







内容来自Andrew老师课程Machine Learning的第十章Large Scale Machine Learning。
本部分主要包括如下内容
- Learning With Large Datasets(大数据集训练模型)
- Stochastic Gradient Descent(随机梯度下降算法)
- Mini-Batch Gradient Descent(小批量梯度下降算法)
- Stochastic Gradient Descent Convergence(随机梯度下降算法的收敛)
- Online Learning(在线学习机制)
- Map Reduce and Data Parallelism(映射约减和数据并行)
一、Learning With Large Datasets(大数据集训练模型)
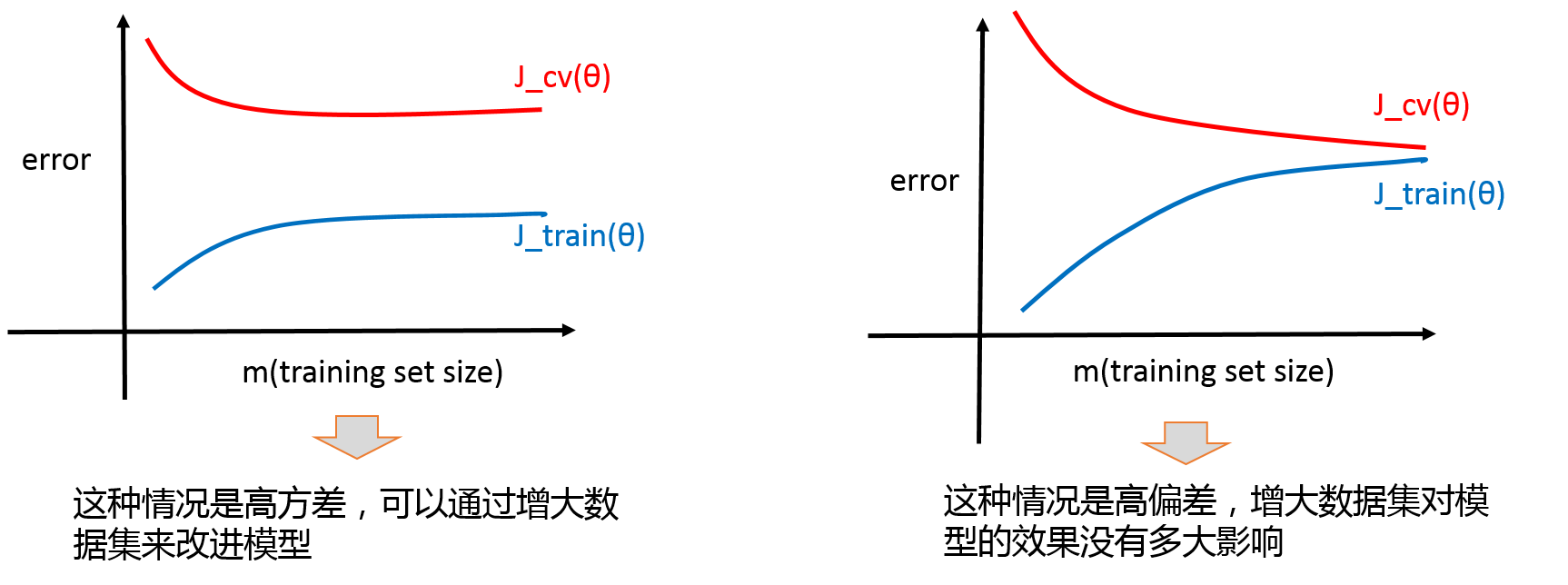
这部分内容和之前的 Machine Learning第六讲[应用机器学习的建议] --(二)诊断偏差和方差有重合部分,这里不再展开,引一个题目再次说明一下:
这个题目对应的点,也就是高方差和高偏差的情况,应该使用什么解决方案,这个之前的那篇博客有详细方案:
二、Stochastic Gradient Descent(随机梯度下降算法)
我们之前提到的梯度下降是指批量梯度下降。
下面是随机梯度下降算法的过程以及和批量梯度下降算法的异同:

随机梯度下降算法是先只对第1个训练样本计算一小步的梯度下降,即这个过程包括调参过程,然后转向第2个训练样本,对第2个训练样本计算一小步的梯度下降,这个过程也包括调参,接着转向第3个训练样本.......
批量梯度下降和随机梯度下降算法的收敛过程是不同的,实际上,随机梯度下降是在某个靠近全局最小值的区域内徘徊,而不是真的逼近全局最小值并停留在那个点,不过其最终也会得到一个很接近全局最小值的参数。这对于绝大多数的实际应用的目的来说,已经足够了。
随机梯度下降算法收敛比较快。
三、Mini-Batch Gradient Descent(小批量梯度下降算法)
小批量梯度下降算法是介于批量梯度下降算法和随机梯度下降算法之间的一个算法。
- 批量梯度下降算法:每次迭代中使用所有(m个)样本
- 随机梯度下降算法:每次迭代中使用1个样本
- 小批量梯度下降算法:每次迭代中使用b个样本(b在2~100之间)
假设b取10,则小批量梯度下降算法如下:

