







作者:张华 发表于:2024-03-18
版权声明:可以任意转载,转载时请务必以超链接形式标明文章原始出处和作者信息及本版权声明(http://blog.csdn.net/quqi99)
基于Gemma的测试环境搭建
想学习一个langchain, 所以先运行一下langchain的例子,但发现openai调用API改为收费的了。看来只能本地搭建LLM, 半年前也试过在家里的NUC上运行过LLAMA2,但速度比较慢。现在据说Gemma也开源了,试了一下它速度挺快的。
curl -fsSL https://ollama.com/install.sh | sh
ollama list
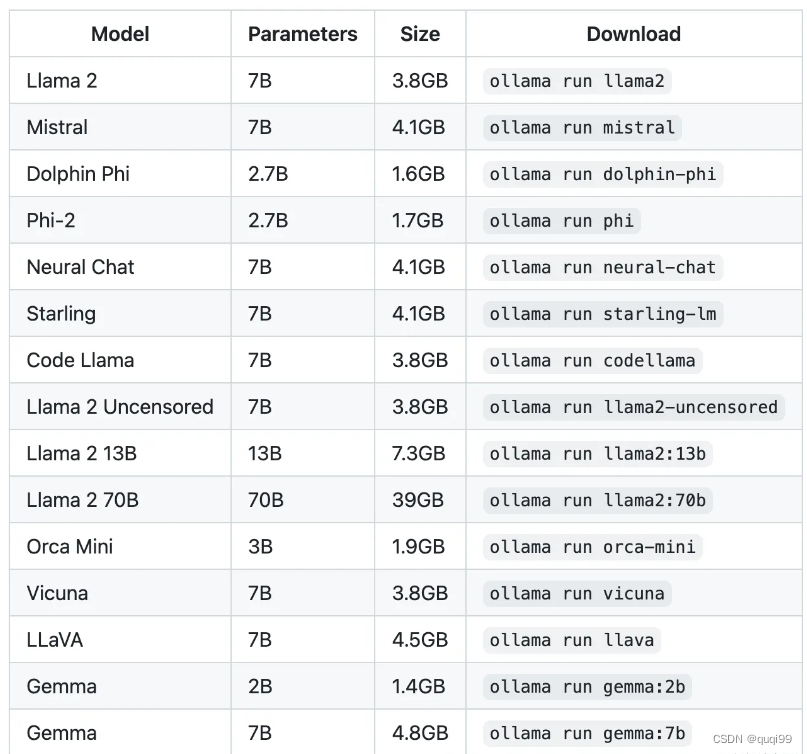
# https://ollama.com/library , qwen:7b是阿里的通义千问,对中文理解更好
#ollama run --gpu <model_name> gemma:2b
ollama run gemma:2b
sudo mkdir -p /etc/systemd/system/ollama.service.d
cat << EOF |sudo tee /etc/systemd/system/ollama.service.d/override.conf
[Service]
Environment="OLLAMA_HOST=0.0.0.0"
EOF
sudo systemctl daemon-reload && sudo systemctl restart ollama
sudo lsof -i :11434
curl -X POST http://minipc:11434/api/generate \
-H "Content-Type: application/json" \
-d '{"model": "gemma:7b", "prompt": "hi, who are you?"}'
sudo apt install docker.io -y
warp-cli status
sudo docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
# web portal: http://minipc:3000
运行第一个langchain程序
sudo pip3 install langchain
$ cat test.py
#!/usr/bin/env python
# coding=utf-8
#!/usr/bin/env python
# coding=utf-8
from langchain_community.chat_models import ChatOllama
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
template = "tell me a joke about {topic}"
prompt = ChatPromptTemplate.from_template(template)
#llm = ChatOllama(model="gemma:2b")
llm = ChatOllama(model="qwen:7b")
chain = prompt | llm | StrOutputParser()
print(chain.invoke({"topic": "关羽"}))
$ ./test.py
Why did关羽战略性地拔掉了自己的一根胡子?
