









概念
图像分类引导了卷积神经网络的发展

LeNet-5卷积神经网络(CNN)的开山鼻祖

深度开发万能公式

初识卷积神经网络




代码实战
回顾深度学习万能公式

① 问题定义
图像分类,使用LeNet-5网络完成手写数字识别图片的分类。
In [1]
import paddle
import numpy as np
import matplotlib.pyplot as plt
paddle.__version__② 数据准备
继续应用框架中封装好的手写数字识别数据集。
2.1 数据集加载和预处理
In [2]
# 数据预处理
import paddle.vision.transforms as T
# 数据预处理,TODO:找一下提出的原论文看一下
transform = T.Normalize(mean=[127.5], std=[127.5])
# 训练数据集
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=transform)
# 验证数据集
eval_dataset = paddle.vision.datasets.MNIST(mode='test', transform=transform)
print('训练样本量:{},测试样本量:{}'.format(len(train_dataset), len(eval_dataset)))2.2 数据查看
In [3]
print('图片:')
print(type(train_dataset[0][0]))
print(train_dataset[0][0])
print('标签:')
print(type(train_dataset[0][1]))
print(train_dataset[0][1])
# 可视化展示
plt.figure()
plt.imshow(train_dataset[0][0].reshape([28,28]), cmap=plt.cm.binary)
plt.show()③ 模型选择和开发
我们选用LeNet-5网络结构。
LeNet-5模型源于论文“LeCun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324.”,
论文地址:https://ieeexplore.ieee.org/document/726791
3.1 网络结构定义
3.1.1 模型介绍

