







介绍不再赘述,接上一篇:
本文会分析一个简单的普通函数调用和中断函数调用。其中涉及Cortex-M3架构与AAPCS相关知识。但并不打算从Cortex-M3寄存器组开始讲起,相关知识请参考文末参考资料。
函数调用就一句话:有调有还,再调不难
1.起始代码
void fun(unsigned int tmp)
{
if(tmp)
{
}
}
int main(void)
{
unsigned int tmp1 = 0x11111111;
fun(tmp1);
while (1)
{
}
}
2.普通函数调用过程分析
很多东西在上一章都有提到,就不在详细展开,直接上汇编代码分析过程:
void fun(unsigned int tmp)
{
// 08000224 PUSH {R7}
// 08000226 SUB SP, SP, #12
// 08000228 ADD R7, SP, #0
// 0800022A STR R0, [R7, #4]
if(tmp)
{
}
}
// 0800022C NOP
// 0800022E ADDS R7, #12
// 08000230 MOV SP, R7
// 08000232 POP {R7}
// 08000234 BX LR
int main(void)
{
// 08000236 PUSH {R7, LR}
// 08000238 SUB SP, SP, #8
// 0800023A ADD R7, SP, #0
unsigned int tmp1 = 0x11111111;
// 0800023C MOV.W R3, #0x11111111
// 08000240 STR R3, [R7, #4]
fun(tmp1);
// 08000242 LDR R0, [R7, #4]
// 08000244 BL fun ; 0x08000224
while (1)
// 08000248 B 0x08000248 ; <main>+0x12
{
}
}首先,需要明白的是,main函数也是由其他代码块所调用,它只是我们应用代码的源头,而不并不是整个系统代码的源头。由上一章我们知道,Cortex-M3架构整个系统代码的源头是在地址0x0000 0004处保存的指令地址,这是由M3架构规定的。而main函数被调用是在.s启动文件里:

BL main
这条指令有两个动作,即跳转到main这个符号所代表地址处,同时把当前位置的下一条指令地址保存在LR。这样,在main函数结束时,可以使用B LR或者BX LR可以跳转到被调用前的下一条指令处执行。可以看到这里main这个符号所代表的地址为0x0800 0236,这里正是main函数第一条指令所在FLASH地址:

首先看一下进入main之后所有寄存器的状态:

根据ARM架构过程调用标准中描述:R0~R3是调用者用来传递参数的,如果超过4个,则保存在栈中,而R4~R11则用作保存变量(R9在不同架构下,使用作用不同),最后的返回结果由R0和R1保存。

所以,调用main函数的过程中,我们只需要保证那些在调用前可能会被使用的“工具”调用前是什么样调用后还是什么样,就能保证程序在调用main函数后,还能继续准确无误的执行。专业说法叫,还原现场。这里有两个问题:
1.调用前哪些“工具”可以使用?
所有通用寄存器(M3架构中是R0~R12)、栈。
2.哪些需要还原?
首先ARM规定了R0~R3被用作传参,R0~R1在返回时被用来保存结果,调用者需要确保这4个寄存器在调用后可以被随意使用,所以无论有没有传递参数,只要调用者在调用前使用了这4个寄存器,调用者都需要把使用的寄存器入栈,调用后出栈,所以被调用者不需要关心这4个寄存器。而R4~R11是用来保存变量的寄存器,R12是用来保存IP的寄存器,ARM规定了被调用函数要确保这些寄存器被调用前是什么,被调用后还是什么样。栈也是一样。最后LR保存有调用处的下一条指令,所以为了能顺利跳转回去,要确保这个值在函数结束时还能被重新加载回来。
3.怎么还原这些“工具”?
寄存器用前入栈,用后出栈。不破坏【大于调用时SP指针地址】处的数据,且SP指针保证调用前后不变,即栈还原。
所以调用后要保证R4~R12和LR、SP调用前一样。(其实LR未必要一样,只是在调用后通常都使用BX LR直接跳转回去,因为调用时的BL会自动加载LR的值)
main函数内容如下:

PUSH {R7 , LR}
这条指令也有两个动作,即把R7和LR寄存器里面的内容保存到栈里,并且SP指针减去保存内容所占用的栈的大小。而保存位置就由栈顶指针SP开始。
对main函数来说,它调用过程中使用了R7和LR,所以这两个寄存器的值会被改变,所以为了使main函数在运行完成后,跳转回被调用处时,运行现场被完美还原,必须要把它们先保存起来,等到R7和LR被使用完,在函数结束的时候,再把保存的值填充回去,这个上文已经说明。
执行完这条指令通过debug模式下可以看到R7和LR的值正是被保存在从SP(0x2001 0000)开始的栈内:
![]()
而R13~R15变为了:

对比入栈前的数值,SP减小了8,而栈地址0x2000 FFFC和0x2000 FFF8处分别保存的是LR和R7的值。(你应该知道SP永远指向当前栈顶,PC永远指向将要执行的代码地址,但SP需要手动调整,或者使用PUSH这种带有自动调整的指令,而PC无需手动调整,如果手动更改PC值,将会改变代码执行流程)
SUB SP , SP , #8
ADD R7 , SP , #0
这两句是令SP = SP - 8 , R7 = SP + 0。首先SP = SP - 8 是为了保存临时变量。但是这里我们知道main里只用一个tmp1变量,而它占用了4个字节,那为何需要减8?
1.SP减8获得调用fun前的栈底,它同时又是main调用的fun函数的栈顶,也是调用fun返回后的栈顶。
2.在标准调用中,需要保证SP8字节对齐。
MOV.W R3 , #0x11111111
STR R3 , [R7 , #4]
LDR R0 , [R7 , #4]
BL fun
上述代码是作用是令R3 = 0x11111111,然后把R3的值保存到R7的值+4地址处,也就是main的栈底+4,然后又把此处的值加载到R0里面,然后跳转到fun函数。由上文知道R0~R3是用来传递参数的,所以最后把0x11111111加载到R0是没有任何问题的,但是总感觉代码很绕很罗嗦,这个和优化等级有关,因为现在是默认没有任何优化,所以每个步骤都不会被省略,包括每个变量保存在栈里。
在跳转到fun函数后我们查看寄存器:

R0用来传递参数值是0x11111111,其次SP是当前栈顶,也就是fun如果需要使用栈,是从0x2000FFF0开始的,LR因为BL fun这条代码,自动装载了main函数调用fun处的下一句代码:

这里最低位置1表示THUMB状态。查看栈可以看到:
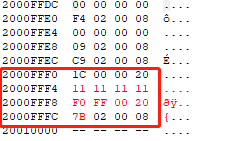
如果fun需要使用栈保存一个32位变量,它会被保存在0x2000FFEC处。对于fun函数内容如下:

可以看到因为字节对齐,除了push自动分配的4字节,又手动分配了12字节(0x2000FFE8~0x2000FFE0),但其实只用了4字节(0x2000FFE4):
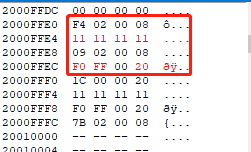
但是因为对tmp判断后什么也没做,所以只有一个nop,而且直接把SP增加12后,用pop把R7复原的同时SP又增加4。运行到最后就是fun中使用的R7在使用过后被复原了,SP指针在使用完后又变为main的栈底:

至此,main调用fun之前的现场又被还原。
当然例子中的fun函数如此简单,但是在更加复杂的情况下也是一样,使用哪个寄存器保存哪个寄存器,以保证调用结束时复原,比如这里的R7。同时SP保证调用前和调用后相同。如果有返回值,则使用R0~R1保存。(当你使用汇编写代码时,则可以随心所欲。但是当你汇编与C混合编程时则需遵守)
3.中断函数调用过程分析
在中断例程中我们使用HardFault,方法是故意触发一个异常。例程代码如下:
void HardFault_Handler(void)
{
// 08000224 PUSH {R7}
// 08000226 ADD R7, SP, #0
while(1)
// 08000228 B 0x08000228 ; <HardFault_Handler>+0x4
{
}
}
char *str = "1234";
void fun(unsigned int tmp)
{
// 0800022C PUSH {R7}
// 0800022E SUB SP, SP, #12
// 08000230 ADD R7, SP, #0
// 08000232 STR R0, [R7, #4]
if(tmp)
// 08000234 LDR R3, [R7, #4]
// 08000236 CMP R3, #0
// 08000238 BEQ 0x08000242 ; <fun>+0x16
{
str[0] = 1;
// 0800023A LDR R3, =str ; [PC, #16] [0x0800024C] =0x20000000
// 0800023C LDR R3, [R3]
// 0800023E MOVS R2, #1
// 08000240 STRB R2, [R3]
}
}
// 08000242 NOP
// 08000244 ADDS R7, #12
// 08000246 MOV SP, R7
// 08000248 POP {R7}
// 0800024A BX LR
// 08000250 PUSH {R7, LR}
int main(void)
{
// 08000250 PUSH {R7, LR}
// 08000252 SUB SP, SP, #8
// 08000254 ADD R7, SP, #0
unsigned int tmp1 = 0x11111111;
// 08000256 MOV.W R3, #0x11111111
// 0800025A STR R3, [R7, #4]
fun(tmp1);
// 0800025C LDR R0, [R7, #4]
// 0800025E BL fun ; 0x0800022C
while (1)
// 08000262 B 0x08000262 ; <main>+0x12
{
}
}可以看到在fun中判断tmp非0后会改变一个常量字符串,为了编译通过,没有在对*str加以const修饰。从汇编代码看,在运行完以下代码后会触发HardFault中断:

也就是把R2的值存入R3所存地址里,因为R3所存地址是不可改变区域,所以会触发一个异常。进入中断前各寄存器值为:

而在进入中断后,首先有两个位被置1:

第一个是代表硬fault:

第二个表示不精确的数据访问:

当然如果是普通中断,比如串口中断是不会有这些置位的。
根据《Cortex-M3权威指南》中断响应分为3个步骤:
1.入栈
由上文触发异常前的SP我们可知在进入异常后的栈顶为0x2000FFE0,当进入异常后,我们查看栈空间:

可以看到地址从0x2000FFDC开始,逐渐递减依次保存着xPSR, PC, LR, R12以及 R3‐R0,这是固定的:

2.取向量

这点因为代码已经进入到我们在main.c中声明的HardFault_Handler函数内,足以证明取向量是正常的,因为3号异常正是HardFault_Handler。
3.更新寄存器
在进入异常处理函数后,各个寄存器的值如下:

其中SP因自动压栈而减小,LR的值表示:

最后PSR的最低位表示异常编号:

至于其他寄存器,和普通函数调用并无不同,使用哪个入栈哪个,在中断结束时则出栈。在寄存器方面异常处理比普通函数调用多的就是自动压栈和自动出栈[R0~R3\R12\LR\PC\PSR]。但是可以想到异常处理和普通函数并不冲突,因为自动出入栈的这些寄存器在普通函数调用中并不会被使用。
最后是中断返回,这里因为是硬fault,所以是没有返回的,但是在其他异常中,返回时需要:

结尾:
思考如何从hardfault中分析触发函数,如果是多层嵌套呢?
更新:2022-02-10
1.关于AAPCS简单介绍,截取自《ARM Cortex-M3与Cortex-M4权威指南》:

2.关于函数结构:

此处可以印证于前文函数汇编代码。















 782
782











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