因为他听说"髯公关,美髯公"不只是个称号,留胡子是身份的象征,他为了保全自己的“美髯”,干脆不留了。
RAG example
例子来自: https://zhuanlan.zhihu.com/p/685166253
RAG前的工作流程如下:向模型提问->模型从已训练数据中查询数据->组织语言->生成答案。
RAG后的工作流程如下:读取文档->分词->嵌入->将嵌入数据存入向量数据库->向模型提问->模型从向量数据库中查询数据->组织语言->生成答案。
$ ./test.py
根据提供的信息,身长七尺,细眼长髯的人物是曹操,他的官职是骑都尉,沛国谯郡人。
$ cat data.txt
忽见一彪军马,尽打红旗,当头来到,截住去路。为首闪出一将,身长七尺,细眼长髯,官拜骑都尉,沛国谯郡人也,姓曹,名操,字孟德。
$ cat test.py
#!/usr/bin/env python
# coding=utf-8
# pip install tiktoken "langchain[docarray]"
from langchain_community.document_loaders import TextLoader
from langchain_community import embeddings
from langchain_community.chat_models import ChatOllama
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.vectorstores import DocArrayInMemorySearch
from langchain_community.embeddings import OllamaEmbeddings
model_local = ChatOllama(model="qwen:7b")
# 1. 读取文件并分词
documents = TextLoader("./data.txt").load()
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(chunk_size=7500, chunk_overlap=100)
doc_splits = text_splitter.split_documents(documents)
# 2. 嵌入并存储
embeddings = OllamaEmbeddings(model='nomic-embed-text')
vectorstore = DocArrayInMemorySearch.from_documents(doc_splits, embeddings)
retriever = vectorstore.as_retriever()
# 3. 向模型提问
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model_local
| StrOutputParser()
)
print(chain.invoke("身长七尺,细眼长髯的是谁?"))
agent例子
$ cat playwright_agent.py
#!/usr/bin/env python
# coding=utf-8
# pip install -U langchain-community
import asyncio
from langchain_community.tools.playwright.utils import create_async_playwright_browser
from langchain.agents import initialize_agent, AgentType
from langchain_community.chat_models import ChatOllama
from langchain_community.agent_toolkits import PlayWrightBrowserToolkit
async_browser = create_async_playwright_browser()
toolkit = PlayWrightBrowserToolkit.from_browser(async_browser=async_browser)
tools = toolkit.get_tools()
print(tools)
llm = ChatOllama(model="qwen:7b", temperature=0.5)
agent_chain = initialize_agent(
tools,
llm,
agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
)
async def main():
response = await agent_chain.ainvoke("打开网易首页, 并告诉我网页标题是什么")
print(response)
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
提示词模板
参考: https://cloud.baidu.com/qianfandev/topic/268446
#!/usr/bin/env python
# coding=utf-8
from langchain.prompts.prompt import PromptTemplate
#from langchain.prompts.few_shot import FewShotPromptTemplate
from langchain.prompts import FewShotPromptTemplate
from langchain.prompts.pipeline import PipelinePromptTemplate
from langchain.prompts import ChatPromptTemplate
from langchain.prompts import (
ChatMessagePromptTemplate,
SystemMessagePromptTemplate,
AIMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain import PromptTemplate
template = """\
你是一位资深咨询顾问。
你给一个在线销售{product}的电商公司,取个好的名字?
"""""
prompt = PromptTemplate.from_template(template)
print(prompt.format(product="鱼糕"))
# 也可以使用PromptTemplate的构造函数直接构建
prompt = PromptTemplate(
input_variables=["product", "market"],
template="你是一位资深咨询顾问。对于一个面向{product}市场的,专注于销售{market}的公司,你会推荐哪个名字?"
