







1. 内存管理简介:
不同架构下的编址方式可能是不一样的:
- ARM中寄存器和内存统一编址
- X86中内存按地址编址,寄存器用端口号编址
对于包含 MMU 的处理器而言,Linux 系统提供了复杂的存储管理系统,使得进程所能访问的内存达到 4GB。
在 Linux 系统中,进程的 4GB 内存空间被分为两个部分:

一般情况,用户进程通常情况下只能访问用户空间的虚拟地址,不能访问内核空间虚拟地址。
每个进程的用户空间都是完全独立、互不相干的,用户进程各自有不同的页表。
内核空间是由内核负责映射,它并不会跟着进程改变,是固定的。
在 3~4GB 之间的内核空间中,从低地址到高地址依次为:
物理内存映射区—隔离带—vmalloc虚拟内存分配器 — 隔离带—高端内存映射区—专用页面映射区—保留区
2. 内存存取
2.1 用户空间内存的分配:
void *malloc(size_t nbytes); //返回指向nbytes个字节的指针
void *calloc(size_t cnt, size_t nbytes); //内容清0
void *realloc(void *ptr,size_t size); //改变当前分配的空间,参数size 是重新分配后的大小,一般是要变大
void free(void *ptr); //释放动态分配的内存空间2.2 内核空间内存的分配:
(1) kmalloc: – 分配小空间(32,128k)
函数原型:
static void *kmalloc(size_t size, gfp_t flags)参数:
size,分配空间的大小,范围 (32, 128k),单位是字节
flags,
#define GFP_ATOMIC (__GFP_HIGH) //非阻塞分配
#define GFP_KERNEL (__GFP_WAIT | __GPF_IO | __GFP_FS) //阻塞分配
释放函数是:kfree
(2) __get_free_page: –最小单位是 4k,最大能分配8M
函数原型:
unsigned long __get_free_page(int gfp_mask);
unsigned long __get_free_page(int gfp_mask, unsigned long order);注意点:
返回页首地址,不清 0 内容,分配的页数是2的order次,则分配的大小是还要乘4k,order最大是11,则最大能分配的空间是2k*4k = 8M
参数:
gfp_mask,
#define GFP_ATOMIC (__GFP_HIGH) //非阻塞分配
#define GFP_KERNEL (__GFP_WAIT | __GPF_IO | __GFP_FS) //阻塞分配
释放函数:
free_page
free_pages前两个分配的空间都是物理地址和虚拟地址连续的
(3) vmalloc: –可分配8M以上的空间,获得的地址是平台相关的,不能在中断时分配
函数原型:
void *vmalloc(unsigned long size)特点是:
- 物理地址不一定连续,
- 虚拟地址连续
释放函数:
void vfree(void * addr); (4) slab: – 分配特定结构的内存块
用合适的方法使得在对象前后两次被使用时分配在同一块内存或同一类内存空间且保留了基本的数据结构
创建 slab 缓存:
struct kmem_cache *kmem_cache_create(const char *name, size_t size,
size_t align, unsigned long flags,
void (*ctor)(void*, struct kmem_cache *, unsigned long),
void (*dtor)(void*, struct kmem_cache *, unsigned long)); 参数:
name,名字
size,每个数据结构的大小
align,
flags,如何进行分配的位掩码:
SLAB_NO_REAP,即使内存紧缺也不自动收缩这块缓存
SLAB_HWCACHE_ALIGN,每个数据对象被对齐到一个缓存行
SLAB_CACHE_DMA,要求数据对象在DMA内存区分配
ctor,
dtor,
分配 slab 缓存: – 在 kmem_cache_create()创建的 slab 后备缓冲中分配一块并返回首地址指针
void *kmem_cache_alloc(struct kmem_cache *cachep, gfp_t flags);释放 slab 缓存: – 释放由 kmem_cache_alloc()分配的缓存
void kmem_cache_free(struct kmem_cache *cachep, void *objp); 收回 slab 缓存:
int kmem_cache_destroy(struct kmem_cache *cachep); 使用模板:
/*创建 slab 缓存*/
static kmem_cache_t *xxx_cachep;
xxx_cachep = kmem_cache_create("xxx", sizeof(struct xxx),
0, SLAB_HWCACHE_ALIGN|SLAB_PANIC, NULL, NULL);
/*分配 slab 缓存*/
struct xxx *ctx;
ctx = kmem_cache_alloc(xxx_cachep, GFP_KERNEL);
.../* 使用 slab 缓存 */
/*释放 slab 缓存*/
kmem_cache_free(xxx_cachep, ctx);
kmem_cache_destroy(xxx_cachep); 在linux系统下可以通过 /proc/slabinfo 节点来获知当前 slab 的分配和使用情况。
(5) 内存池
创建内存池:
mempool_t *mempool_create(int min_nr, mempool_alloc_t *alloc_fn,
mempool_free_t *free_fn, void *pool_data); 参数:
min_nr,需要预分配对象的数目
alloc_fn 和 free_fn,指向内存池机制提供的标准对象分配和回收函数的指针
函数原型分别是
typedef void *(mempool_alloc_t)(int gfp_mask, void *pool_data);
typedef void (mempool_free_t)(void *element, void *pool_data);
pool_data 是分配和回收函数用到的指针,gfp_mask是分配标记。只有当_ _GFP_WAIT 标记被指定时,分配函数才会休眠。
分配和回收对象:
void *mempool_alloc(mempool_t *pool, int gfp_mask);
void mempool_free(void *element, mempool_t *pool); 回收内存池:
void mempool_destroy(mempool_t *pool);内存池和slab的区别:
slab中存放的是很多的固定结构的区域,而内存池中的空间没有固定格式
3. 设备对 “IO 端口” 和 “IO 内存” 的访问:
3.1 IO 端口:
端口(port)是接口电路中能被CPU直接访问的寄存器的地址。几乎每一种外设都是通过读写设备上的寄存器来进行的。CPU通过这些地址即端口向接口电 路中的寄存器发送命令,读取状态和传送数据。外设寄存器也称为“I/O端口”,通常包括:控制寄存器、状态寄存器和数据寄存器三大类,而且一个外设的寄存器通常被连续地编址。
使用 linux 内核提供的函数访问位于 I/O 空间的端口,这些函数包括如下几种:
inb,outb,inw,outw,inl,outl,insb,outsb,insw,outsw,insl,outsl
这里函数具体内容,没有给出来,需要的请查看别的文档。
对 IO 端口的申请和释放:
struct resource *request_region(unsigned long first, unsigned long n, const char *name);
void release_region(unsigned long start, unsigned long n);参数:
first,端口的开始
n,申请端口的数量
name,设备的名字
返回值:
NULL,申请失败
非NULL,事情成功
访问流程:
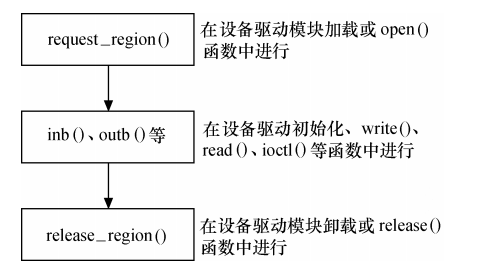
3.2 IO 内存:
在内核中访问 I/O 内存之前,需首先使用 ioremap()函数将设备所处的物理地址映射到虚拟地址。ioremap()的原型如下:
物理地址向虚拟地址映射:
①void *ioremap(unsigned long offset, unsigned long size); //映射
②void iounmap(void *addr); //取消映射函数①的参数:
offset,物理地址首地址
size,要映射的大小,单位是字节
返回值:
新的地址,成功后映射地址的首地址
NULL,失败
函数②的参数:
addr,映射后的地址
ioremap()与 vmalloc()类似,也需要建立新的页表,但是它并不进行 vmalloc()中所执行的内存分配行为
对虚拟地址的读写用如下函数:
古老的方式{
readb /readl/readw
writeb/writel/writew
1个字节 4个字节 2个字节
data =readb(val)
writeb(data,val)
使用模板:
获得寄存器的物理地址
