







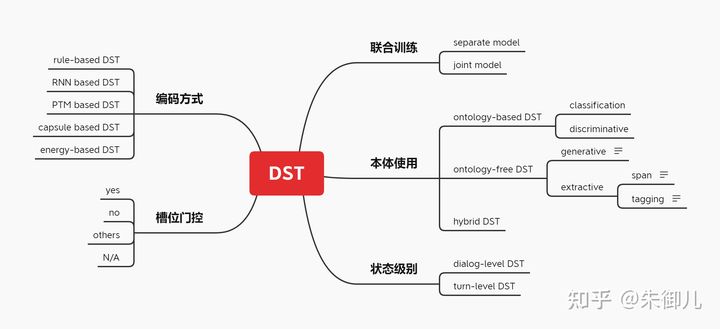
Open Vocabulary-based DST 基于开放词表的状态解码器直接从对话中找出或者生成槽值
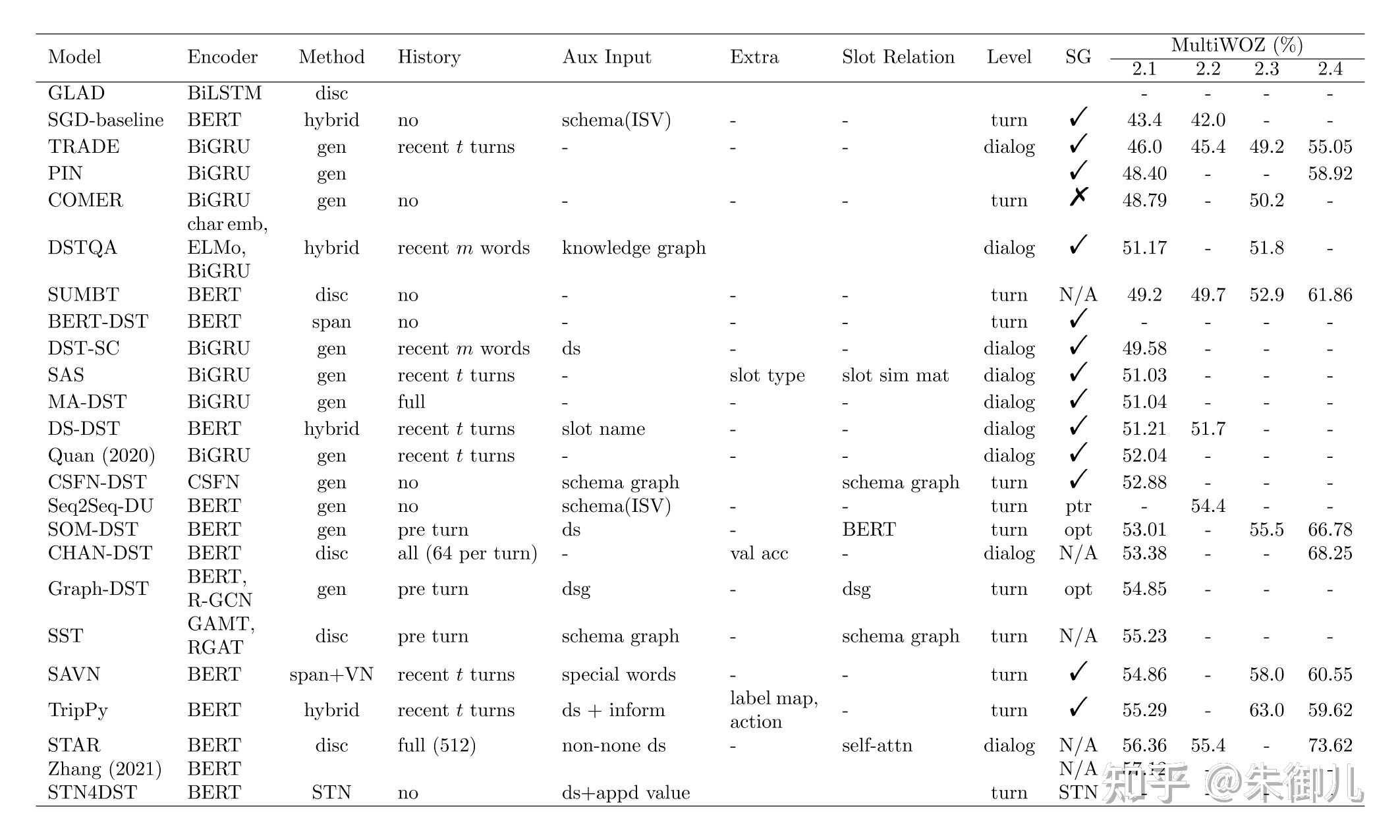
运行在MultiWOZ 2上的Open Vocabulary-based DST模型,包括TRADE、DSTreader、COMER、NADST、ML-BST等等
一般思想是运行autoregressive generation算法来生成槽值。
TRADE模型体现了encoder-decoder framework的潜力,但在计算上效率不高,因为它在每一turn为全部slots生成values。
COMER模型通过使用hierarchical decoder,一定上解决了TRADE的上述缺陷。hierarchical decoder,层次堆叠的解码器,以分层的方法解码domains, slots, and values,把当前轮对话状态本身生成为target sequence。此外,它们第一次提出了ICT的概念,以衡量不同DST模型对话状态预测的efficiency。COMER同样在slot values子集上生成,但是由于没有利用上一轮的对话状态信息,所以性能还是不如我们的模型。
DSTreader将DST建模为阅读理解任务,提出了DST Reader模型,从输入中提取槽值。 由于DST需要跟踪abstractive values as well as extractive ones,因此它们的完全提取方法受到限制。 在DST中加入一个槽位携带模块(slot carryover module),对是否将槽位的值从先前的对话状态转移到当前的对话状态做出二值决定,这个概念很重要。也相当于加入是否update的判断。
DS-DST企图结合使用Open Vocabulary和fixed Vocabulary,结果却依然在fixed-vocabulary based DST上转圈圈。
NADST和ML-BST的模型比较有争议,这里略过。
span 抽取式 DST
基于文本跨度(text span)的解码器,通过在对话历史文本中选取子序列的方式,直接从对话历史中抽取槽值。
- 将对话文本序列 看作一段篇章(passage),针对每一个槽位 ,构建一个问题(question)去询问当前对话中的某一个槽位的槽值是什么,如“what is the value for slot i?”;
- 若状态操作类型为 ,则从对话中选取子序列的开始位置和结束位置,得到的子序列即为槽值。
混合方法
使用两种状态解码器分别处理可枚举槽位和不可枚举槽位。DSTC8,平安人寿

















 973
973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









