







作者关联信息
1. 任务说明
学习主题:作者关联(数据建模任务),对论文作者关系进行建模,统计最常出现的作者关系;
学习内容:构建作者关系图,挖掘作者关系
学习成果:论文作者知识图谱、图关系挖掘
2. 分析任务
统计作者关系(使用图或其他网络形式建立他们之间的关系)
把相同类别的事物放到一起(有一种聚类的意思)
2.1 图的相关知识
接下来我们将通过以下几点进行认识:
- 什么叫图?
- 图的要素
- 图的表示
2.1.1 什么叫图?
在汉语中,图是用绘画表现出来的形象;在计算机中,图是用节点和边绘制的形状。
2.1.2 图的两个要素: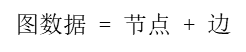
2.1.3 图的表示
图的分类:
- 有向图
- 无向图
图的表示方法:

【https://www.cnblogs.com/liushang0419/archive/2011/05/06/2039386.html】
2.2 图数据 和 知识图谱
图数据:简单的说,就是由一些结点和边构成的关联数据结构,即G(E,V),其中E是边的集合,V是点的集合;
知识图谱:简单的说,就是存在语义关联的图数据,即G(E,V),其中E表示语义关系的集合,V是实体的集合;
3. 数据处理
将作者列表进行处理,并完成统计。具体步骤如下:
将论文第一作者与其他作者(论文非第一作者)构建图;
使用图算法统计图中作者与其他作者的联系;
4. 社交网络分析
4.1 读取数据
# 导入所需的package
import seaborn as sns #用于画图
from bs4 import BeautifulSoup #用于爬取arxiv的数据
import re #用于正则表达式,匹配字符串的模式
import requests #用于网络连接,发送网络请求,使用域名获取对应信息
import json #读取数据,我们的数据为json格式的
import pandas as pd #数据处理,数据分析
import matplotlib.pyplot as plt #画图工具
def readArxivFile(path, columns=['id', 'submitter', 'authors', 'title', 'comments', 'journal-ref', 'doi',
'report-no', 'categories', 'license', 'abstract', 'versions',
'update_date', 'authors_parsed'], count=None):
'''
定义读取文件的函数
path: 文件路径
columns: 需要选择的列
count: 读取行数
'''
data = []
with open(path, 'r') as f:
for idx, line in enumerate(f):
if idx == count:
break
d = json.loads(line)
d = {col : d[col] for col in columns}
data.append(d)
data = pd.DataFrame(data)
return data
data = readArxivFile('arxiv-metadata-oai-2019.json',
['id', 'authors_parsed'],
200000)
4.2 创建无向图
import networkx as nx
# 创建无向图
G = nx.Graph()
# 只用五篇论文进行构建
for row in data.iloc[:500].itertuples():
authors = row[2]
authors = [' '.join(x[:-1]) for x in authors]
# 第一个作者 与 其他作者链接
for author in authors[1:]:
G.add_edge(authors[0],author) # 添加节点2,3并链接23节点
理解代码:
- itertuples(): 将DataFrame迭代为元组。【Python函数之iterrows(), iteritems(), itertuples()对dataframe进行遍历】
- add_edge = 添加边缘 = 添加边
数据分析学习笔记(三)-NetworkX的使用
# 将作者关系图进行绘制:
nx.draw(G, with_labels=True)
try:
print(nx.dijkstra_path(G, 'Balázs C.', 'Ziambaras Eleni'))
except:
print('No path')
如果我们500片论文构建图,则可以得到更加完整作者关系,并选择最大联通子图进行绘制,折线图为子图节点度值。
degree_sequence = sorted([d for n, d in G.degree()], reverse=True)
dmax = max(degree_sequence)
plt.loglog(degree_sequence, "b-", marker="o")
plt.title("Degree rank plot")
plt.ylabel("degree")
plt.xlabel("rank")
# draw graph in inset
plt.axes([0.45, 0.45, 0.45, 0.45])
Gcc = G.subgraph(sorted(nx.connected_components(G), key=len, reverse=True)[0])
pos = nx.spring_layout(Gcc)
plt.axis("off")
nx.draw_networkx_nodes(Gcc, pos, node_size=20)
nx.draw_networkx_edges(Gcc, pos, alpha=0.4)
plt.show()















 260
260











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









