







1. 问题介绍
在进行impala性能测试的过程中,从测试结果发现impala的并发性能非常差。
1.1 环境信息
测试的环境配置如下:
服务器内存:250G ;
CPU : 2个CPU,每cpu 6个物理核,逻辑核数24 ;
带宽:万兆网口
节点个数:3
数据:TPC-DS生成的100G数据集,把数据导入parquet格式的hive表中。
1.2 查询SQL
select ss_quantity, ss_list_price, ss_coupon_amt, ss_sales_price, ss_wholesale_cost, ss_ext_list_price
from store_sales
where ss_sold_date_sk > 20 and (ss_item_sk between 10 and 5000)
and ((ss_cdemo_sk between 100 and 3000 or ss_store_sk between 10 and 3000))
and (ss_addr_sk > 100 or ss_promo_sk < 3000)
limit 100
1.3 测试结果
并发测试结果如下:
并发度: 4 6 8 10 15 20
平均耗时(ms):2305 3435 4694 5868 8803 11679
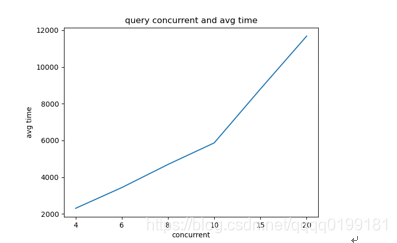
从测试结果看,查询的平均耗时随着测试的并发度增加呈现线性的上升,4并发下平均耗时仅需2秒的查询在20并发下竟然需要11秒。这样的性能并不符合预期。
2. 问题分析
为了查明高并发场景下简单的过滤查询耗时变慢的原因。我们列出如下排查方向。
1、 监控服务器资源,观察是否资源不足导致的
2、 如果资源充足,分析查询的profile信息,分析任务执行的各个阶段耗时,找出耗时明显较长的阶段,进一步深入分析。
2.1 服务器资源查看
通过先知平台,监控测试运行时的资源情况。
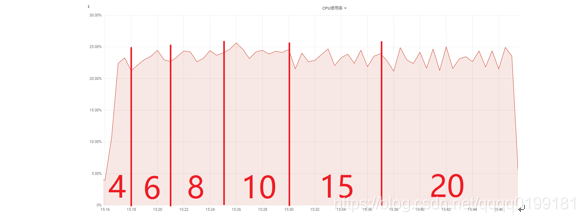
CPU:
随着并发度增加CPU使用率较为稳定,平均使用率约24%。
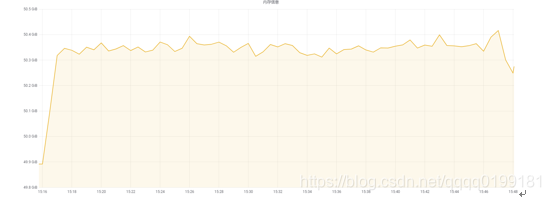
内存:
起始内存约为50GB,随着并发数的增加,内存占用较为稳定,占用约为400M。
磁盘和网络IO也消耗很少。从以上监控结果可以得出结论,系统的cpu、内存、磁盘IO、网络IO都非常充足,因此排除资源不足的因素。
2.2 Profile 分析
打开impalad的web页面,选择queries导航栏,打开queries页面,这个页面上有impala上正在执行和执行完成的查询信息。
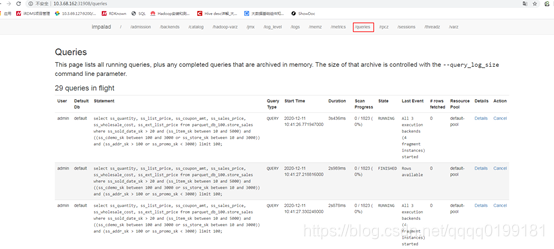
在页面下方的 Last 25 Completed Queries 中可以看到最近的25条执行完成的查询。找出你要分析的查询,选择Detail
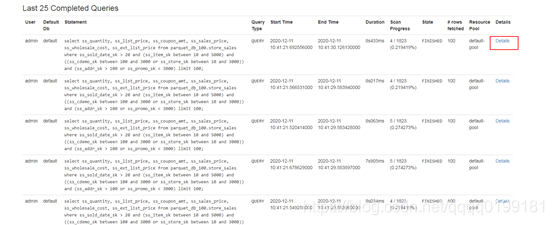
打开Detail页面后,选择profile选项,就可以看到查询各个阶段耗时的分析了
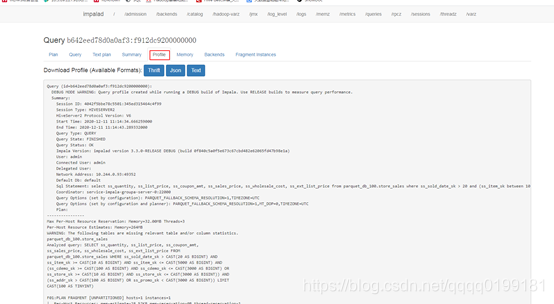
在本案例中,截取的profile关键信息如下:
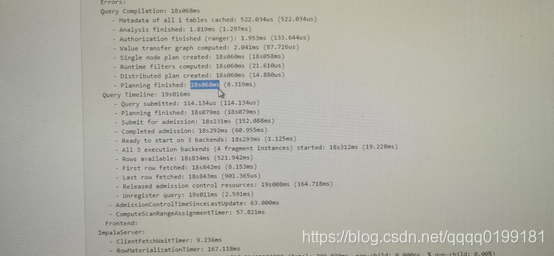
有上图可以看出,sql的执行时间为19s016ms,其中Single node Plan created 的耗时就需要18s05ms。由此可见,生成单节点计划步骤是查询性能降低的罪魁祸首,并且查询的并发度越高,生成单节点计划消耗的时间越长。那么为什么会出现这种现象呢?导致这种现象的根本原因又是什么呢?
2.3 Arthas分析
从impala的源码中可以找到,生成单节点计划的代码如下:
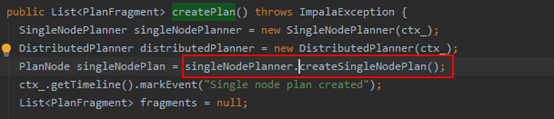