使用小批量梯度下降算法,在处理了前10个样本之后,就可以开始优化参数θ,因此不需要扫描整个训练集,因此小批量梯度下降算法比批量梯度下降算法快。
小批量梯度下降算法在有好的向量化实现时,比随机梯度下降算法好,在这种情况下,10个样本求和可以使用一种更向量化的方法实现,允许部分并行计算10个样本的和。
四、Stochastic Gradient Descent Convergence(随机梯度下降算法的收敛)
先来看一下,我们在批量梯度下降和随机梯度下降中应该怎么判断算法是否收敛:

在批量梯度下降算法中,根据J的收敛判断,在随机梯度下降算法中,若是1000次迭代,我们使用每次迭代的最后1000个样本的平均值为点作图,对于图形对应的分析如下:

图①中:
蓝色的曲线在A点,说明算法已经趋于收敛,因随机梯度下降算法不直接收敛于最小值,因此最后会来回震荡。
若减小学习速率α的值,则可能会出现红色的曲线,其收敛于B点,因α变小,所以收敛速度变慢,且因为α较小,最后震荡的幅度也比较小
图②中:
1000个训练样本得到了蓝色的曲线,若将样本数从1000增加到5000,则会出现红色的更加平滑的曲线。
图③中:
蓝色的直线一直很平坦,说明算法并没有很好地学习。
若增大样本数量到5000,可能会出现红色曲线。若增大样本数量,仍然得到紫色曲线(即仍然是平坦的),则说明算法确实没有学习好,需要调整α或者改变特征等。
图④中:
若出现不降反增的情况,说明算法正在发散,需要减小α的值
总结:
-
之所以曲线是来回震荡的,是因为有噪音
-
若曲线看起来噪音很大,或是老是上下波动,则试试增大你要平均的样本数量
-
若发现代价值在上升,那就换一个小点的α值
我们知道,随机梯度下降算法最后不会收敛于某一个最优值,而是会在最优值边缘来回震荡,在大多数的随机梯度下降算法中,学习速率α一般是保持
不变的,若你确实想要随机梯度算法收敛于全局最优值,可以随时间的变化减小学习速率α的值,所以,一种典型的方法设置α的值是:
α=const1/(iterationNumber+const2),其中iterationNumber是指梯度下降的迭代次数。在这个公式中,随着迭代次数的增加,α的值越来越小,
因此每一步越来越小,直到最终收敛到全局最小值。但是调整const1和const2比较繁琐,若能够得到一个很好的结果,则算法在最小值处的震荡越来
越小。
一般情况下,我们会直接给α一个常数,而不是给出const1和const2,因为确定const1和const2这2个常数比较繁琐,而且在平时的实践应用中,结果
在最小值处震荡的情况我们能接受,能够满足我们的需要。
五、Online Learning(在线学习机制)
实例1:
假设有一个在线包裹系统,用户将包裹从A地运往B地,网站会给出一个价格,用户可能会接受此价格(y=1)或者不接受(y=0)。
特征x用于存储用户的属性、出发地、目的地和网站给出的价格,我们希望去学习P(y=1|x;θ)去优化价格,我们可以使用Logistic回归或者神经网络来学
习,先来考虑logistic回归。
假设你有一个连续运行的网站,则在线学习的流程如下:
Repeat forever{
Get (x, y) corresponding to user
Update θ using (x, y)

}
算法之所以没有使用
在线学习算法可以对正在变化的用户偏好进行调适,特别地,随着时间的变化,大的经济环境发生变化,用户们可能会对价格变得非常敏感,然后愿意
支付更高的价格,又或者,有一批新的类型的用户涌入网站,在线学习算法可以根据变化着的用户偏好进行调适,而且从某种程度上可以跟进变化着的
用户群体所愿意支付的价格。
在线学习系统能够产生这种作用的原因是随着时间的变化,参数θ不断变化和更新,会逐渐调适到最新的用户群体所应该体现出来的参数。
实例2:
产品搜索:通过用户搜索的关键词推荐用户最有可能点击的10部手机。
x用于存储手机的的特征、用户搜索匹配这部手机名称的词数、用户搜索匹配这部手机描述的词数等。
若用户点击这部手机, y=1;否则,y=0。
学习P(y=1|x; θ)。
实例3:
学习应该展示给用户什么特别地优惠信息、选择用户感兴趣的新闻文章......
在线学习机制与随机梯度下降算法非常相似,只是在线学习不是使用一个固定的数据集,而是从一个样本中学习之后丢弃这个样本,如果你有一个连续
的数据流,那么这个算法非常值得考虑。
在线学习的优点:若你有一个变化的用户群,又或者你正在预测变化的事情,在线学习可以慢慢调适到好的假设以便适应用户的最新行为。
六、Map Reduce and Data Parallelism(映射约减和数据并行)
映射约减即利用并行的原理,将数据的计算分散到若干台机器上,以增加速度:

上述例子是将数据分散到4台机器上,这样运行效率理论上会增加4倍,但是实际上因为网络延迟等一些其他的原因,效率增加不到4倍。
上面的情况是利用若干台机器,将数据的计算分散到各台机器上,实际上,我们也可以在一台计算机上实现Map Reduce,即利用现代计算机的多核系
统,将训练样本分成几份,每一个核处理其中一部分,也能实现并行的效果,而且因为数据始终还是在一台机器上运行的,因此不存在网络延迟的影
响。















 1824
1824

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









