






一、开集半监督学习设置Open-Set Semi-Supervised Learning (OSSL)
标记资源有限,旨在利用大量无标记数据完成识别任务,无标记数据包括有限的已知类和未知目标(unseen outliers)
二、一般主流方法的思想
面对开放环境,首先检测未知outliers,然后将其过滤后,利用剩余价值信息,再进行开集分类。
局限性:当标记资源稀缺,不可靠的离群检测器会错误地排除大量的有价值inliers,导致严重的性能下降
三、IOMatch
3.1 Introduction
大多SSL(半监督)方法依赖的假设是:标记数据与未标记数据共享相同的空间,但是真实环境不可避免地会遇到未知类型目标
3.2 Preliminaries and Overview
对于K分类问题,开集设置下,训练集包括
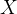 ,
,
 ,
,

对于标记数据
,我们施加随机弱增强策略以获取弱增强变换后的样本。
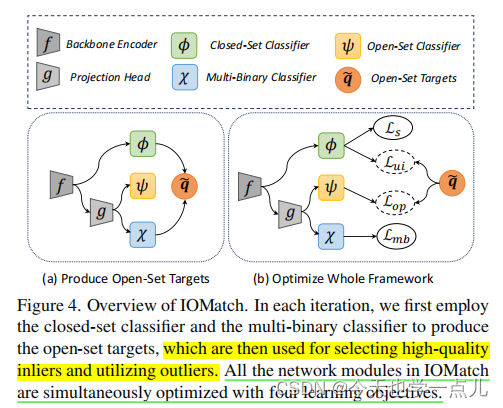
第一分支:闭集分类网络由 特征提取器+闭集分类器组成,相应的标记数据的损失函数是标准交叉熵损失。
另一分支:在特征提取后,采用一个投影头去获得低维嵌入,然后使用多个二元分类器构建离群检测器
对于未标记数据U,我们都利用强增强和弱增强,同样地经过特征编码器,分别同样经过上述两个分支获得闭集预测概率和离群检测结果。
除此之外,在经过投影头的第二分支中,为未标记数据引入了 开集分类器,其中所有outliers被视为单独的一个新类别。
整体 框架如图所示:
3.3.损失函数
3.3.1 闭集分类:
对于标记数据:标准交叉熵损失;
对于无标记数据:扩增一致性损失(沿用了fixmatch中的交叉熵形式)
3.3.2 离群检测:
借助硬负采样策略构建损失:

然后,接下来需要联合利用离群检测器和闭集分类器,在这之前,为了避免常规openmax中闭集分类器学习不充分进而影响outlier检测的问题,我们设计了新的策略:利用前人的DA策略(用于平衡模型分布的分布对齐策略),处理经过闭集分类器的输出。
3.3.3 定义新变量:(新变量是开集伪标签)

可以理解是从闭集分类预测和离群检测两方面作双重肯定,旨在由其估计待测样本(无标记)确实属于第k类已知类的可能性
对应地,样本是不属于任何已知的outliers的概率表示为:
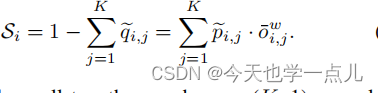
因此,开集问题被转化为了一个 K+1类的类别分布问题
3.3.4 Joint Inliers and Outliers Utilization
由构造的开集伪标签作监督,训练开集分类器:具体又采用了伪标签的思想
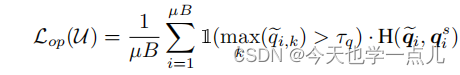
为了获取更好的开集目标质量,我们需要不断优化 闭集分类器及离群检测器
一方面,开集损失优化开集分类器的同时也优化了投影头,进而离群检测器也得以优化,那么针对闭集分类器:提出了一种双过滤策略来选择高质量的类伪标签

其中,
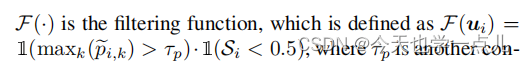
其旨在 让真正的inliers逐渐参与到训练阶段,防止IOMatch陷入与前述方法同样的问题
(这里需要再深入理解:个人认为是很好地降低了模型对于未知类检测筛选的需求)
最后,整体损失直接加权:

四、总结梳理
IOMatch实际上依赖的框架仍然是Openmatch,整体分两个分支:分类与OVA检测,创新在于无标记数据的开集伪标签策略和损失函数的设计,核心是联合学习并利用已知类与未知类。
原本,无标记数据相应的损失由熵最小化和一致性正则(基于增强的平滑)构成,现在的方案是一方面,重新定义了无标记样本的开集预测概率,由其监督强增强样本的开集输出 计算其交叉熵;
另一方面,通过双层过滤策略,筛选闭集识别概率高于设定阈值,且开集未知类识别概率低于设定阈值的数据,利用这些伪已知,进行类似于fixmatch的一致性损失,从而进一步优化闭集分类器。















 2895
2895











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