可见impala的执行计划生成的代码位于fe部分,由java代码实现。既然是java实现的,就可以使用诊断神器Arthas去做进一步分析。
在arthas安装目录下启动arthas
java -jar arthas-boot.jar
选择impala进程attach
首先查看线程的情况,执行thread命令
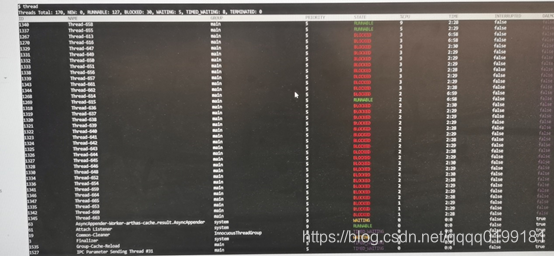
可以发现此时impala进程中有许多线程处于阻塞状态。
使用thread 1331 查看其中一个阻塞线程的调用栈,打印如下信息:
"Thread-649" Id=1331 BLOCKED on org.apache.hadoop.conf.Configuration@3a2996ef owned by "Thread-616" Id=1270
at app//org.apache.hadoop.conf.Configuration.getOverlay(Configuration.java:1424)
- blocked on org.apache.hadoop.conf.Configuration@3a2996ef
at app//org.apache.hadoop.conf.Configuration.handleDeprecation(Configuration.java:706)
at app//org.apache.hadoop.conf.Configuration.get(Configuration.java:1183)
at app//org.apache.hadoop.conf.Configuration.getTimeDuration(Configuration.java:1774)
at app//org.apache.hadoop.hdfs.client.impl.DfsClientConf.<init>(DfsClientConf.java:248)
at app//org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:301)
at app//org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:285)
at app//org.apache.hadoop.hdfs.DistributedFileSystem.initialize(DistributedFileSystem.java:168)
at app//org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:3237)
at app//org.apache.hadoop.fs.FileSystem.get(FileSystem.java:475)
at app//org.apache.hadoop.fs.Path.getFileSystem(Path.java:361)
at app//org.apache.impala.planner.HdfsScanNode.computeScanRangeLocations(HdfsScanNode.java:893)
at app//org.apache.impala.planner.HdfsScanNode.init(HdfsScanNode.java:413)
at app//org.apache.impala.planner.SingleNodePlanner.createHdfsScanPlan(SingleNodePlanner.java:1335)
at app//org.apache.impala.planner.SingleNodePlanner.createScanNode(SingleNodePlanner.java:1395)
at app//org.apache.impala.planner.SingleNodePlanner.createTableRefNode(SingleNodePlanner.java:1582)