)
print(prompt.format(product="鱼糕", market="食品"))
# 各种聊天模板不同的地方主要在于它们有不同的角色(系统、用户和助理)
#import openai
#openai.ChatCompletion.create(
# model="gpt-3.5-turbo",
# messages=[
# {"role": "system", "content": "你是一位专业食疗医生"},
# {"role": "user", "content": "请问血糖比较高午餐应该怎么吃?"},
# {"role": "assistant", "content": "一般情况下,血糖高的人午餐吃粗粮、高纤维的食物"},
# {"role": "user", "content": "高纤维的食物有哪些?"}
#
# ]
#)
# 机器学习中有Few-Shot(少量样本)、One-Shot(单样本)和Zero-Shot(零样本)的概念,用于教大模型怎么做。
examples = [
{
"food_type":"黑木耳",
"season": "夏季",
"benefit": "木耳生长在潮湿阴凉的环境中,可以消除血液中的热毒,起到清热解毒的功效。"
},
{
"food_type": "海带",
"season": "春季",
"benefit":"海带有丰富的膳食纤维,有助于促进肠胃"
}
]
template="干货类型: {food_type}\n季节: {season}\n文案: {benefit}"
prompt_example = PromptTemplate(input_variables=["food_type", "season", "benefit"], template=template)
print(prompt_example.format(**examples[0]))
prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=prompt_example,
suffix="干货类型: {food_type}\n季节: {season}",
input_variables=["food_type", "season"]
)
print(prompt.format(food_type="海带", season="春季"))
#如果示例多,使用example_selector,这样可以减少token的开销,也可以增加业务的匹配性
from langchain.prompts.example_selector import SemanticSimilarityExampleSelector
from langchain_community.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
example_selector = SemanticSimilarityExampleSelector.from_examples(
examples,
OpenAIEmbeddings(),
Chroma,
k=1
)
prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=prompt_example,
suffix="干货类型: {food_type}\n季节: {season}",
input_variables=["food_type", "season"]
)
print(prompt.format(food_type="墨鱼", season="秋季"))
从什么叫嵌入数据来理解自然语言处理原理
上面提到嵌入两个字,嵌入就是将文字(人类适合处理)转成数字(计算机适合处理)。
单词的表示法主要有三类:1)刚毕业2007年那会的基于同义词词典的方法需要人工标注语料库麻烦 2)演化成基于统计计数的方法 3)由于推理(word2vec)的自动标注.
这里以第2)种基于计数的方法为例。如一个语料库总共有N个单词:
- 预处理,生成单词到数字及数字到单词映射的两个字典,以及这个生成一个NxN的根据上下文出现次数的共现矩阵(上下文是指某个单词最近的window-size距离的词).
- 原始的共现矩阵需要改进,如根据点互信息生成PPMI矩阵来消除高频词的影响,如根据SVD的方法来降维,这样就形成了就得到了语料库中各单词的分布式表示。
- 然后词和词之间的相似度就可以使用余弦相似度计算求夹角得到,用户查询一个词时就从向量数据库中返回最相似的如top=5个数的词即可。
上面第2)种基于计数的方法有一个问题,就是维数太大,例如,据说英文的词汇量就有超过100W, 那就是100Wx100W的庞大矩阵,这这么大的矩阵来运行SVD降维是不现实的。所以基于第3)种推理的来将单词分布式表示的方法就出来了。它一次只需计算一小部分数据(mini-batch),并反复更新权重。推理就是模型将一个词的上下文词(窗口可为1或更多)作为输入并输出各个单词的出现概率,这个上下文就可以通过one-hot方法来表示为2xN的向量(假设2是上下文窗口大小,N是语料库词汇量总数), 上下文词汇变成向量之后就可以通过神经网络来计算各个单词出的出现概率了。
所以各个模型就是来生成这个单词的分布式表示:
- word2vec: 学习词在语料库的分布,根据上下(前后固定window-size的词)来找一个词(输出概念最大的几个)
- RNN, 有记忆,无论上下文有多长都记得住,根据记忆中的上下文序列(多个词)找到下一个词(单个词), 这样适合机器翻译和语音识别
- seq2seq, 根据记忆中的序列(多个词)找到下一个序列(多个词), 这样就可以写文章了和聊天了. 如组合两个RNN就可以实现seq2seq
- seq2seq+Attention, 多头注意力能捕获词的关联性
- Transformer, 并行化
- GPT, 生成预训练(无监督)
嵌入时需要选择适当的嵌入模型,可以是词嵌入(Word2Vec, GloVe, 设置window-size大小可以改变上下文的大小),也可以是句子嵌入(BERT, Doc2Vec), 这些模型将词或句子映射到高维度的向量空间,从而实现对词或句子语义的捕捉。如OpenAI大模型里的嵌入模式(OpenAIEmbeddings)可以精确的嵌入大段文本(chunk)输出1536维的向量列表 (做查询的时候应该是先用api根据用户问题从向量库查出最相关的几段chunk文本,然后再将这些chunk文本和用户的问题一块往大模型里送).
