







内容来自Andrew老师课程Machine Learning的第一章内容的Model and Cost Function部分。
一、Model Representation(模型表示)
1、简单术语
m
m
:训练样本的数目
:输入变量/特征
y
y
:输出变量/目标变量
:表示训练集的第i行
2、举例:

3、学习算法的工作
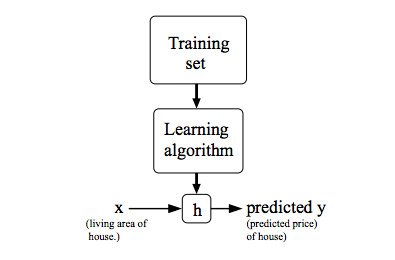
h表示hypothesis(假设)
4、线性回归拟合曲线
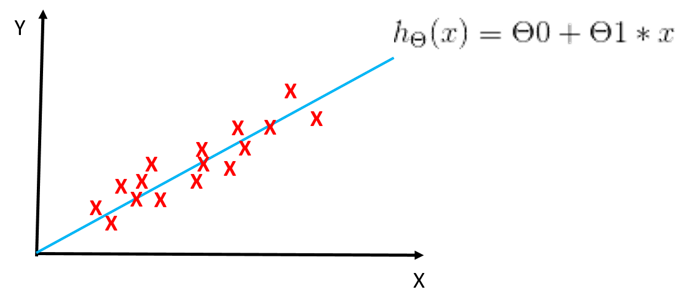
二、Cost Function(代价函数)