at app//org.apache.impala.planner.SingleNodePlanner.createTableRefsPlan(SingleNodePlanner.java:826)
at app//org.apache.impala.planner.SingleNodePlanner.createSelectPlan(SingleNodePlanner.java:662)
at app//org.apache.impala.planner.SingleNodePlanner.createQueryPlan(SingleNodePlanner.java:261)
at app//org.apache.impala.planner.SingleNodePlanner.createSingleNodePlan(SingleNodePlanner.java:151)
at app//org.apache.impala.planner.Planner.createPlan(Planner.java:117)
at app//org.apache.impala.service.Frontend.createExecRequest(Frontend.java:1169)
at app//org.apache.impala.service.Frontend.getPlannedExecRequest(Frontend.java:1495)
at app//org.apache.impala.service.Frontend.doCreateExecRequest(Frontend.java:1359)
at app//org.apache.impala.service.Frontend.getTExecRequest(Frontend.java:1250)
at app//org.apache.impala.service.Frontend.createExecRequest(Frontend.java:1220)
at app//org.apache.impala.service.JniFrontend.createExecRequest(JniFrontend.java:154)
从标红行可以判断,线程阻塞的位置就是发生在生成单节点计划处,即SingleNodePlanner.createScanNode。而最终阻塞的位置是Configuration.getOverlay。这是调用了hadoop jar包的方法,该方法的代码如下:
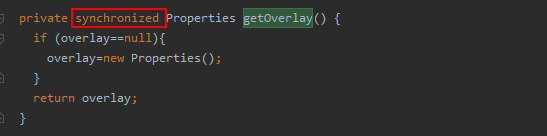
这是个同步方法,也就是代表多线程的情况下会存在资源竞争,这就导致了线程阻塞的问题。
3. 问题解决
那么为什么会有多线程调用这个方法呢?从上面的调用栈可以看出,创建单节点计划的过程中会创建FileSystem,创建FileSystem的方法如下:
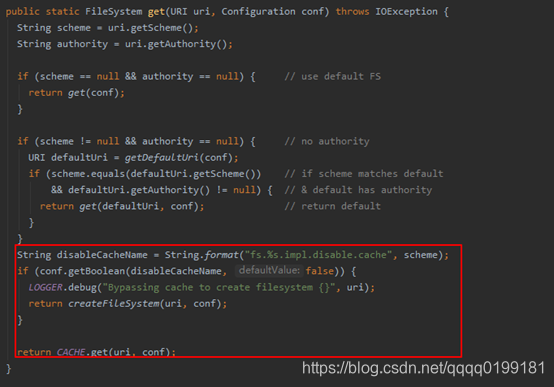
以上代码显示如果fs.hdfs.impl.disable.cache 为 true,每次impala查询就会调用createFileSystem(uri, conf)去初始化hdfs客户端,最终调用getOverlay方法,这就导致了多并发场景下线程的阻塞。如果fs.hdfs.impl.disable.cache 为 false,就可以获取缓存,这样就避免了阻塞的问题。因此只要将hdfs-site.xml中的fs.hdfs.impl.disable.cache配置项改为false,就可以解决问题。
4. 效果验证
修改fs.hdfs.impl.disable.cache配置为false后,在并发查询场景下,用arthas监控没有发现线程阻塞的问题。且,原来100并发平均耗时20s, 现在平均耗时4s,查询的并发性能大幅度提升。














 815
815











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