其他知识点:
- TensorFlow,是一个机器学习的主流框架,它支持CNN, RNN等算法,可运行在大部分异构的硬件上(如CPU, GPU,TPU等)和网络设置上(如RPC,RDMA等)
- kubeflow, 用于将tensorflow等框架跑在k8s上,相当于kubeflow是一个连接云计算与机器学习的桥梁。模型训练可以在性能好的物理机上运行,但是模型训练只是很小一部分,大部分工作是模型训练之外的工作如平台的搭建和配置,数据收集,数据检查,数据转换,模型分析,监控,日志收集和分析,服务发布与更新,迁移训练等还是在kubeflow上实现更好
- langchain, 是一个怎么用各种大模型的就是开发大模型应用的框架。langchain需要去和众多的大模型打交道,并且还得通过Agent来得到大模型之后未学习到的实时数据,还得通过chain将这些数据流链起来。
20240906 - 小爱音箱支持大模型
测试了一下小爱音箱支持ollama phi3小模型,轮询方式还是不顺畅,放弃。另外,市场的上几款大模型音箱基本都不想买:
- 天猫精灵X6 - 宣传是用通义千问基座,实际上用的不是通义千问模型,而是为天猫精灵特制的模型,假大空。
- 小度智能屏X9Pro,宣传是支持文心大模型的,不清楚会是不是又是特制的。另外,它不能安装应用,没有HDMI等接口,没法投屏,没法从app关闭屏幕,孩子拿它当电视看是会伤害眼睛的。
- 小度添添AI平板机器人, 没有HDMI接口,也没有3.5mm音频口,一个平板任何硬件接口都没有。软件方面,只能安装它自己应用市场的应用,据说可以安装应用宝,那安装应用宝里的应用算是曲线救国了。其他牌子的如讯飞的平板估计也会存在类似问题没有接口什么的。
git clone https://github.com/idootop/mi-gpt.git
cd mi-gpt
cp .migpt.example.js .migpt.js
vim .migpt.js #change to use your xiaomi id and password
cat << EOF |tee .env
OPENAI_MODEL=phi3:latest
OPENAI_API_KEY=ollama
OPENAI_BASE_URL=http://minipc.lan:11434/v1
EOF
ollama run phi3
curl http://minipc.lan:11434
sudo docker pull idootop/mi-gpt:latest
sudo docker run -d --env-file $(pwd)/.env -v $(pwd)/.migpt.js:/app/.migpt.js --name migpt idootop/mi-gpt:latest
sudo docker exec -ti migpt sh
20241231 update - 使用deepseek
#https://ollama.com/library
gg curl -fsSL https://ollama.com/install.sh | sh
gg ollama pull deepseek-r1:1.5b
gg ollama pull deepseek-r1:7b
ollama run deepseek-r1:1.5b
ollama run deepseek-r1:7b
20250213 - 将deepseek上运行在火山方舟上
如果你用官方的deepseek总是说服务器忙,那你可以在你自己的电脑上部署一个deepseek大模型,但自己的电脑上部署想要速度快的话需要花钱买好性能的机器和花电费,那就可以在火山方舟上部署deepseek大模型了,有50w tokens的免费使用额度,之后的价格是输入0.0040元/千tokens, 输出是0.0160元/千tokens,这花钱应该比自己买机器和花电费便宜。
1, 注册火山方舟,并部署deepseek-r1模型,并领取50w的tokens (之后是输入0.0040元/千tokens, 输出是0.0160元/千tokens - https://www.volcengine.com/product/ark
2, 在"在线推理"菜单开通用户通过网络调用deepseek大模型提供api服务, 并创建api-key - https://console.volcengine.com/ark/region:ark+cn-beijing/endpoint?config=%7B%7D
