







一、函数说明
使用的是sklearn.ensemble模块。
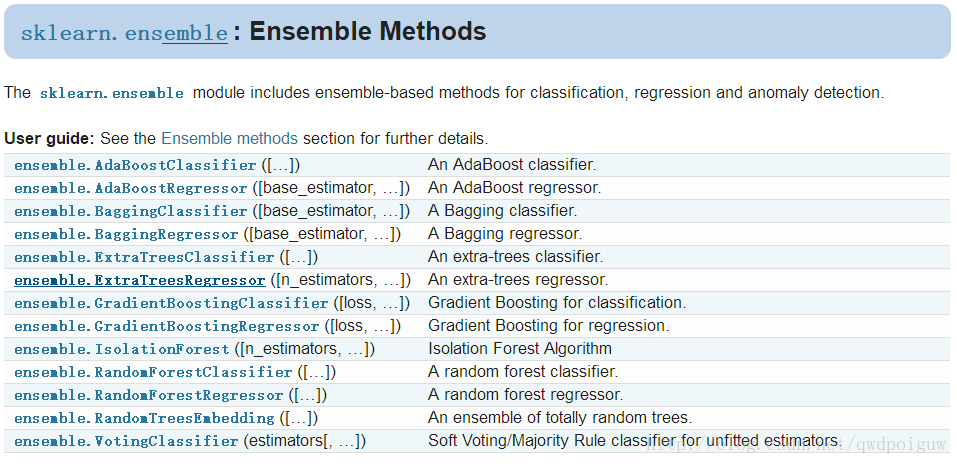
sklearn.ensemble.AdaBoostClassifier有5个参数:

参数说明如下:
- base_estimator:可选参数,默认为DecisionTreeClassifier。理论上可以选择任何一个分类或者回归学习器,不过需要支持样本权重。我们常用的一般是CART决策树或者神经网络MLP。AdaBoostClassifier默认使用CART分类树DecisionTreeClassifier。另外有一个要注意的点是,如果我们选择的AdaBoostClassifier算法是SAMME.R,则我们的弱分类学习器还需要支持概率预测,也就是在scikit-learn中弱分类学习器对应的预测方法除了predict还需要有predict_proba。
- algorithm:可选参数,默认为SAMME.R。scikit-learn实现了两种Adaboost分类算法,SAMME和SAMME.R。两者的主要区别是弱学习器权重的度量,SAMME使用对样本集分类效果作为弱学习器权重,而SAMME.R使用了对样本集分类的预测概率大小来作为弱学习器权重。由于SAMME.R使用了概率度量的连续值,迭代一般比SAMME快,因此AdaBoostClassifier的默认算法algorithm的值也是SAMME.R。我们一般使用默认的SAMME.R就够了,但是要注意的是使用了SAMME.R, 则弱分类学习器参数base_estimator必须限制使用支持概率预测的分类器。SAMME算法则没有这个限制。
- n_estimators:整数型,可选参数,默认为50。弱学习器的最大迭代次数,或者说最大的弱学习器的个数。一般来说n_estimators太小,容易欠拟合,n_estimators太大,又容易过拟合,一般选择一个适中的数值。默认是50。在实际调参的过程中,我们常常将n_estimators和下面介绍的参数learning_rate一起考虑。
- learning_rate:浮点型,可选参数,默认为1.0。每个弱学习器的权重缩减系数,取值范围为0到1,对于同样的训练集拟合效果,较小的v意味着我们需要更多的弱学习器的迭代次数。通常我们用步长和迭代最大次数一起来决定算法的拟合效果。所以这两个参数n_estimators和learning_rate要一起调参。一般来说,可以从一个小一点的v开始调参,默认是1。
- random_state:整数型,可选参数,默认为None。如果RandomState的实例,random_state是随机数生成器; 如果None,则随机数生成器是由np.random使用的RandomState实例。
此外还提供了几种方法:
详见官网
二、使用
预测马的存活。
大致步骤同之前。
# -*-coding:utf-8 -*-
import numpy as np
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
def loadDataSet(fileName):
numFeat = len((open(fileName).readline().split('\t')))
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = []
curLine = line.strip().split('\t')
for i in range(numFeat - 1):
lineArr.append(float(curLine[i]))
dataMat.append(lineArr)
labelMat.append(float(curLine[-1]))
return dataMat, labelMat
def classific0():
dataArr, classLabels = loadDataSet('horseColicTraining2.txt')
testArr, testLabelArr = loadDataSet('horseColicTest2.txt')
#train
bdt = AdaBoostClassifier(DecisionTreeClassifier(max_depth = 2), algorithm='SAMME', n_estimators = 10)
bdt.fit(dataArr, classLabels)
predictions = bdt.predict(dataArr)
errArr = np.mat(np.ones((len(dataArr), 1)))
print('训练集的错误率:%.3f%%' % float(errArr[predictions != classLabels].sum() / len(dataArr) * 100))
predictions = bdt.predict(testArr)
errArr = np.mat(np.ones((len(testArr), 1)))
print('测试集的错误率:%.3f%%' % float(errArr[predictions != testLabelArr].sum() / len(testArr) * 100))
if __name__ == '__main__':
classific0()















 6559
6559

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









