







该工具通过在计算机上运行音频识别模型,对连续不断的采样流,创建准确度统计信息。
这是一个新的模型运行环境设置以,了解它们在实际应用中的效果。
你需要为它提供一个包含你想要识别的声音的长音频文件,还有一个文本文件,列出每个声音的标签以及它们出现的时间。有了这些信息和冻结的模型,该工具将处理音频流式处理,应用模型,并记录有多少错误和成功模型实现。
匹配百分比是正确分类的声音数量,占列出的声音总数的百分比。
正确的分类是在短时间内选择正确的标签预期,其中时间容差由“time_tolerance_ms”命令行标志。
相同样品的文件,根据你的模型评分(通常每秒16000个样本),并记下声音会及时出现。将此信息保存为逗号分隔的文本文件,其中第一列是标签,第二列是从发生该事件的文件的开头。
运行这个例子的示例:
bazel run tensorflow/examples/speech_commands:test_streaming_accuracy -- \
--wav=/tmp/streaming_test_bg.wav \
--graph=/tmp/conv_frozen.pb \
--labels=/tmp/speech_commands_train/conv_labels.txt \
--ground_truth=/tmp/streaming_test_labels.txt --verbose \
--clip_duration_ms=1000 --detection_threshold=0.70 --average_window_ms=500 \
--suppression_ms=500 --time_tolerance_ms=1500
函数流程图如下:
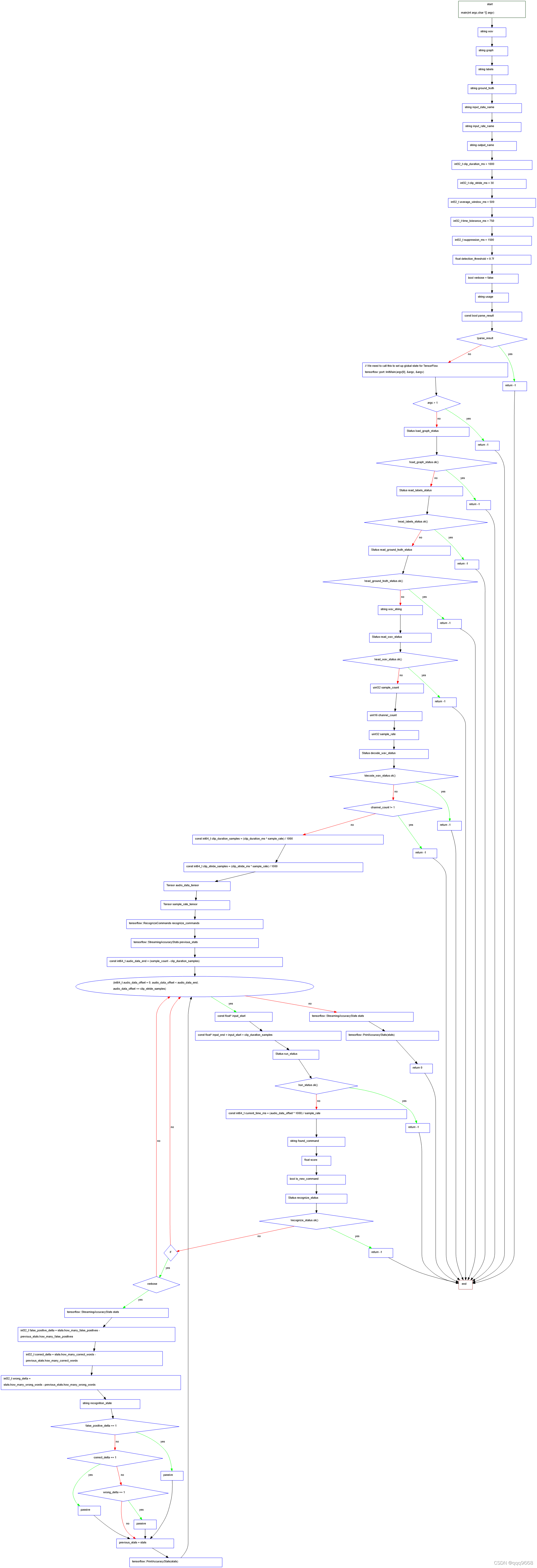
函数逻辑顺序图如下:
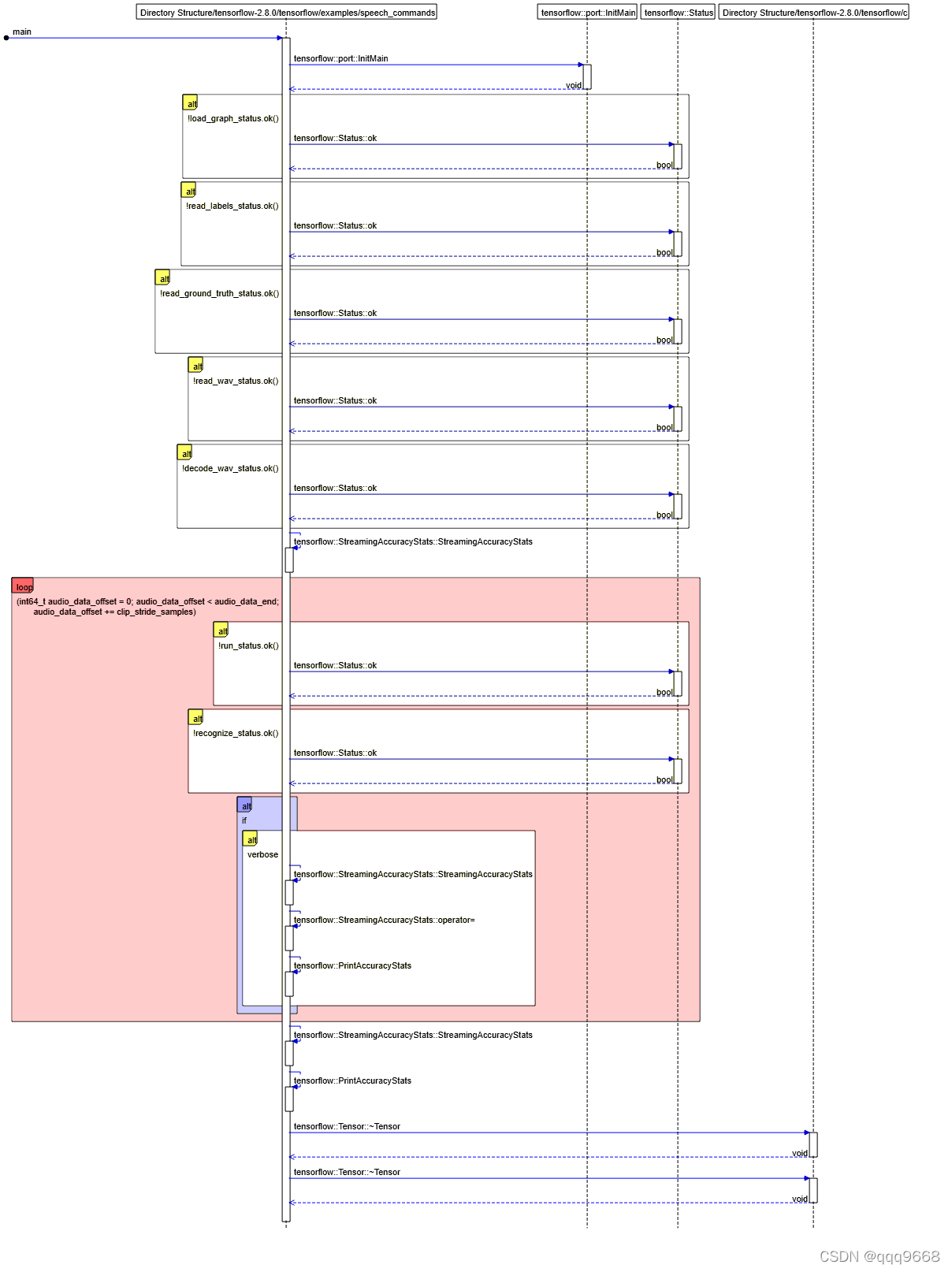
函数原始代码如下:
int main(int argc, char* argv[]) {
string wav = "";
string graph = "";
string labels = "";
string ground_truth = "";
string input_data_name = "decoded_sample_data:0";
string input_rate_name = "decoded_sample_data:1";
string output_name = "labels_softmax";
int32_t clip_duration_ms = 1000;
int32_t clip_stride_ms = 30;
int32_t average_window_ms = 500;
int32_t time_tolerance_ms = 750;
int32_t suppression_ms = 1500;
float detection_threshold = 0.7f;
bool verbose = false;
std::vector<Flag> flag_list = {
Flag("wav", &wav, "audio file to be identified"),
Flag("graph", &graph, "model to be executed"),
Flag("labels", &labels, "path to file containing labels"),
Flag("ground_truth", &ground_truth,
"path to file containing correct times and labels of words in the "
"audio as <word>,<timestamp in ms> lines"),
Flag("input_data_name", &input_data_name,
"name of input data node in model"),
Flag("input_rate_name", &input_rate_name,
"name of input sample rate node in model"),
Flag("output_name", &output_name, "name of output node in model"),
Flag("clip_duration_ms", &clip_duration_ms,
"length of recognition window"),
Flag("average_window_ms", &average_window_ms,
"length of window to smooth results over"),
Flag("time_tolerance_ms", &time_tolerance_ms,
"maximum gap allowed between a recognition and ground truth"),
Flag("suppression_ms", &suppression_ms,
"how long to ignore others for after a recognition"),
Flag("clip_stride_ms", &clip_stride_ms, "how often to run recognition"),
Flag("detection_threshold", &detection_threshold,
"what score is required to trigger detection of a word"),