每个阶段用到的Layer

3.1.2 网络结构代码实现1
理解原论文进行的复现实现,因为模型论文出现在1998年,很多技术还不是最新。
In [5]
import paddle.nn as nn
network = nn.Sequential(
nn.Conv2D(in_channels=1, out_channels=6, kernel_size=5, stride=1, padding=0), # C1 卷积层
nn.Tanh(),
nn.AvgPool2D(kernel_size=2, stride=2), # S2 平局池化层
nn.Sigmoid(), # Sigmoid激活函数
nn.Conv2D(in_channels=6, out_channels=16, kernel_size=5, stride=1, padding=0), # C3 卷积层
nn.Tanh(),
nn.AvgPool2D(kernel_size=2, stride=2), # S4 平均池化层
nn.Sigmoid(), # Sigmoid激活函数
nn.Conv2D(in_channels=16, out_channels=120, kernel_size=5, stride=1, padding=0), # C5 卷积层
nn.Tanh(),
nn.Flatten(),
nn.Linear(in_features=120, out_features=84), # F6 全连接层
nn.Tanh(),
nn.Linear(in_features=84, out_features=10) # OUTPUT 全连接层
)模型可视化
In [6]
paddle.summary(network, (1, 1, 32, 32))3.1.3 网络结构代码实现2
应用了截止到现在为止新的技术点实现后的模型,用Sequential写法。
In [7]
import paddle.nn as nn
network_2 = nn.Sequential(
nn.Conv2D(in_channels=1, out_channels=6, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2D(kernel_size=2, stride=2),
nn.Conv2D(in_channels=6, out_channels=16, kernel_size=5, stride=1, padding=0),
nn.ReLU(),
nn.MaxPool2D(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(in_features=400, out_features=120), # 400 = 5x5x16,输入形状为32x32, 输入形状为28x28时调整为256
nn.Linear(in_features=120, out_features=84),
nn.Linear(in_features=84, out_features=10)
)模型可视化
In [8]
paddle.summary(network_2, (1, 1, 28, 28))3.1.4 网络结构代码实现3
应用了截止到现在为止新的技术点实现后的模型,模型结构和【网络结构代码实现2】一致,用Sub Class写法。
In [9]
class LeNet(nn.Layer):
"""
继承paddle.nn.Layer定义网络结构
"""
def __init__(self, num_classes=10):
"""
初始化函数
"""
super(LeNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2D(in_channels=1, out_channels=6, kernel_size=3, stride=1, padding=1), # 第一层卷积
nn.ReLU(), # 激活函数
nn.MaxPool2D(kernel_size=2, stride=2), # 最大池化,下采样
nn.Conv2D(in_channels=6, out_channels=16, kernel_size=5, stride=1, padding=0), # 第二层卷积
nn.ReLU(), # 激活函数
nn.MaxPool2D(kernel_size=2, stride=2) # 最大池化,下采样
)
self.fc = nn.Sequential(
nn.Linear(400, 120), # 全连接
nn.Linear(120, 84), # 全连接
nn.Linear(84, num_classes) # 输出层
)
def forward(self, inputs):
"""
前向计算
"""
y = self.features(inputs)
y = paddle.flatten(y, 1)
out = self.fc(y)
return out
network_3 = LeNet()模型可视化
In [10]
paddle.summary(network_3, (1, 1, 28, 28))3.1.4 网络结构代码实现4
直接应用高层API中封装好的LeNet网络接口。
In [11]
network_4 = paddle.vision.models.LeNet(num_classes=10)3.1.4 模型可视化
通过summary接口来查看搭建的网络结构,查看输入和输出形状,以及需要训练的参数信息。
In [12]
paddle.summary(network_4, (1, 1, 28, 28))④ 模型训练和优化
模型配置
- 优化器:SGD
- 损失函数:交叉熵(cross entropy)
- 评估指标:Accuracy
In [53]
# 模型封装
model = paddle.Model(network_4)
# 模型配置
model.prepare(paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters()), # 优化器
paddle.nn.CrossEntropyLoss(), # 损失函数
paddle.metric.Accuracy()) # 评估指标
# 启动全流程训练
model.fit(train_dataset, # 训练数据集
eval_dataset, # 评估数据集
epochs=5, # 训练轮次
batch_size=64, # 单次计算数据样本量
verbose=1) # 日志展示形式⑤ 模型评估
5.1 模型评估
In [26]
result = model.evaluate(eval_dataset, verbose=1)
print(result)5.2 模型预测
5.2.1 批量预测
使用model.predict接口来完成对大量数据集的批量预测。
In [27]
# 进行预测操作
result = model.predict(eval_dataset)In [28]
# 定义画图方法
def show_img(img, predict):
plt.figure()
plt.title('predict: {}'.format(predict))
plt.imshow(img.reshape([28, 28]), cmap=plt.cm.binary)
plt.show()
# 抽样展示
indexs = [2, 15, 38, 211]
for idx in indexs:
show_img(eval_dataset[idx][0], np.argmax(result[0][idx]))⑥ 部署上线
6.1 保存模型
In [29]
model.save('finetuning/mnist')6.2 继续调优训练
In [33]
from paddle.static import InputSpec
network = paddle.vision.models.LeNet(num_classes=10)
# 模型封装,为了后面保存预测模型,这里传入了inputs参数
model_2 = paddle.Model(network, inputs=[InputSpec(shape=[-1, 1, 28, 28], dtype='float32', name='image')])
# 加载之前保存的阶段训练模型
model_2.load('finetuning/mnist')
# 模型配置
model_2.prepare(paddle.optimizer.Adam(learning_rate=0.0001, parameters=network.parameters()), # 优化器
paddle.nn.CrossEntropyLoss(), # 损失函数
paddle.metric.Accuracy()) # 评估函数
# 模型全流程训练
model_2.fit(train_dataset, # 训练数据集
eval_dataset, # 评估数据集
epochs=2, # 训练轮次
batch_size=64, # 单次计算数据样本量
verbose=1) # 日志展示形式6.3 保存预测模型
In [34]
# 保存用于后续推理部署的模型
model_2.save('infer/mnist', training=False)
导入相关库
In [ ]
import paddle
import numpy as np
import matplotlib.pyplot as plt
paddle.__version__'2.0.0'
② 数据准备
2.1 数据加载和预处理
In [ ]
import paddle.vision.transforms as T
# 数据的加载和预处理
transform = T.Normalize(mean=[127.5], std=[127.5])
# 训练数据集
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=transform)
# 评估数据集
eval_dataset = paddle.vision.datasets.MNIST(mode='test', transform=transform)