3, 通过api_key可以自己写程序,也可以用一个叫Cherry Studio的客户端. 打开 Cherry Studio 后,在设置中选择模型服务,然后选择豆包,把刚刚的 API Key 复制进去(api url用默认的方舟的即可- https://ark.cn-beijing.volces.com/api/v3/)。
4, sudo vim /usr/share/applications/CherryStudio.desktop
[Desktop Entry]
Name=CherryStudio
Exec=/bak/soft/Cherry-Studio-0.9.21-x86_64.AppImage
#Icon=/path/to/icon.png
Type=Application
Terminal=false
StartupNotify=true
5, 但上面自定义的deepseek apk在cursor上按下面方法不好使。 打开cursor -> 文件 -> 首选项 -> Cursor Settings, 添加火山方舟上的自定义deepseek模型: 1) 在OpenAI Key处填api-key 2)在’Override OpenAI Base URL’处填 https://ark.cn-beijing.volces.com/api/v3/ (deepseek官方的是https://api.deepseek.com)
后来改用下面的vscode + Roo Code + 火山方舟deepseek的方式好使了
在vscode中按ctrl+shift+x来安装Roo Code插件(以前叫Roo-Cline, 它并不能安装在cursor中,而是只能安装在vscode中), 此时左侧会多出一人叫"Roo Code"的pannel, 打开它可以配置了:1) API Provider处选择’OpenAI compatible’而不是Deepseek(这个是用官方api_url的 - https://api.deepseek.com) 2) Base Url填火山方舟的: https://ark.cn-beijing.volces.com/api/v3/ 3) 填写火山方舟中的model_id
注: cursor上不能用火山方舟上的deepseek的原因找到了 - https://github.com/Jeremyly/OpenAI-Doubao
6, 火山方舟上创建联网版deepseek方法。
a, 在火山方舟的应用广场菜单找到联网版deepseek应用后点复制即可 - https://console.volcengine.com/ark/region:ark+cn-beijing/application
b , 复制刚创建的联网版deepseek的应用ID, 在cherry-studio接入时, 要将API地址从https://ark.cn-beijing.volces.com/api/v3/ 改成 https://ark.cn-beijing.volces.com/api/v3/bots/
之前填模型ID的地方改成现在的应用ID即可。(注:若失败不成功,是因为AIP地址写成了 .../v3/bots 应该是 .../v3/bots/ )
20250217 - 台式机上的deepseek语音助手
台式机比音箱有更好的硬件,能够用大模型的语音识别,识别态更高也能支持方言能也支持情绪的语音输入。
https://github.com/wwbin2017/bailing (目前语音播放这块还有问题)
Reference
[1] https://blog.csdn.net/quqi99/article/details/132720519
[2] https://zhuanlan.zhihu.com/p/685166253
[3] 使用 Langchain 和 Ollama 的 PDF 聊天机器人分步指南 - https://blog.csdn.net/woshicver/article/details/135614856
[4] https://python.langchain.com/docs/integrations/chat/ollama



















 6256
6256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