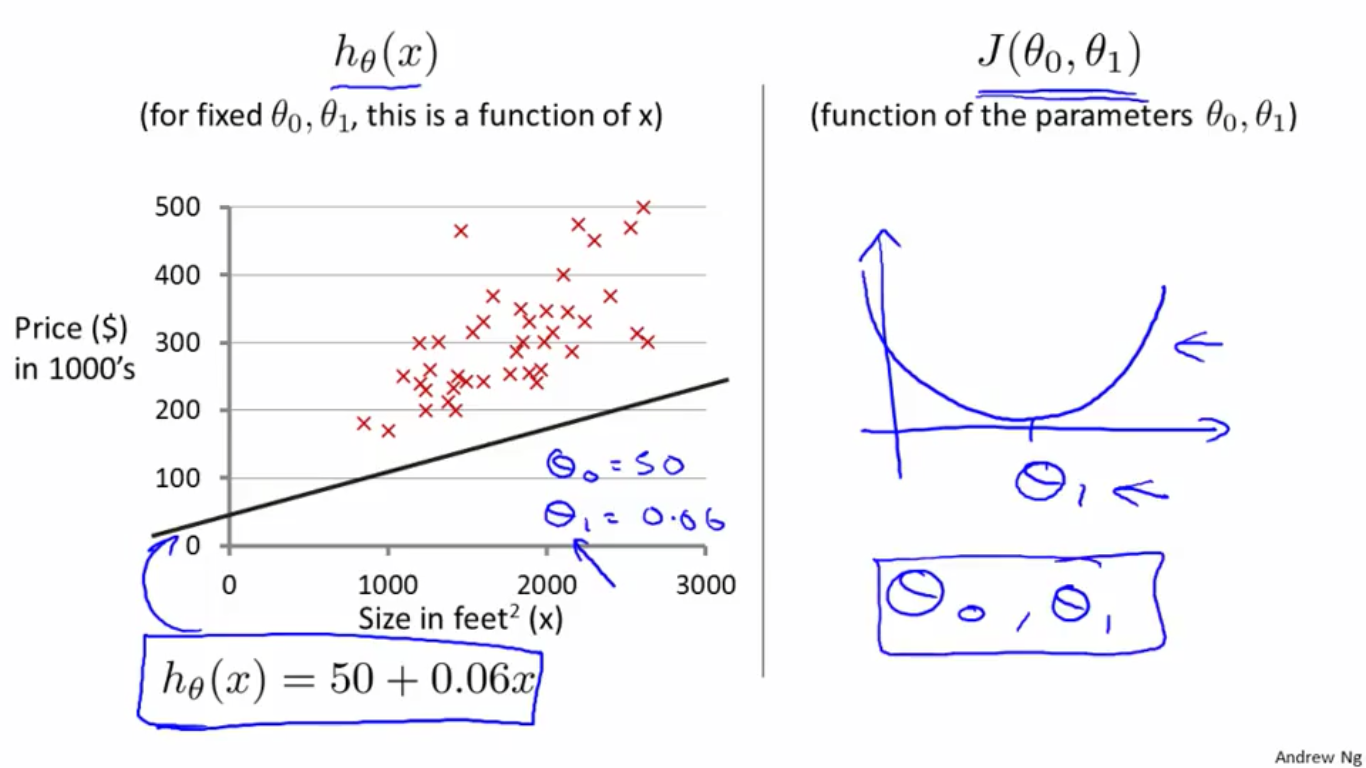
线性回归拟合函数: hΘ(x)=θ0+θ1∗x h Θ ( x ) = θ 0 + θ 1 ∗ x , θi叫做模型参数 θ i 叫 做 模 型 参 数
对于不同的
θ0
θ
0
和
θ1
θ
1
,
hΘ(x)
h
Θ
(
x
)
对应的曲线不同,如下图所示:
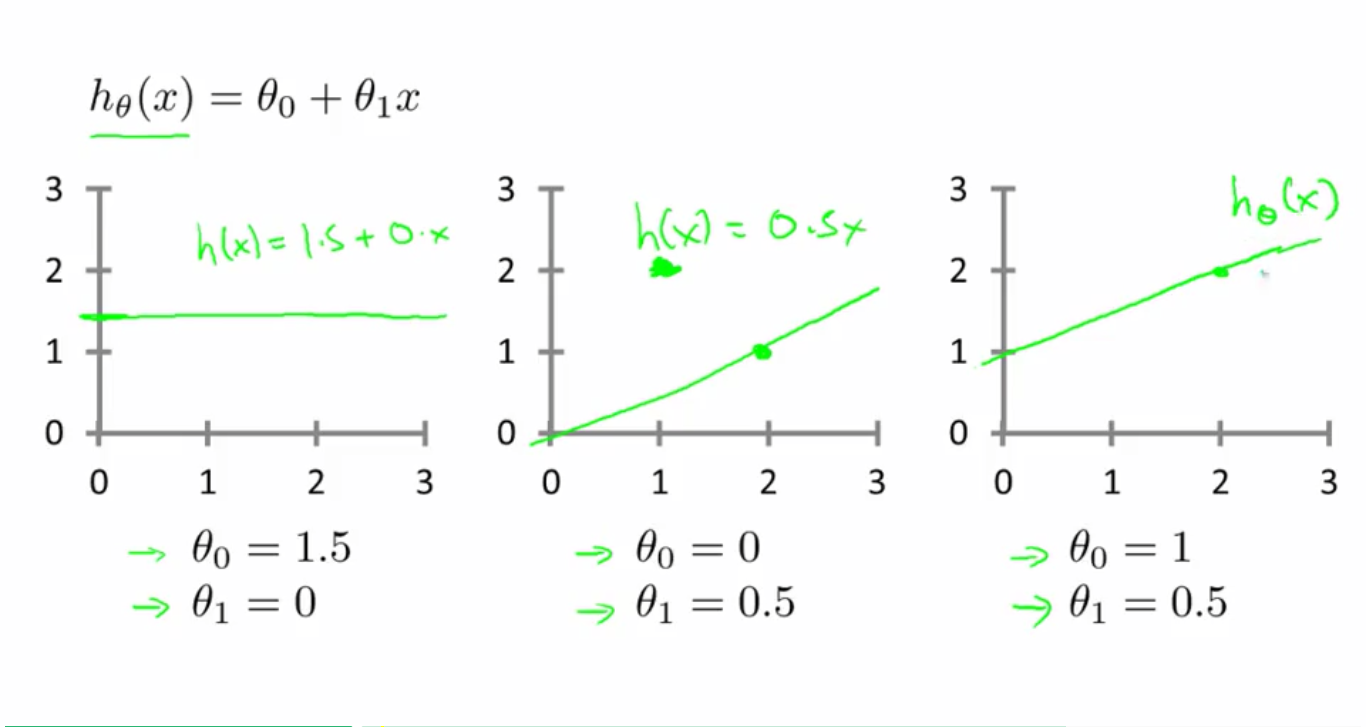
如何选择合适的 θ0 θ 0 和 θ1 θ 1 ,使得 hΘ(x) h Θ ( x ) 和 y y 之间的误差最小?