print('训练集样本量: {},验证集样本量: {}'.format(len(train_dataset), len(eval_dataset)))训练集样本量: 60000,验证集样本量: 10000
2.2 数据集查看
In [65]
print('图片:')
print(type(train_dataset[0][0]))
print(train_dataset[0][0])
print('标签:')
print(type(train_dataset[0][1]))
print(train_dataset[0][1])
# 可视化展示
plt.figure()
plt.imshow(train_dataset[0][0].reshape([28,28]), cmap=plt.cm.binary)
plt.show()
图片:
<class 'numpy.ndarray'>
[[[-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. ]
[-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. ]
[-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. ]
[-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. ]
[-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. ]
[-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -0.9764706 -0.85882354 -0.85882354
-0.85882354 -0.01176471 0.06666667 0.37254903 -0.79607844
0.3019608 1. 0.9372549 -0.00392157 -1.
-1. -1. -1. ]
[-1. -1. -1. -1. -1.
-1. -1. -1. -0.7647059 -0.7176471
-0.2627451 0.20784314 0.33333334 0.9843137 0.9843137
0.9843137 0.9843137 0.9843137 0.7647059 0.34901962
0.9843137 0.8980392 0.5294118 -0.49803922 -1.
-1. -1. -1. ]
[-1. -1. -1. -1. -1.
-1. -1. -0.6156863 0.8666667 0.9843137
0.9843137 0.9843137 0.9843137 0.9843137 0.9843137
0.9843137 0.9843137 0.96862745 -0.27058825 -0.35686275
-0.35686275 -0.56078434 -0.69411767 -1. -1.
-1. -1. -1. ]
[-1. -1. -1. -1. -1.
-1. -1. -0.85882354 0.7176471 0.9843137
0.9843137 0.9843137 0.9843137 0.9843137 0.5529412
0.42745098 0.9372549 0.8901961 -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. ]
[-1. -1. -1. -1. -1.
-1. -1. -1. -0.37254903 0.22352941
-0.16078432 0.9843137 0.9843137 0.60784316 -0.9137255
-1. -0.6627451 0.20784314 -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. ]
[-1. -1. -1. -1. -1.
-1. -1. -1. -1. -0.8901961
-0.99215686 0.20784314 0.9843137 -0.29411766 -1.
-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. ]
[-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. 0.09019608 0.9843137 0.49019608 -0.9843137
-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. ]
[-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -0.9137255 0.49019608 0.9843137 -0.4509804
-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. ]
[-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -0.7254902 0.8901961 0.7647059
0.25490198 -0.15294118 -0.99215686 -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. ]
[-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. -0.3647059 0.88235295
0.9843137 0.9843137 -0.06666667 -0.8039216 -1.
-1. -1. -1. -1. -1.
-1. -1. -1. ]
[-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. -1. -0.64705884
0.45882353 0.9843137 0.9843137 0.1764706 -0.7882353
-1. -1. -1. -1. -1.
-1. -1. -1. ]
[-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-0.8745098 -0.27058825 0.9764706 0.9843137 0.46666667
-1. -1. -1. -1. -1.
-1. -1. -1. ]
[-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. 0.9529412 0.9843137 0.9529412
-0.49803922 -1. -1. -1. -1.
-1. -1. -1. ]
[-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. -1. -0.6392157
0.01960784 0.43529412 0.9843137 0.9843137 0.62352943
-0.9843137 -1. -1. -1. -1.
-1. -1. -1. ]
[-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -0.69411767 0.16078432 0.79607844
0.9843137 0.9843137 0.9843137 0.9607843 0.42745098
-1. -1. -1. -1. -1.
-1. -1. -1. ]
[-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-0.8117647 -0.10588235 0.73333335 0.9843137 0.9843137
0.9843137 0.9843137 0.5764706 -0.3882353 -1.
-1. -1. -1. -1. -1.
-1. -1. -1. ]
[-1. -1. -1. -1. -1.
-1. -1. -1. -0.81960785 -0.48235294
0.67058825 0.9843137 0.9843137 0.9843137 0.9843137
0.5529412 -0.3647059 -0.9843137 -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. ]
[-1. -1. -1. -1. -1.
-1. -0.85882354 0.34117648 0.7176471 0.9843137
0.9843137 0.9843137 0.9843137 0.5294118 -0.37254903
-0.92941177 -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. ]
[-1. -1. -1. -1. -0.5686275
0.34901962 0.77254903 0.9843137 0.9843137 0.9843137
0.9843137 0.9137255 0.04313726 -0.9137255 -1.
-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. ]
[-1. -1. -1. -1. 0.06666667
0.9843137 0.9843137 0.9843137 0.6627451 0.05882353
0.03529412 -0.8745098 -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. ]
[-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. ]
[-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. ]
[-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. -1. -1.
-1. -1. -1. ]]]
标签:
<class 'numpy.ndarray'>
[5]

