







内容来自Andrew老师课程Machine Learning的第三章内容的Classification and Representation部分。
一、Classification(分类)
(一)分类问题举例
(1)一封邮件是垃圾邮件还是非垃圾邮件
(2)肿瘤是良性的还是恶性的
(3)网上交易是欺骗交易还是非欺骗交易
(二)概念引入
上述几个例子所描述的问题都是二元分类,即y∈{0,1},其中0表示“Negative Class”;1表示“Positive Class”。
(注意,一般用0表示不好的或者不出现的东西,用1表示好的或者出现的东西,但是其实具体0和1表示什么,这是随意的,没有硬性规定,只要0和1是相互对立的含义即可)
除了二元分类之外,更常见的是多元分类,在多元分类中,y∈{0,1,2,3 ……}
(三)对于分类使用线性回归模型可行吗?
(1)首先看下图中的一个例子,含有8个点的数据集,紫色的曲线是拟合曲线h(x),从图中可以看出,以h(x0)=0.5中的x0为分界点,则x<x0时,x肿瘤是良性的,否则是恶性的。
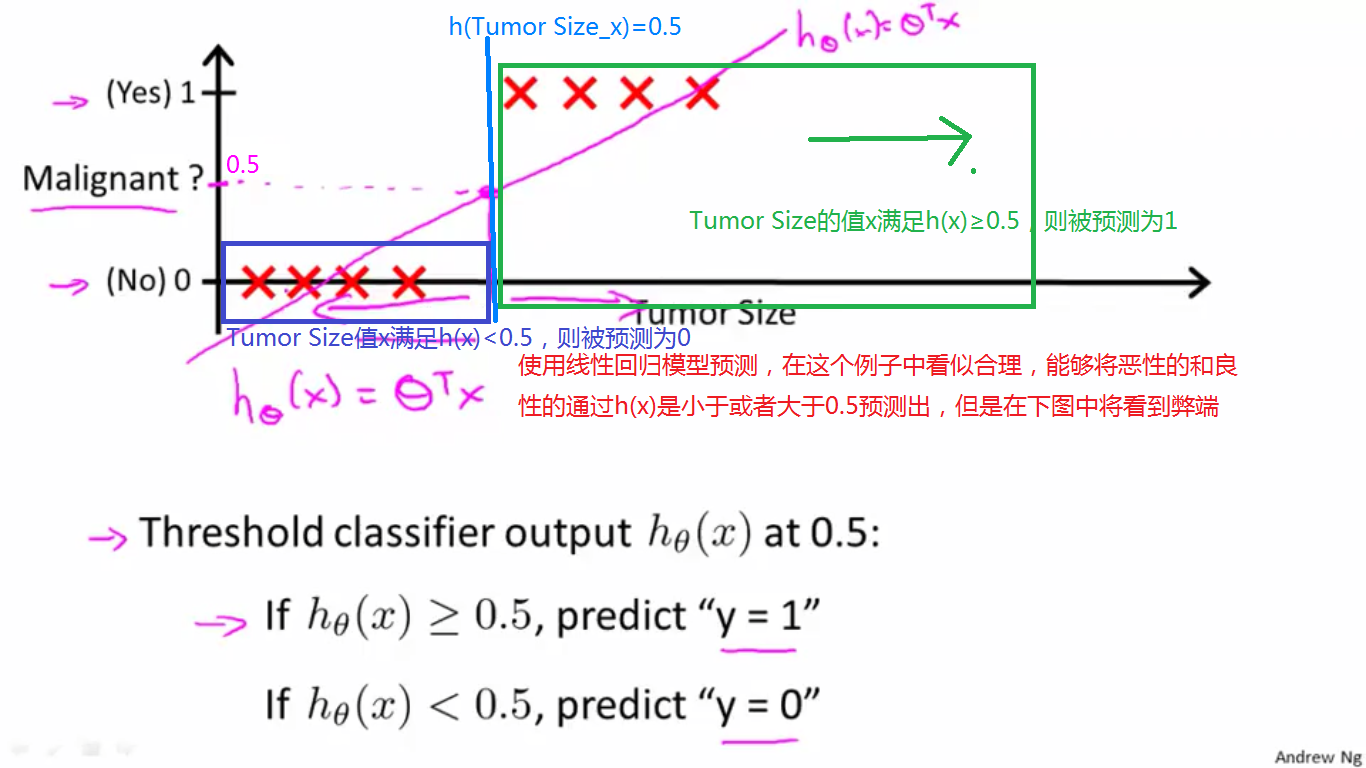
从图中大致可以看出,使用这8个数据训练出来的拟合曲线h(x)效果还是很好的,能够比较准确地预测肿瘤是否是良性的。那么是否分类问题可以用线性回归模型解决呢?看下面的例子。
(2)在上图原有8个数据集的基础上增加一个数据点,如下图,在蓝色的曲线是这9个数据的拟合曲线h(x),以h(x0)=0.5中的x0为分界点,则x<x0时,x肿瘤是良性的,否则是恶性的。
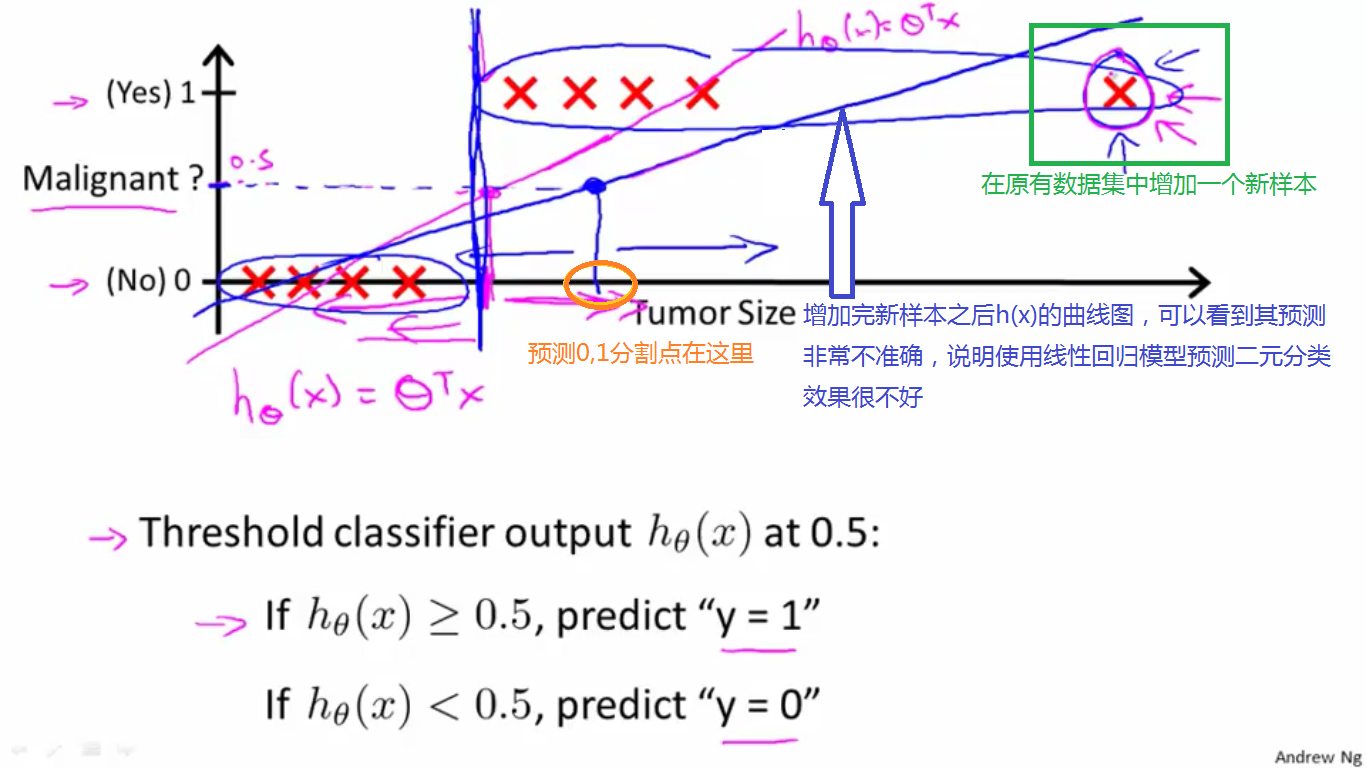
橙黄色圈出的点是分界点x0,从上图中可以看出,预测结果是很不准确的,将一些恶性肿瘤会预测成良性的,因此对于这9个数据组成的数据集,使用线性回归模型效果很不好,即线性回归模型并不适用。
(四)线性回归模型不适用与分类问题的原因及解决方案
(1)线性回归模型不适用与分类问题的原因
因为在二元分类模型中,y的取值指有0或者1,而预测模型h(x)可能会出现大于1或者小于0的值,因此线性回归模型不适用于分类问题。
(2)如何解决?
