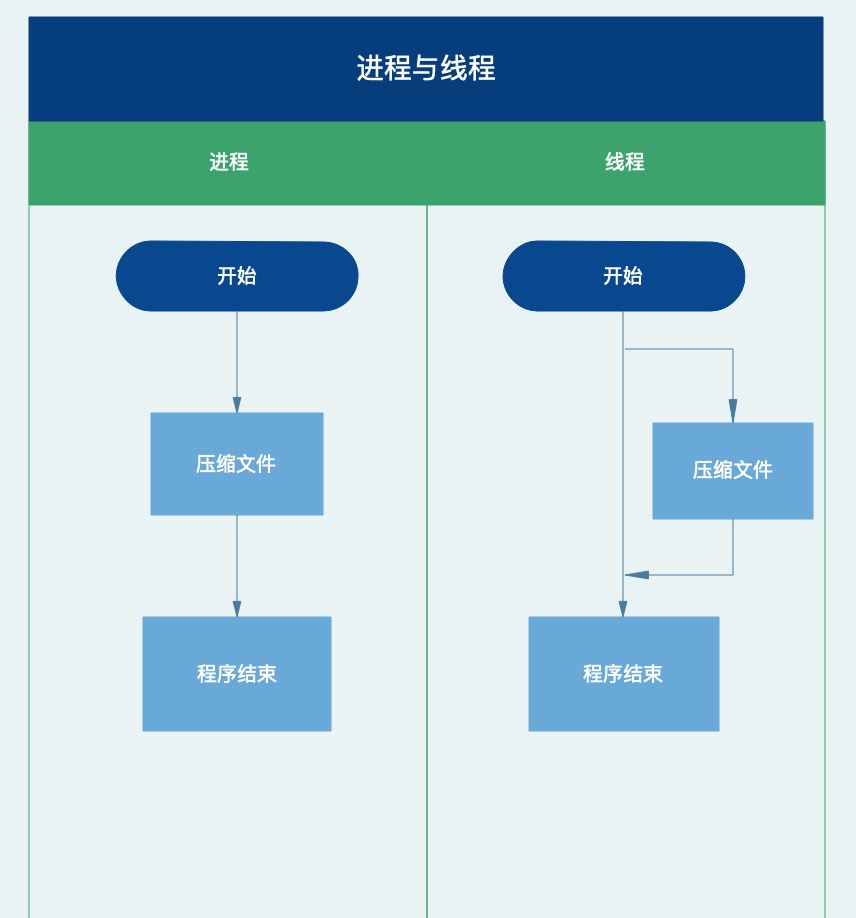
#只使用进程的方式
print('压缩作业开始了,请您耐心等待...')
infile = 'work/loren.txt'
outfile = 'work/myarchive.zip'
f = zipfile.ZipFile(outfile, 'w', zipfile.ZIP_DEFLATED)
f.write(infile)
f.close()
print('压缩作业结束了,请问还需要帮您做什么呢?')#使用进程+线程的方式
In [ ]
import threading, zipfile
class AsyncZip(threading.Thread):
def __init__(self, infile, outfile):
threading.Thread.__init__(self)
self.infile = infile
self.outfile = outfile
def run(self):
f = zipfile.ZipFile(self.outfile, 'w', zipfile.ZIP_DEFLATED)
f.write(self.infile)
f.close()
print('压缩完成,您要的文件在:', self.outfile)
background = AsyncZip('work/loren.txt', 'work/myarchive.zip')
print('压缩作业开始了,请您耐心等待...')
background.start()
print('我正在为您压缩,请问还需要帮您做什么呢?')
background.join()















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