<Figure size 432x288 with 1 Axes>
③ 模型选择和开发
3.1 模型组网
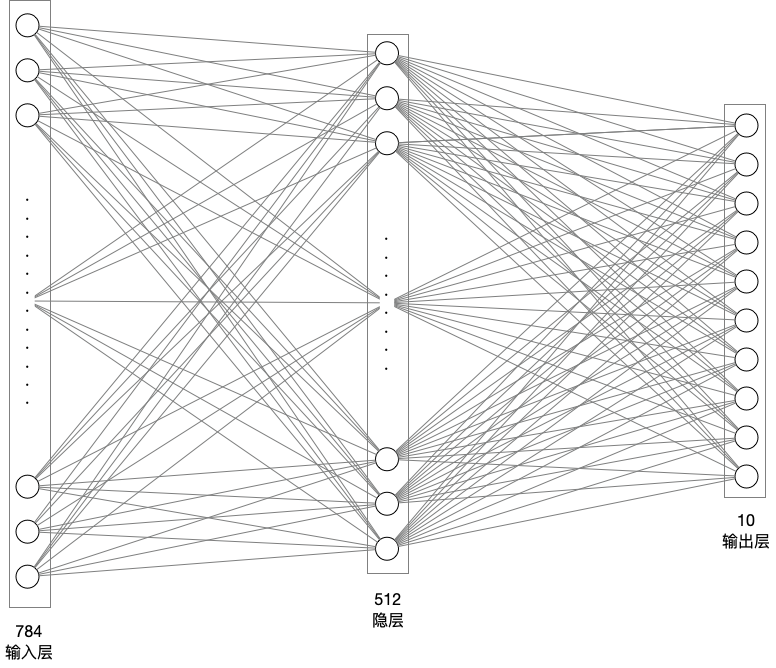
In [ ]
# 模型网络结构搭建
network = paddle.nn.Sequential(
paddle.nn.Flatten(), # 拉平,将 (28, 28) => (784)
paddle.nn.Linear(784, 512), # 隐层:线性变换层
paddle.nn.ReLU(), # 激活函数
paddle.nn.Linear(512, 10) # 输出层
)模型网络结构可视化
In [37]
# 模型封装
model = paddle.Model(network)
# 模型可视化
model.summary((1, 28, 28))---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Flatten-1 [[1, 28, 28]] [1, 784] 0
Linear-1 [[1, 784]] [1, 512] 401,920
ReLU-1 [[1, 512]] [1, 512] 0
Linear-2 [[1, 512]] [1, 10] 5,130
===========================================================================
Total params: 407,050
Trainable params: 407,050
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.01
Params size (MB): 1.55
Estimated Total Size (MB): 1.57
---------------------------------------------------------------------------
{'total_params': 407050, 'trainable_params': 407050}
In [38]
# 配置优化器、损失函数、评估指标
model.prepare(paddle.optimizer.Adam(learning_rate=0.001, parameters=network.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
# 启动模型全流程训练
model.fit(train_dataset, # 训练数据集
eval_dataset, # 评估数据集
epochs=5, # 训练的总轮次
batch_size=64, # 训练使用的批大小
verbose=1) # 日志展示形式The loss value printed in the log is the current step, and the metric is the average value of previous step. Epoch 1/5 step 938/938 [==============================] - loss: 0.0325 - acc: 0.9902 - 7ms/step Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 157/157 [==============================] - loss: 7.0694e-04 - acc: 0.9807 - 6ms/step Eval samples: 10000 Epoch 2/5 step 938/938 [==============================] - loss: 0.0028 - acc: 0.9920 - 7ms/step Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 157/157 [==============================] - loss: 6.0556e-05 - acc: 0.9744 - 6ms/step Eval samples: 10000 Epoch 3/5 step 938/938 [==============================] - loss: 0.0070 - acc: 0.9932 - 7ms/step Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 157/157 [==============================] - loss: 1.0386e-04 - acc: 0.9767 - 6ms/step Eval samples: 10000 Epoch 4/5 step 938/938 [==============================] - loss: 0.0012 - acc: 0.9928 - 7ms/step Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 157/157 [==============================] - loss: 5.0365e-06 - acc: 0.9790 - 6ms/step Eval samples: 10000 Epoch 5/5 step 938/938 [==============================] - loss: 0.0416 - acc: 0.9925 - 7ms/step Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 157/157 [==============================] - loss: 1.2732e-05 - acc: 0.9795 - 6ms/step Eval samples: 10000
⑤ 模型评估测试
5.1 模型评估
In [40]
# 模型评估,根据prepare接口配置的loss和metric进行返回
result = model.evaluate(eval_dataset, verbose=1)
print(result)Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 10000/10000 [==============================] - loss: 0.0000e+00 - acc: 0.9795 - 2ms/step
Eval samples: 10000
{'loss': [0.0], 'acc': 0.9795}
5.2 模型预测
5.2.1 批量预测
使用model.predict接口来完成对大量数据集的批量预测。
In [48]
# 进行预测操作
result = model.predict(eval_dataset)
# 定义画图方法
def show_img(img, predict):
plt.figure()
plt.title('predict: {}'.format(predict))
plt.imshow(img.reshape([28, 28]), cmap=plt.cm.binary)
plt.show()
# 抽样展示
indexs = [2, 15, 38, 211]
for idx in indexs:
show_img(eval_dataset[idx][0], np.argmax(result[0][idx]))Predict begin... step 10000/10000 [==============================] - 1ms/step Predict samples: 10000