这里使用了方差这一概念,为什么代价函数是,参见博客:http://blog.csdn.net/quiet_girl/article/details/68544273,里面是自己的一点理解。我们需要求解的便是使得
J(θ0,θ1)
J
(
θ
0
,
θ
1
)
取最小值的
θ0
θ
0
和
θ1
θ
1
。
三、Cost Function - Intuition I(代价函数-直观感知I)
我们需要求出h(x)最小值对应的参数
θ0
θ
0
和
θ1
θ
1
,为了简化操作,这里将
θ0
θ
0
设为0,因此,
h(x)
h
(
x
)
只与
θ1
θ
1
有关,如下图:

对于训练集:
| x | y |
|---|---|
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
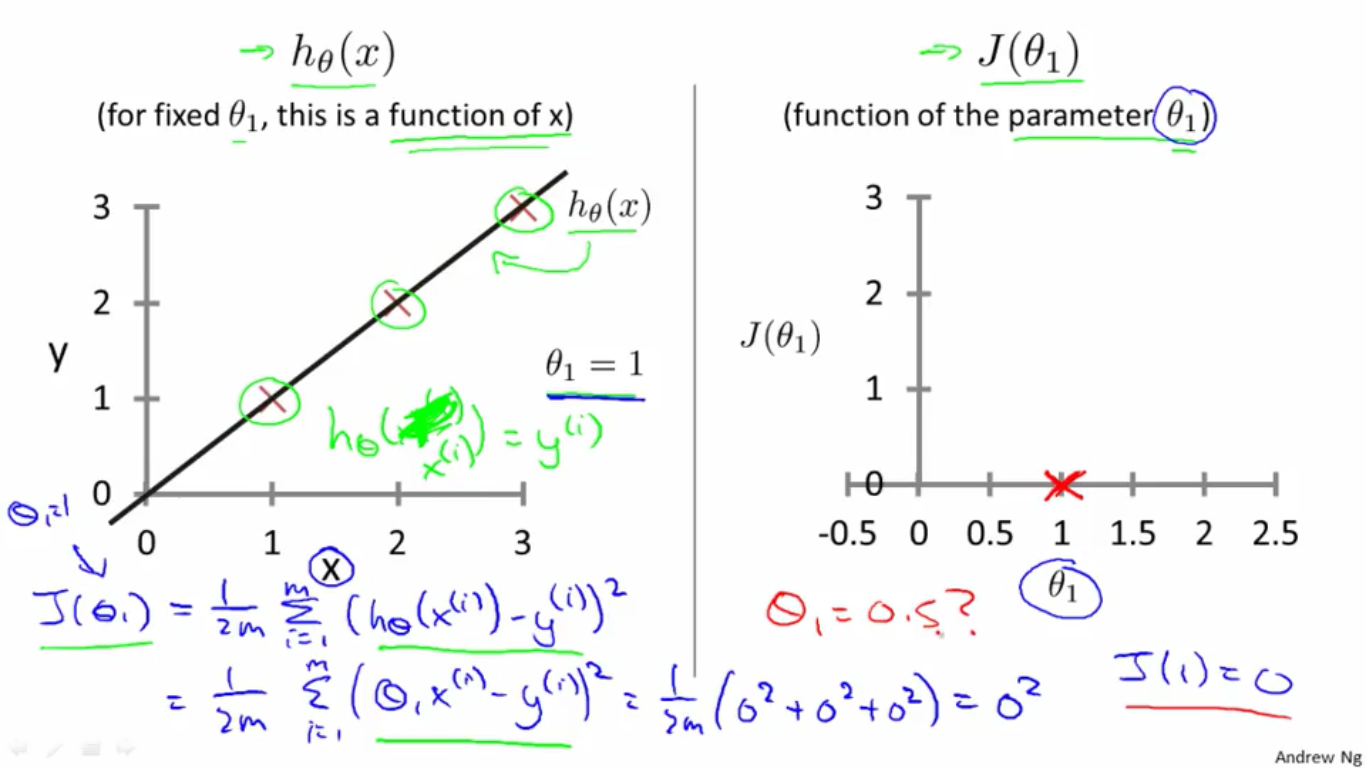
1、令
θ1=1
θ
1
=
1
,则
h(x)=x
h
(
x
)
=
x
,
J(0,1)=0
J
(
0
,
1
)
=
0
,如下图。
2、令
θ1=0.5
θ
1
=
0.5
,则
h(x)=0.5x
h
(
x
)
=
0.5
x
,
J(0,0.5)=0.58
J
(
0
,
0.5
)
=
0.58
,如下图
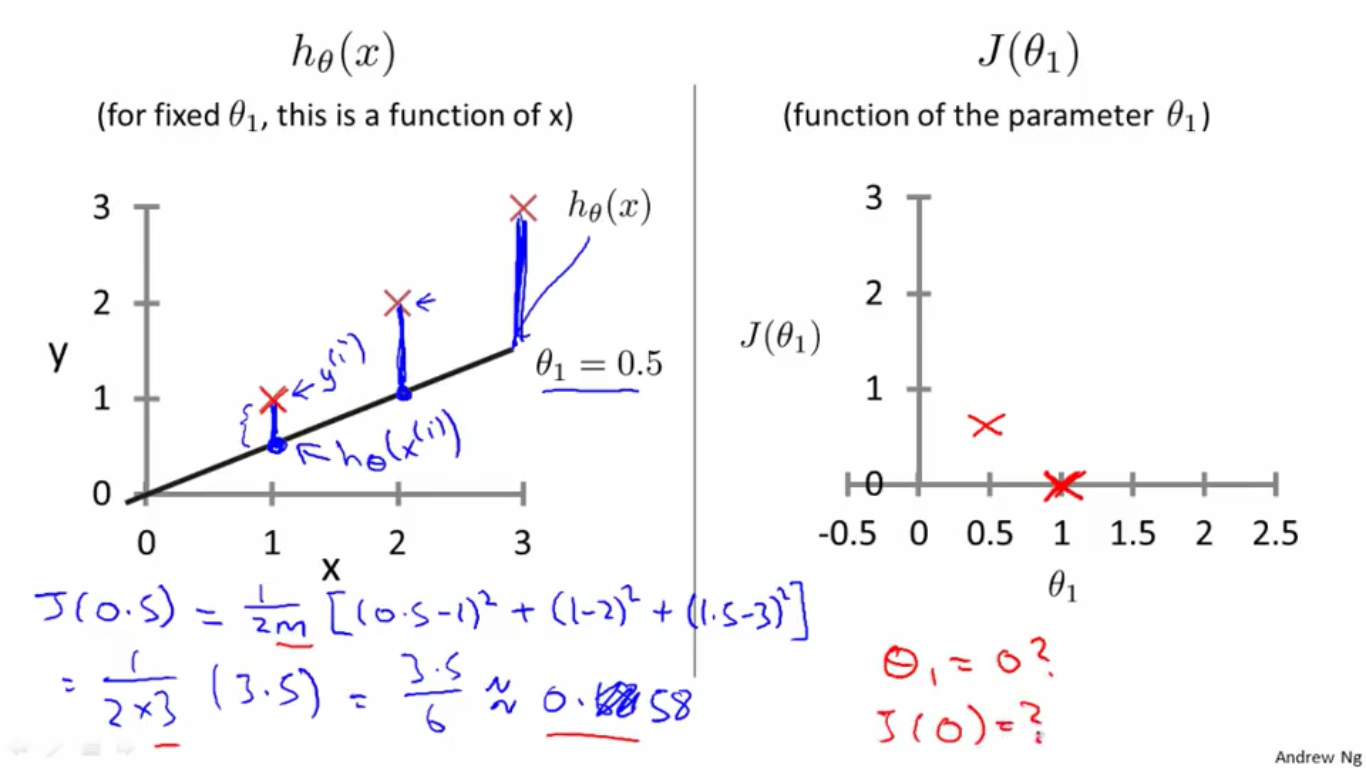
3、令
θ1=0
θ
1
=
