







 本文档详细介绍了如何在Caffe框架下利用自己的数据集进行训练和测试。首先,准备数据,包括创建数据目录、制作train.txt和val.txt文件、调整图片尺寸。接着,计算图像均值,并修改prototxt文件以适应自定义数据。然后,配置并运行训练脚本,调整学习率、测试间隔等参数以适应小规模数据。最后,进行模型训练,记录训练过程中的准确率,并展示了恢复训练的步骤。
本文档详细介绍了如何在Caffe框架下利用自己的数据集进行训练和测试。首先,准备数据,包括创建数据目录、制作train.txt和val.txt文件、调整图片尺寸。接着,计算图像均值,并修改prototxt文件以适应自定义数据。然后,配置并运行训练脚本,调整学习率、测试间隔等参数以适应小规模数据。最后,进行模型训练,记录训练过程中的准确率,并展示了恢复训练的步骤。
在caffe提供的例程当中,例如mnist与cifar10中,数据集的准备均是通过调用代码自己完成的,而对于ImageNet1000类的数据库,对于高校实验室而言,常常面临电脑内存不足的尴尬境地。而对于应用者而言,用适合于自己条件的的数据集在caffe下训练及测试才是更重要的。所以我们有必要自己做数据库以及在caffe上训练及测试。
1,数据准备
在data中新建文件夹myself,我们截取了ImageNet1000类中的两类—panda与sea_horse,训练panda的图片24张,测试panda的图片6张,训练sea_horse的图片38张,测试sea_horse的图片7张。如图所示:
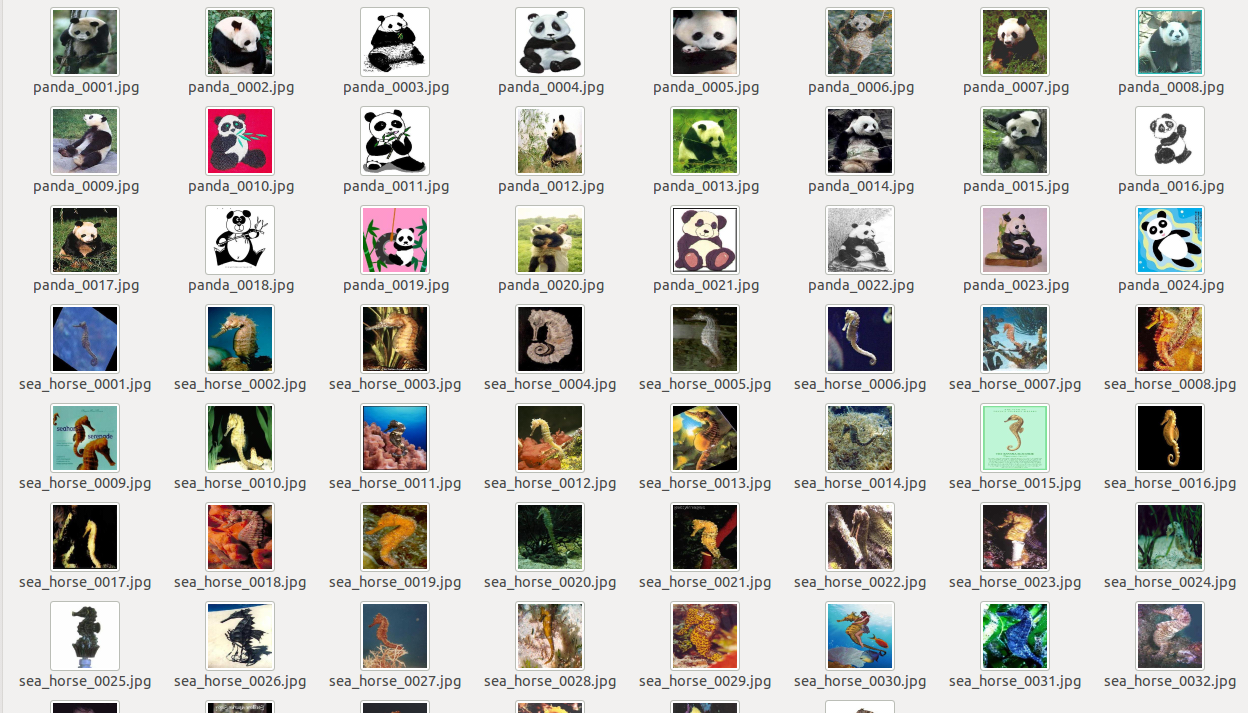
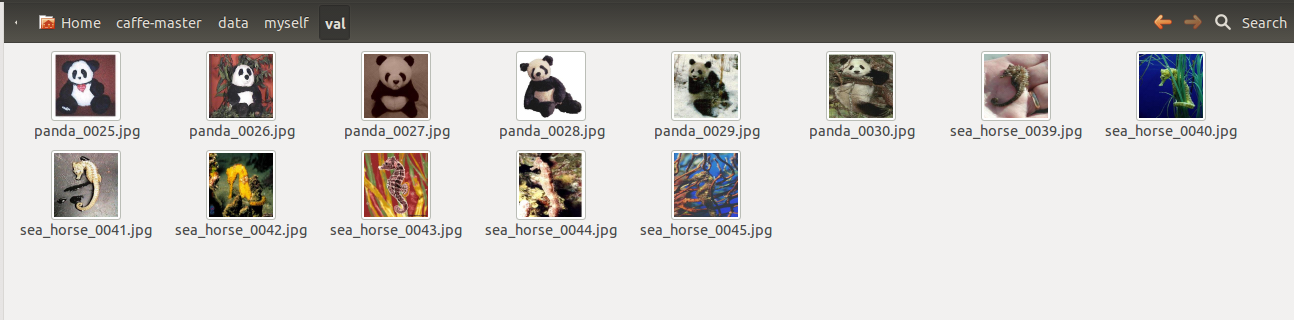
培训和测试的输入是用train.txt和val.txt描述的,这些文档列出所有文件和他们的标签。注意,在imagenet1000类中,我们分类的名字是ASCII码的顺序,即0-999,对应的分类名和数字的映射在synset_words.txt(自己写)中。
运行以下指令:
find -name *.jpeg |cut -d '/' -f2-3> train.txt注意路径
然后,因为自己的数据库样本数比较少,可以自行手动做分类标签。在train.txt的每个照片后用1-2分类。如图:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8239
8239

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