<Figure size 432x288 with 1 Axes>

<Figure size 432x288 with 1 Axes>

<Figure size 432x288 with 1 Axes>

<Figure size 432x288 with 1 Axes>
5.2.2 单张图片预测
采用model.predict_batch来进行单张或少量多张图片的预测。
In [52]
# 读取单张图片
image = eval_dataset[501][0]
# 单张图片预测
result = model.predict_batch([image])
# 可视化结果
show_img(image, np.argmax(result))
<Figure size 432x288 with 1 Axes>
⑥ 部署上线
6.1 保存模型
In [54]
# 保存用于后续继续调优训练的模型
model.save('finetuning/mnist')6.2 继续调优训练
In [56]
from paddle.static import InputSpec
# 模型封装,为了后面保存预测模型,这里传入了inputs参数
model_2 = paddle.Model(network, inputs=[InputSpec(shape=[-1, 28, 28], dtype='float32', name='image')])
# 加载之前保存的阶段训练模型
model_2.load('finetuning/mnist')
# 模型配置
model_2.prepare(paddle.optimizer.Adam(learning_rate=0.001, parameters=network.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
# 模型全流程训练
model_2.fit(train_dataset,
eval_dataset,
epochs=2,
batch_size=64,
verbose=1)The loss value printed in the log is the current step, and the metric is the average value of previous step. Epoch 1/2 step 938/938 [==============================] - loss: 0.0563 - acc: 0.9926 - 7ms/step Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 157/157 [==============================] - loss: 3.1640e-05 - acc: 0.9775 - 6ms/step Eval samples: 10000 Epoch 2/2 step 938/938 [==============================] - loss: 0.0018 - acc: 0.9935 - 7ms/step Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 157/157 [==============================] - loss: 8.6797e-06 - acc: 0.9783 - 6ms/step Eval samples: 10000
6.3 保存预测模型
In [58]
# 保存用于后续推理部署的模型
model_2.save('infer/mnist', training=False)















 2938
2938











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