0
,则
h(x)=0.5x
h
(
x
)
=
0.5
x
,
J(0,0)=2.3
J
(
0
,
0
)
=
2.3
,如左图。
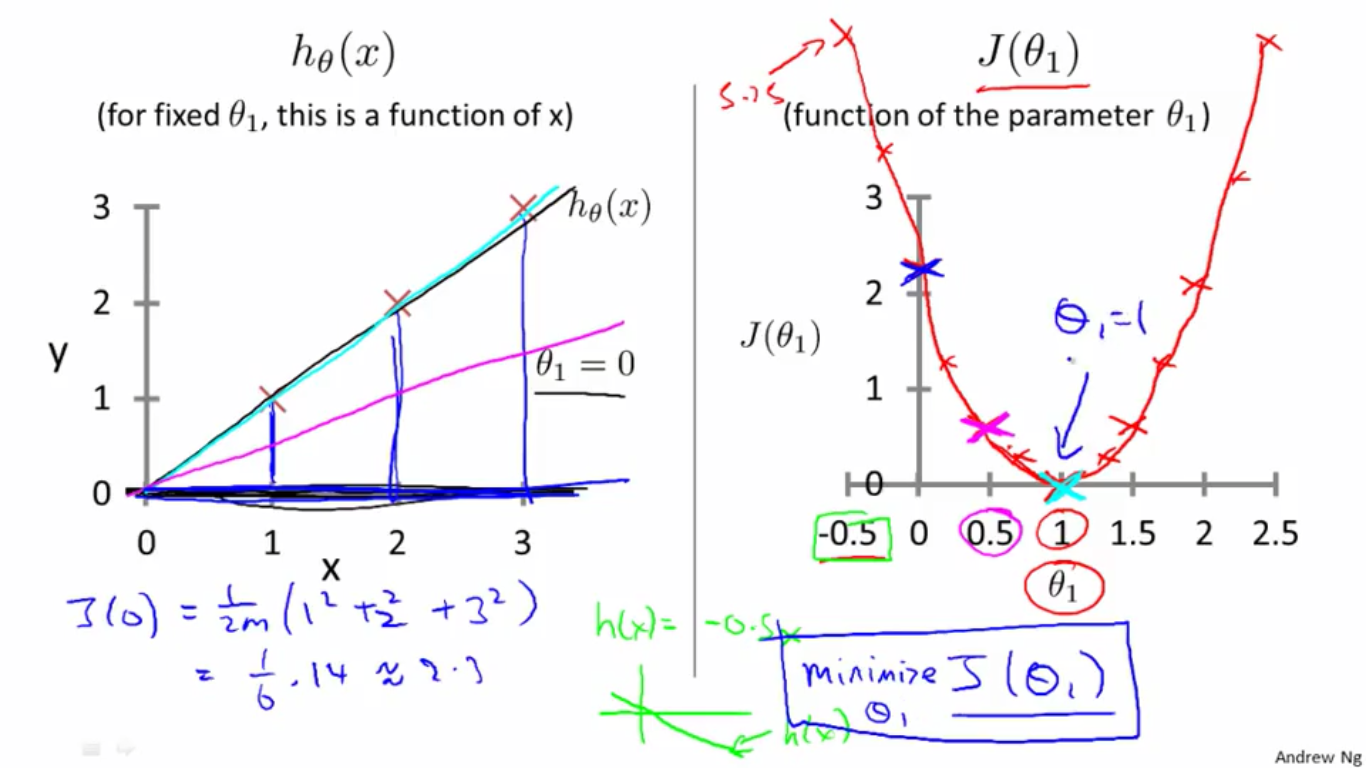
如右图,每个
θ1
θ
1
的值对应一个曲线
h(x)
h
(
x
)
,对于同一个数据集,每个
h(x)
h
(
x
)
对应一个
J
J
的值,用相应的的值和
J
J
的值作图,观察可知,在,
J
J
的值取最小值,此时,代价函数是全局最小值。
四、Cost Function - Intuition II(代价函数-直观感知II)
这里引入轮廓图的概念。