使用logistic回归模型,在这个模型中,0≤h(x)≤1,符合二元分类模型中y的取值范围。

二、Hypothesis Represetation(假设函数的表示)
(一)由上面的内容可知,我们希望构建一个logistic回归模型,希望能够0≤h(x)≤1。
模型如下,叫做S型模型或者logistic模型:
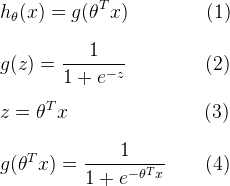
S型函数(logistic模型)图示:
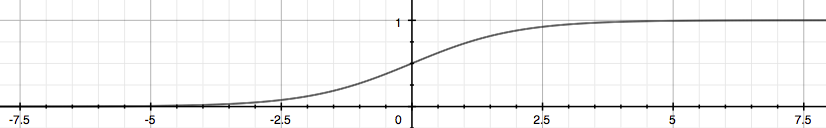
(二)关于假设函数的输出
(1)h(x)的输出值表示:输入一个x且输出值y=1的概率
(2)举例:
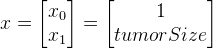
(3)
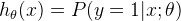
公式表示:probability that y=1,given x,parameterized by theta
又因为y只可能取值0或者1,故有下列公式:
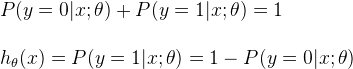
三、Decision Boundary(决策边界)
(一)logistic回归模型方程如图上左,其对应的曲线如图上右,曲线过点(0,0.5),
则:
当z≥0时,g(z)≥0.5;当z<0时,g(z)<0.5。
即:
当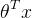
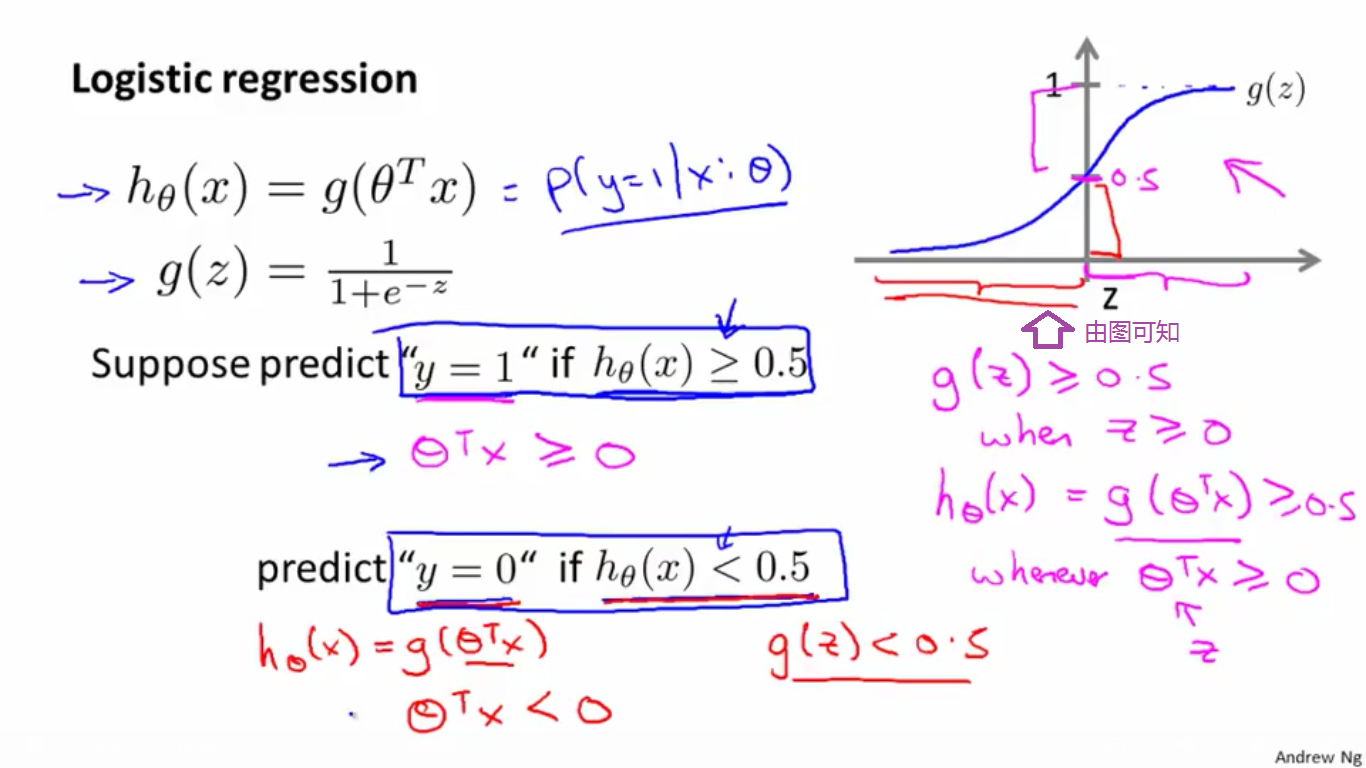
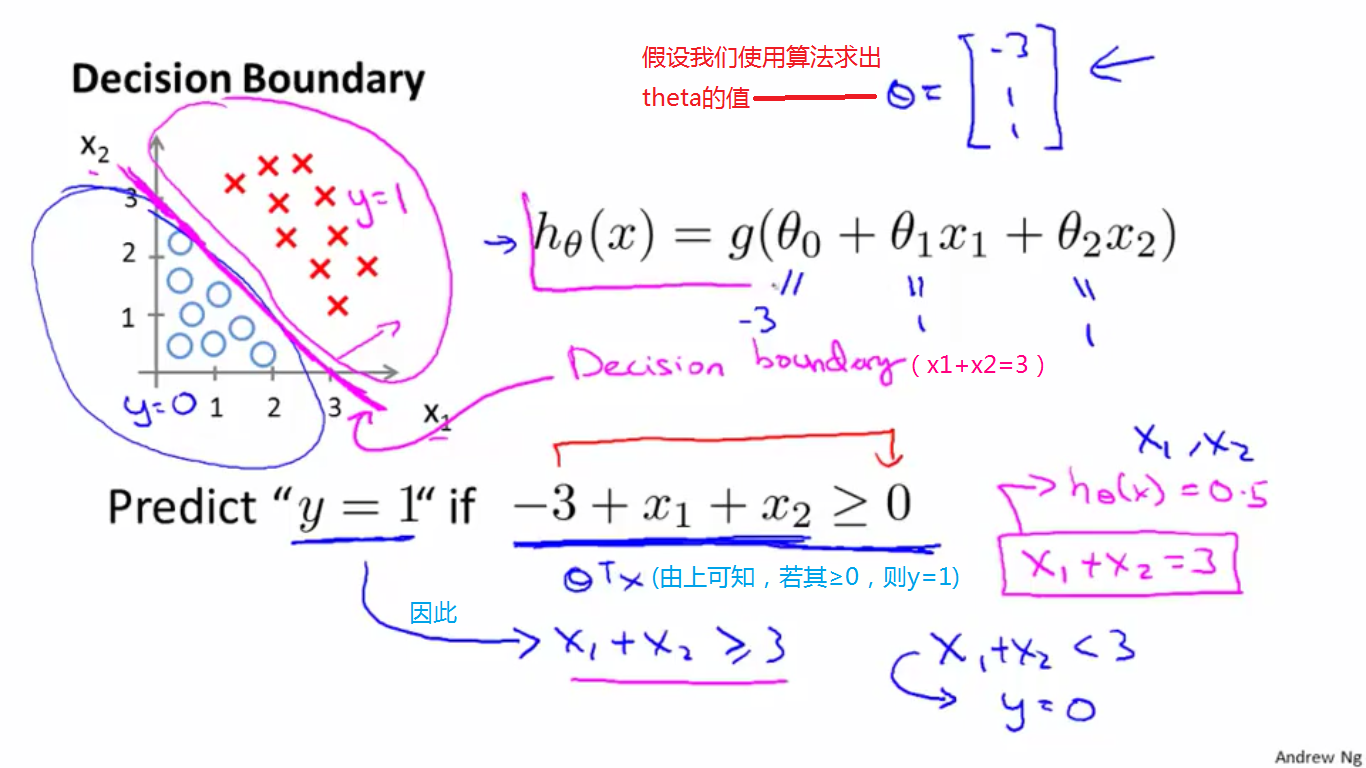