Flag("verbose", &verbose, "whether to log extra debugging information"),
};
string usage = tensorflow::Flags::Usage(argv[0], flag_list);
const bool parse_result = tensorflow::Flags::Parse(&argc, argv, flag_list);
if (!parse_result) {
LOG(ERROR) << usage;
return -1;
}
// We need to call this to set up global state for TensorFlow.设置TensorFlow的全局状态
tensorflow::port::InitMain(argv[0], &argc, &argv);
if (argc > 1) {
LOG(ERROR) << "Unknown argument " << argv[1] << "\n" << usage;
return -1;
}
// First we load and initialize the model.第一:装载模型并初始化模型
std::unique_ptr<tensorflow::Session> session;
Status load_graph_status = LoadGraph(graph, &session);
if (!load_graph_status.ok()) {
LOG(ERROR) << load_graph_status;
return -1;
}
std::vector<string> labels_list;
Status read_labels_status = ReadLabelsFile(labels, &labels_list);
if (!read_labels_status.ok()) {
LOG(ERROR) << read_labels_status;
return -1;
}
std::vector<std::pair<string, int64_t>> ground_truth_list;
Status read_ground_truth_status =
tensorflow::ReadGroundTruthFile(ground_truth, &ground_truth_list);
if (!read_ground_truth_status.ok()) {
LOG(ERROR) << read_ground_truth_status;
return -1;
}
string wav_string;
Status read_wav_status = tensorflow::ReadFileToString(
tensorflow::Env::Default(), wav, &wav_string);
if (!read_wav_status.ok()) {
LOG(ERROR) << read_wav_status;
return -1;
}
std::vector<float> audio_data;
uint32 sample_count;
uint16 channel_count;
uint32 sample_rate;
Status decode_wav_status = tensorflow::wav::DecodeLin16WaveAsFloatVector(
wav_string, &audio_data, &sample_count, &channel_count, &sample_rate);
if (!decode_wav_status.ok()) {
LOG(ERROR) << decode_wav_status;
return -1;
}
if (channel_count != 1) {
LOG(ERROR) << "Only mono .wav files can be used, but input has "
<< channel_count << " channels.";
return -1;
}
const int64_t clip_duration_samples = (clip_duration_ms * sample_rate) / 1000;
const int64_t clip_stride_samples = (clip_stride_ms * sample_rate) / 1000;
Tensor audio_data_tensor(tensorflow::DT_FLOAT,
tensorflow::TensorShape({clip_duration_samples, 1}));
Tensor sample_rate_tensor(tensorflow::DT_INT32, tensorflow::TensorShape({}));
sample_rate_tensor.scalar<int32>()() = sample_rate;
tensorflow::RecognizeCommands recognize_commands(
labels_list, average_window_ms, detection_threshold, suppression_ms);
std::vector<std::pair<string, int64_t>> all_found_words;
tensorflow::StreamingAccuracyStats previous_stats;