对于下图所示的数据集,不同的参数对应不同的h(x)曲线,将这些曲线对应的J值画出,即形成第二个图新,在这个图形中,某一点的高度代表这一点对应的和
θ1
θ
1
所对应的
J
J
值。
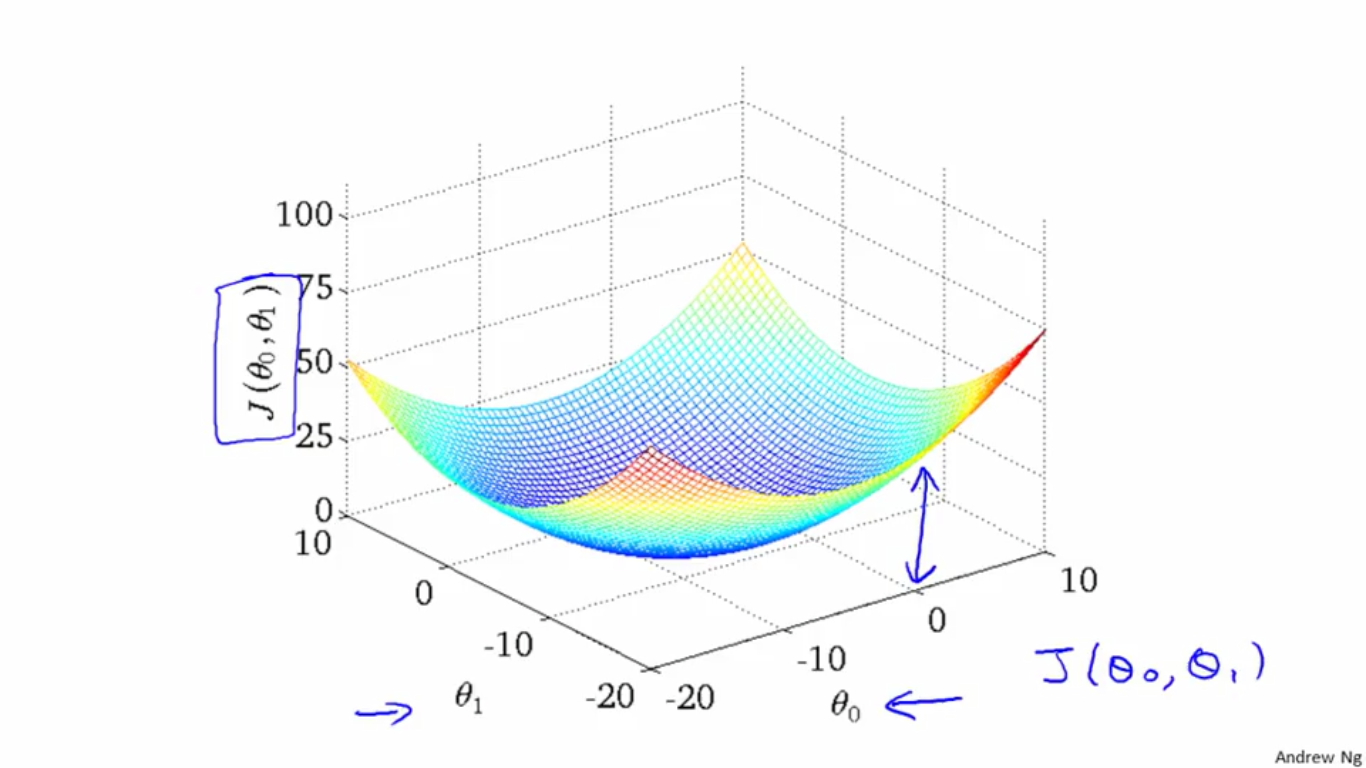
如右图,同一条轮廓线上不同的点,对应的值相同。
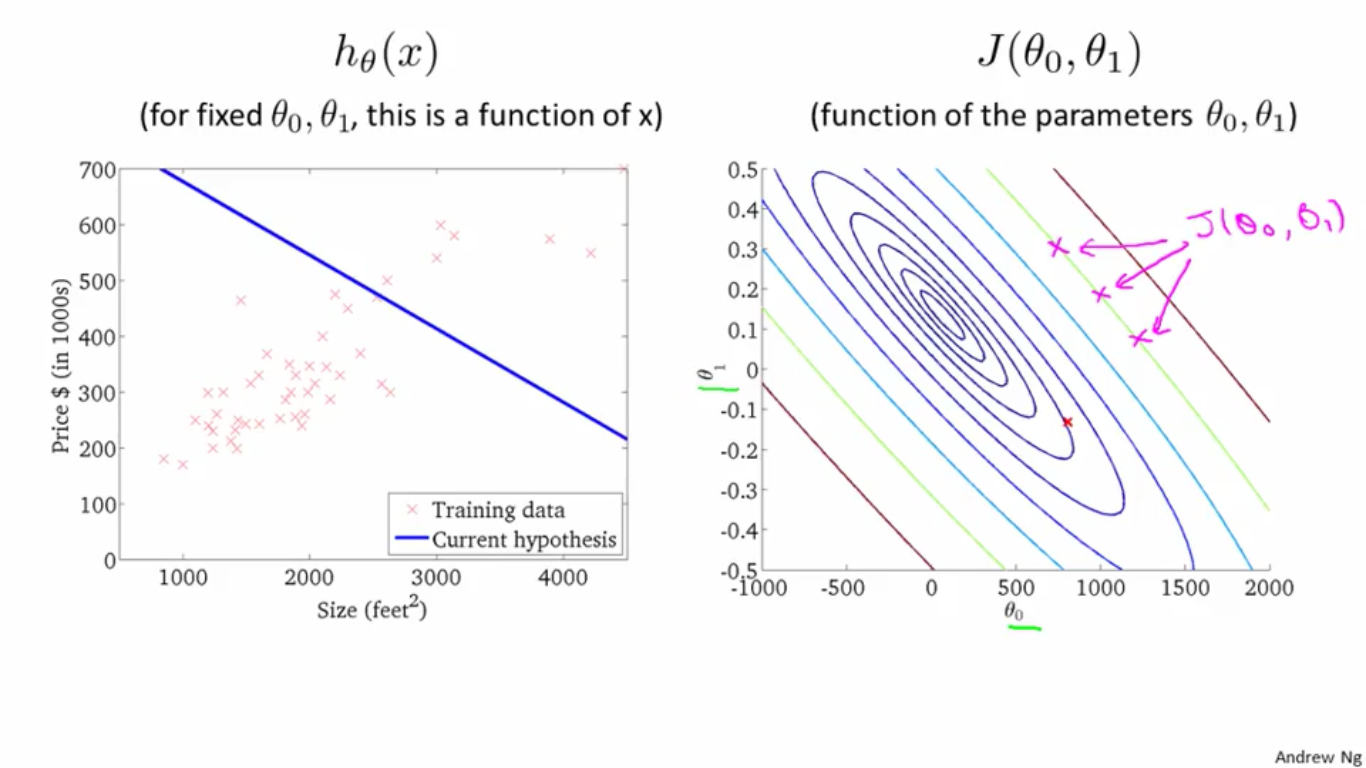
将轮廓图平面化,取不同的轮廓图上的点对应的h(x)曲线,观察其拟合程度。
1、取右图中的一点,大概是
θ0
θ
0
值为800,
θ1
θ
1
值为-0.15,其对应的h(x)图形如左图所示,很明显,这个h(x)拟合性并不好。