(二)举例(决策边界是线性函数):
如下图左,是一个数据集,h(x)表达式如图右侧,假设theta值已经用算法求出,theta0=-3,theta1=1,theta2=1。则
因此:
当-3+x1+x2≥0,即x1+x2≥3时,h(x)≥0.5,y=1;
当-3+x1+x2<0,即x1+x2<3时,h(x)<0.5,y=0。
决策边界是x1+x2=3。
(三)举例(决策边界是非线性函数):

(1)先看第一个例子
如上图左上,是一个数据集,h(x)表达式如图右上侧,假设theta值已经又算法求出,theta0=-1,theta1=0,theta2=0,theta3=1,theta4=1。则
因此:
当-1+x1^2+x2^2≥0,即x1^2+x2^2≥1时,h(x)≥0.5,y=1;
当-1+x1^2+x2^2<0,即x1^2+x2^2<1时,h(x)<0.5,y=0。
决策边界是x1^2+x2^2=1,即单位圆,如图。
(2)再看第二个例子
上图下面一个h(x)函数比上面一个更复杂,因此它可能对应更加复杂的决策边界。
注意:
只要theta0,theta1,theta2,……参数确定,我们不需要画出数据集可以直接绘制决策边界。即,决策边界不是训练集本身的属性,而是假设本身及其参数的属性,因此只要我们给出了theta,相应的决策边界便确定了,我们不是用训练集来定义决策边界,我们使用训练集拟合参数theta,一旦有了theta便确定了决策边界。















 4948
4948

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