const int64_t audio_data_end = (sample_count - clip_duration_samples);
for (int64_t audio_data_offset = 0; audio_data_offset < audio_data_end;
audio_data_offset += clip_stride_samples) {
const float* input_start = &(audio_data[audio_data_offset]);
const float* input_end = input_start + clip_duration_samples;
std::copy(input_start, input_end, audio_data_tensor.flat<float>().data());
// Actually run the audio through the model.
std::vector<Tensor> outputs;
Status run_status = session->Run({{input_data_name, audio_data_tensor},
{input_rate_name, sample_rate_tensor}},
{output_name}, {}, &outputs);
if (!run_status.ok()) {
LOG(ERROR) << "Running model failed: " << run_status;
return -1;
}
const int64_t current_time_ms = (audio_data_offset * 1000) / sample_rate;
string found_command;
float score;
bool is_new_command;
Status recognize_status = recognize_commands.ProcessLatestResults(
outputs[0], current_time_ms, &found_command, &score, &is_new_command);
if (!recognize_status.ok()) {
LOG(ERROR) << "Recognition processing failed: " << recognize_status;
return -1;
}
if (is_new_command && (found_command != "_silence_")) {
all_found_words.push_back({found_command, current_time_ms});
if (verbose) {
tensorflow::StreamingAccuracyStats stats;
tensorflow::CalculateAccuracyStats(ground_truth_list, all_found_words,
current_time_ms, time_tolerance_ms,
&stats);
int32_t false_positive_delta = stats.how_many_false_positives -
previous_stats.how_many_false_positives;
int32_t correct_delta = stats.how_many_correct_words -
previous_stats.how_many_correct_words;
int32_t wrong_delta =
stats.how_many_wrong_words - previous_stats.how_many_wrong_words;
string recognition_state;
if (false_positive_delta == 1) {
recognition_state = " (False Positive)";
} else if (correct_delta == 1) {
recognition_state = " (Correct)";
} else if (wrong_delta == 1) {
recognition_state = " (Wrong)";
} else {
LOG(ERROR) << "Unexpected state in statistics";
}
LOG(INFO) << current_time_ms << "ms: " << found_command << ": " << score
<< recognition_state;
previous_stats = stats;
tensorflow::PrintAccuracyStats(stats);
}
}
}
tensorflow::StreamingAccuracyStats stats;
tensorflow::CalculateAccuracyStats(ground_truth_list, all_found_words, -1,
time_tolerance_ms, &stats);
tensorflow::PrintAccuracyStats(stats);
return 0;
}
















 2064
2064











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