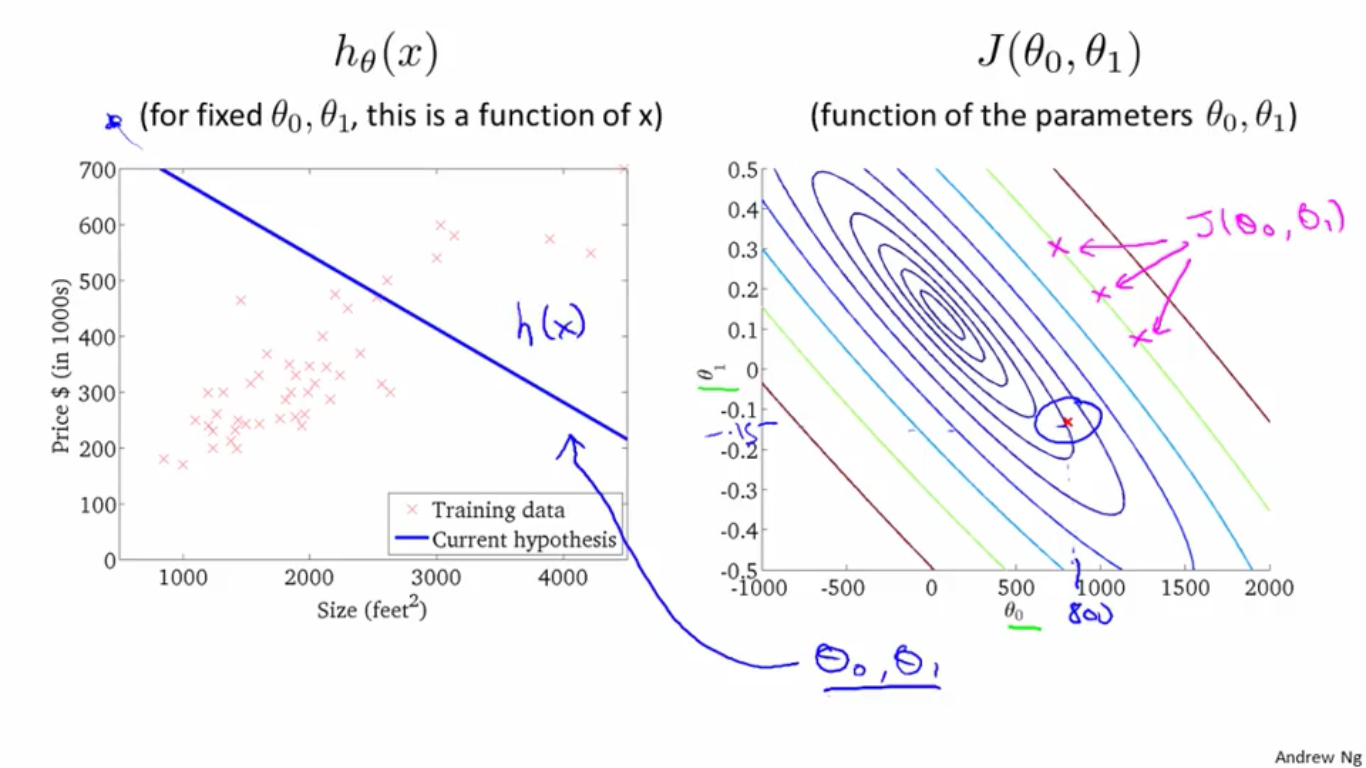
2、取右图中的一点,大概是
θ0
θ
0
值为400,
θ1
θ
1
值为0,其对应的
h(x)
h
(
x
)
图形如左图所示,这个
h(x)
h
(
x
)
拟合性也并不是很好。
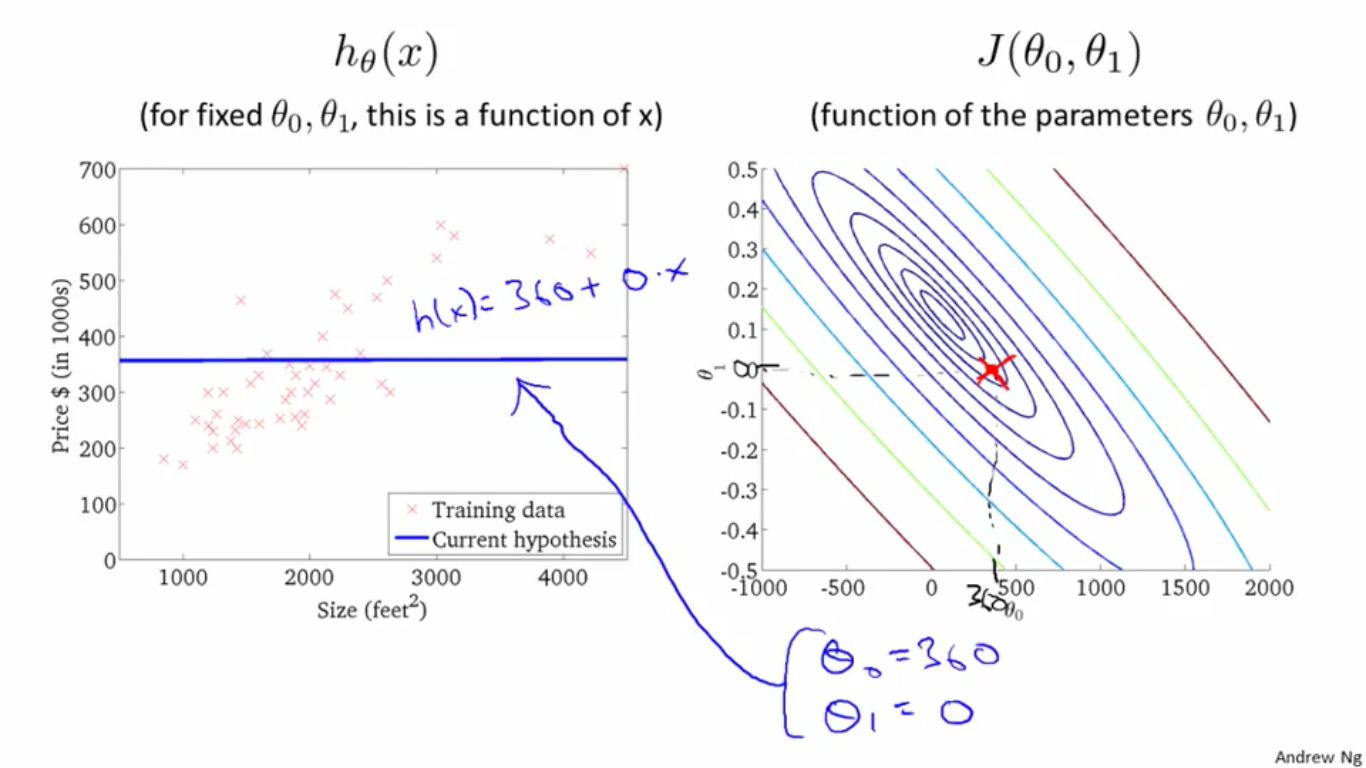
3、取右图中的一点,大概是
θ0
θ
0
值为0,
θ1
θ
1
值为-0.03,其对应的
h(x)
h
(
x
)
图形如左图所示,这个
h(x)
h
(
x
)
拟合性不好。
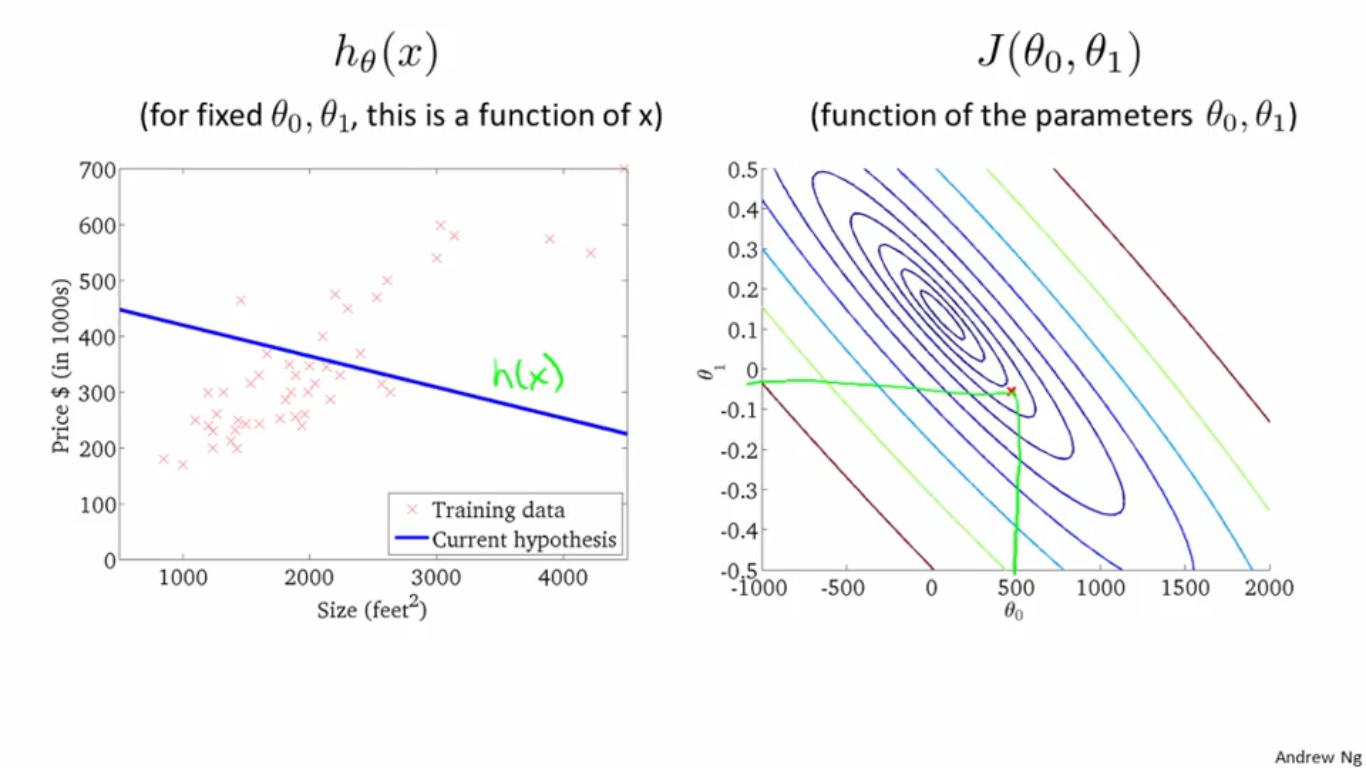
