







 Share memory在CUDA并行计算中起着关键作用,但bank conflict会影响性能。银行冲突发生在同一bank中有多个请求时。文章通过例子解释了bank冲突的原因,提出了解决方案,包括调整数据布局和矩阵转置,以优化共享内存的使用,避免bank冲突。在capability 1.x中,每个bank对应4-byte地址的模16,而在2.x和3.x中,bank数量增加到32个。
Share memory在CUDA并行计算中起着关键作用,但bank conflict会影响性能。银行冲突发生在同一bank中有多个请求时。文章通过例子解释了bank冲突的原因,提出了解决方案,包括调整数据布局和矩阵转置,以优化共享内存的使用,避免bank冲突。在capability 1.x中,每个bank对应4-byte地址的模16,而在2.x和3.x中,bank数量增加到32个。
Share memory是片上资源,生命周期是整个block中,它的数据读写十分快,有1个cycle latency。在Share memory中,经常存在bank conflict问题,如果没有bank conflict问题,它的数据读写可以和片上的寄存器(Register)一样快。因此,我们需要尽量减少bank conflicts.
首先,什么是bank?我们以capability 1.x为例,Share memory被等分成同等尺寸大小的存储器模式,即banks,以下图为例:
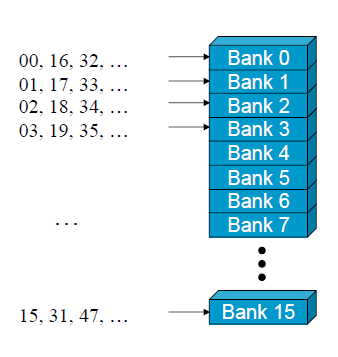
每一个bank的带宽为32-bit,即4 bytes。连续的32-bit字节可以被分到连续的bank中去。我们以G80为例,它具有16个banks,所以每一个bank=4-byte address % 16,此外,bank的数量和半个warp的thread数量一致,所以share memory对一个warp的请求,分成了两个先后请求来做,不同的半个warp之间没有bank conflicts。如果同时有两个请求在同一个bank中,就会出现bank conflicts,如下图:
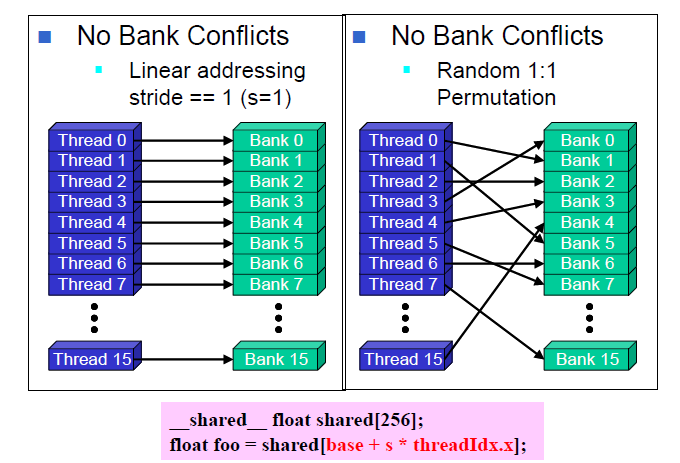
对于share memory,有数据读写有快慢两种情况:
快:1)半个warp的所有threads在同一时刻读写share memory的不同bank。2)半个warp中的所有threads在同一时刻以广播的形式读写share memory中的同一个bank。
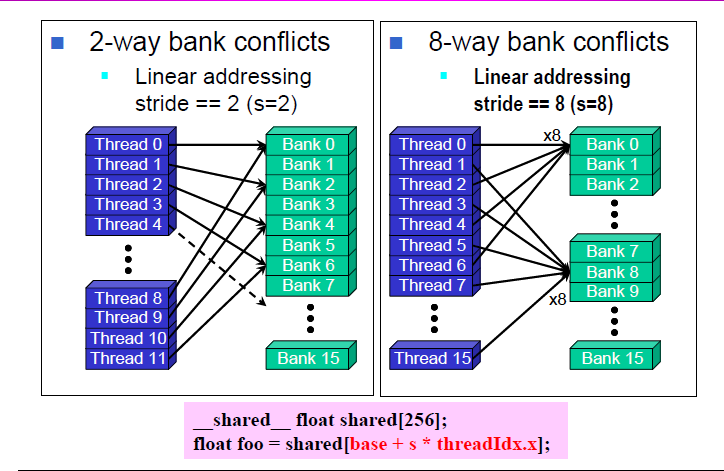
慢:半个warp的所有threads在同一时刻读写share memory的多个bank(不是全部),这时必须串行读写。
以G80为例,其share memory具有16个bank,在下面的图示中,只有S为奇数时,才不会存在bank conflicts。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9699
9699

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