#define GPX2CON 0x11000c40
unsigned int * gpx2con;
gpx2con = ioremap(GPX2CON,4);
设置GPX2_7为输出功能
*gpx2con = *gpx2con &(~(0xf<<28)) | 0x1<<28;
使用完成后,释放寄存器映射
iounmap(gpx2con);
unsigned int temp;
temp = readl(gpx2con); --- 读
temp = temp &(~(0xf<<28)) | 0x1<<28 ; -- 改
writel(temp,gpx2con); --- 写
三合一:
writel(readl(gpx2con) & (~(0xf<<28)) | 0x1<<28 ,gpx2con);
多映射的例子:
#define GPX2BASE 0x11000c40
unsigned int * gpx2base;
gpx2base = ioremap(GPX2BASE, 4*2);
GPX2CON寄存器的虚拟地址:*(gpx2base + 0)
GPX2DAT寄存器的虚拟地址:*(gpx2base + 1)
}
新的方式:
unsigned int ioread8(void *addr); /* 读一字节 */
unsigned int ioread16(void *addr); /* 读两字节 */
unsigned int ioread32(void *addr);
void iowrite8(u8 value, void *addr);
void iowrite16(u16 value, void *addr);
void iowrite32(u32 value, void *addr);
void ioread8_rep(void *addr, void *buf, unsigned long count); /* 读一串字节 */
void ioread16_rep(void *addr, void *buf, unsigned long count);
void ioread32_rep(void *addr, void *buf, unsigned long count);
void iowrite8_rep(void *addr, const void *buf, unsigned long count);
void iowrite16_rep(void *addr, const void *buf, unsigned long count);
void iowrite32_rep(void *addr, const void *buf, unsigned long count);
void memcpy_fromio(void *dest, void *source, unsigned int count); /* 从 io 复制 */
void memcpy_toio(void *dest, void *source, unsigned int count); /* 复制到 io */
void memset_io(void *addr, u8 value, unsigned int count); /* 设置 io 内存 */IO 内存申请:
struct resource *request_mem_region(unsigned long start, unsigned long len, char *name);
void release_mem_region(unsigned long start, unsigned long len);参数:
start,开始的地址
len,内存的数量
name,设备的名称
返回值:
NULL,失败
非NULL,成功
访问流程:
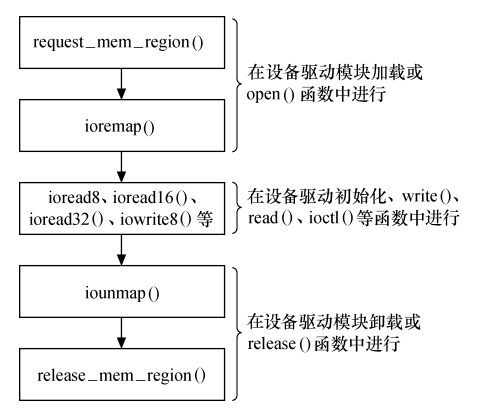
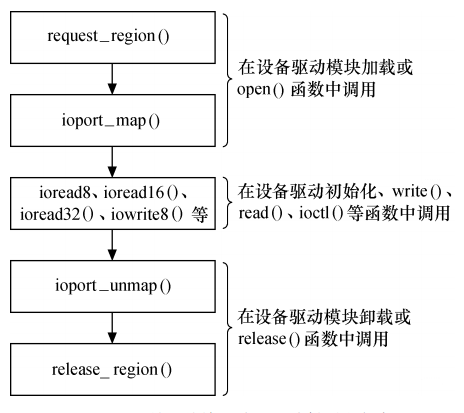
3.3 将 IO 端口复制到内存空间:
void *ioport_map(unsigned long port, unsigned int count);
void ioport_unmap(void *addr);将 port 开始的 count 个连续的 io 端口重映射为一段 “内存空间”,映射到内存空间行为实际上是给开发人员制造的一个“假象”,并没有映射到内核虚拟地址,仅仅是为了让工程师可使用统一的 I/O 内存访问接口访问 I/O 端口。
4. 将设备地址映射到用户空间
一般情况下,用户空间是不可能也不应该直接访问设备的,但是对于显示、视频等设备,建立映射可减少用户空间和内核空间之间的内存拷贝。
… 此部分有待完善















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