4、取右图中的一点,大概是
θ0
θ
0
值为300,
θ1
θ
1
值为0.15,其对应的
h(x)
h
(
x
)
图形如左图所示,很明显,这个
h(x)
h
(
x
)
对应的
J
J
值要比之前的几个点对应的J值小得多,虽然其不是最优值,但是其越来越接近于最优值。
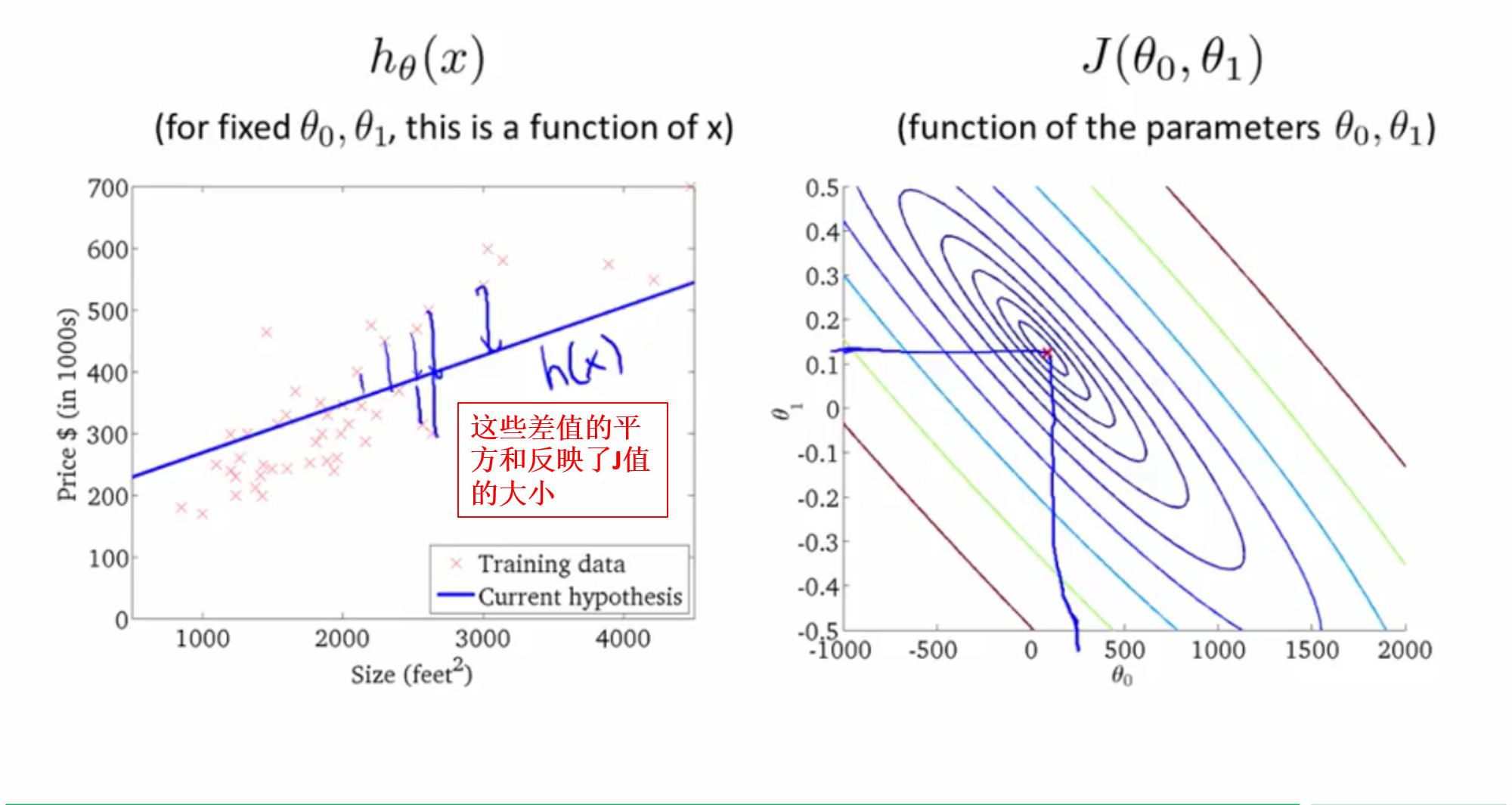
我们的目标就是使用代码实现寻找最优值对应的 θ0 θ 0 和 θ1 θ 1 的值。















 543
543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









