






 文章探讨了斑点鬣狗的社会行为特点,将其行为模式应用于数学模型,设计了一种名为SHO的搜索算法。算法模仿斑点鬣狗的狩猎策略,包括包围、搜索和攻击,以解决优化问题。文章还分析了算法的时间和空间复杂度。
文章探讨了斑点鬣狗的社会行为特点,将其行为模式应用于数学模型,设计了一种名为SHO的搜索算法。算法模仿斑点鬣狗的狩猎策略,包括包围、搜索和攻击,以解决优化问题。文章还分析了算法的时间和空间复杂度。
🌼2 . 1 .启示
社会关系本质上是动态的。这些都受到组成网络的个体与离开或加入种群的个体之间关系变化的影响。动物行为的社会网络分析主要分为三类[ 26 ]:
·第一类包括环境因素,如资源可获得性和与其他动物物种的竞争。
·第二类关注基于个体行为或质量的社会偏好。
·第三类较少受到科学家的关注,包括物种本身的社会关系。
动物之间的社会关系是我们工作的灵感,并将这种行为与被科学命名为斑鬣狗属的斑点鬣狗联系在一起。
鬣狗是一种大型的类狗食肉动物。它们生活在非洲和亚洲的稀树草原、草原、亚荒漠和森林中。他们在野外生活10 ~ 12年,被监禁长达25年。目前已知的鬣狗有四种,分别是斑点鬣狗、条纹鬣狗、棕色鬣狗和土狼,它们在体型、行为和食性上存在差异。由于前腿比后腿长,所有这些物种都具有类似熊的姿态。
斑鬣犬是技艺精湛的猎手,也是其他3种鬣狗中最大的(即条纹状、棕色和土狼)。斑鬣犬也被称为Laughing Hyena,因为它的声音与人类的笑声非常相似。它们之所以被称为,是因为它们的毛皮上有斑点,斑点的颜色是红棕色的,有黑色的斑点。斑鬣犬s是一种复杂的、智能的、高度社会化的动物,具有非常可怕的声誉。他们有能力无休止地争夺领土和食物。
在鬣狗家族中,女性成员占主导地位,生活在自己的氏族中。然而,男性成员在成年后离开自己的宗族去寻找和加入一个新的宗族。在这个新的家庭中,他们是排名最低的成员,以获得他们的饭菜份额。一个已经加入氏族的男性成员总是与相同的成员(朋友)长期呆在一起。而女性,永远是有保证的一个稳定的地方。关于斑点鬣狗的一个有趣的事实是,当发现新的食物来源时,它们会发出非常类似于人类大笑的声音警报来相互交流。
根据Ilany等[ 26 ]的研究,鬣狗通常以群居的方式生活和狩猎,依靠信任的朋友网络拥有超过100个成员。为了增加他们的网络,他们通常与另一个斑点鬣狗结盟,这个斑点鬣狗是朋友的朋友,或者通过亲属关系以某种方式联系在一起,而不是任何未知的斑点鬣狗。斑点鬣狗是可以通过姿势和信号等专门的叫声相互交流的社会性动物。他们使用多种感官程序来识别自己的亲属和其他个体。他们还可以识别第三方亲属,并对他们的宗族伙伴之间的关系进行排序,并在社会决策中使用这些知识。斑点鬣狗通过视觉、听觉和嗅觉追踪猎物。图2显示了斑鬣狗的追踪、追捕、环绕和攻击机制。凝聚簇有助于斑点鬣狗之间的高效合作,也有助于最大限度地提高适合度。在这项工作中,狩猎技术和斑点鬣狗的社会关系被数学建模来设计SHO并进行优化。

图2 .斑点鬣狗的捕食行为:( A )搜寻和追踪猎物( B )追逐( C )麻烦和包围( D )不动的情况和攻击猎物。
🌼2.2 数学模型和优化算法
本小节给出了搜索、包围、狩猎和攻击猎物的数学模型。然后对SHO算法进行了概述。
🌼2.2.1 包围猎物
斑点鬣狗可以熟悉猎物的位置并将其包围。为了对斑点鬣狗的社会等级进行数学建模,我们认为当前的最佳候选解是目标猎物或目标,由于搜索空间先验不可知而接近最优解。其他搜索代理在定义了最佳搜索候选解后,会尝试更新自己的位置,约定最佳最优候选解。
该行为的数学模型由下式表示:

其中定义了猎物和斑点鬣狗之间的距离,x表示当前迭代,
和
是系数向量,
表示猎物的位置向量,
是斑点鬣狗的位置向量。然而,| |和·分别是绝对值和与向量的乘法。
向量B和E的计算如下:

为了适当平衡探索和利用,在最大迭代次数( MaxIteration )过程中,从5线性递减到0。此外,随着迭代值的增加,该机制促进了更多的利用。然而,
,
是[ 0、1 ]中的随机向量。图3显示了方程的影响。( 1 )和( 2 )在二维环境中.在该图中,斑点鬣狗( A、B)可以向猎物( A * , B *)的位置更新自己的位置。通过调整向量B和E的值,使得当前位置有不同数量的位置可以到达。斑鬣狗在3D环境中可能更新的位置如图4所示。
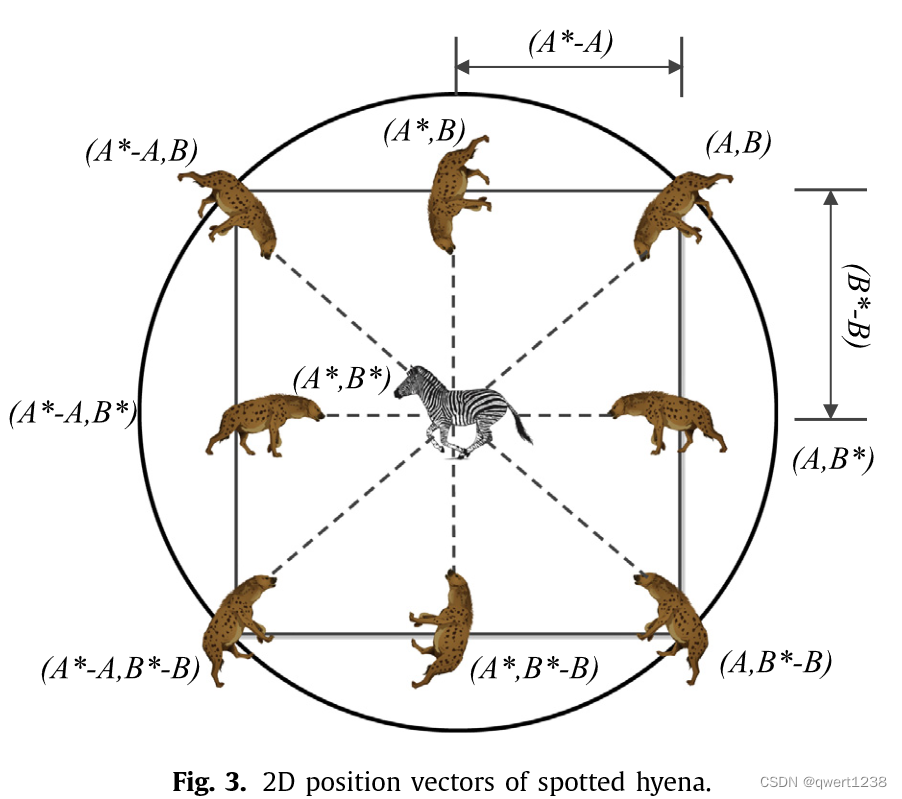
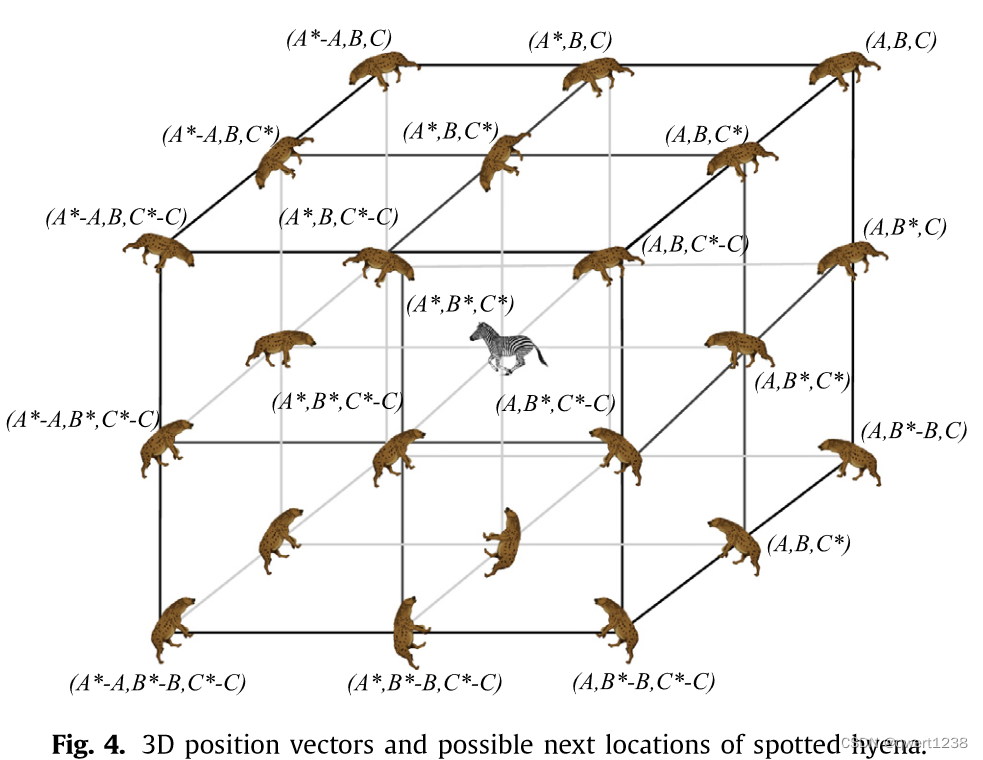
通过使用公式。( 1 )和( 2 ),一个斑点鬣狗可以在猎物周围随机更新它的位置。因此,同样的概念可以用n维搜索空间进一步扩展。
🌼2.2.2 狩猎
斑点鬣狗通常以群居的方式生活和捕猎,并依赖于可信任的朋友网络和识别猎物位置的能力。为了从数学上定义斑点鬣狗的行为,我们假设最好的搜索代理,无论哪个是最优的,都知道猎物的位置。其他搜索代理组成一个集群,可信好友群组,朝着最佳搜索代理前进,并保存迄今为止获得的最佳解来更新自己的位置。在该机制中提出了以下方程:

其中定义了第一个最佳斑点鬣狗的位置,
表示其他斑点鬣狗的位置。其中,N表示斑点鬣狗的数量,计算公式如下:
![]()
其中M是[ 0.5 , 1]中的一个随机向量,定义了解的个数,并统计了与M相加后的所有候选解,它们与给定搜索空间中的最佳最优解非常相似,而
是N个最优解的一个群或簇。
🌼2.2.3 攻击猎物(剥削)
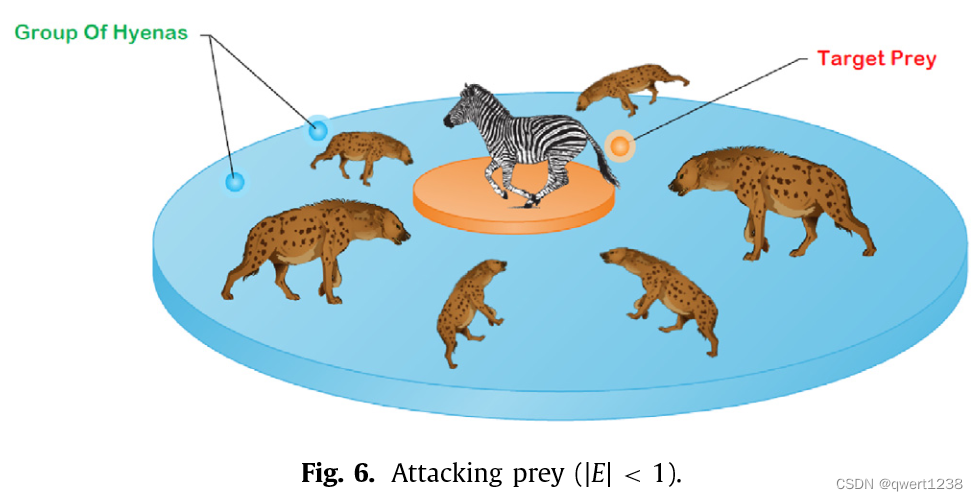
为了对攻击猎物进行数学建模,我们降低了向量h的值。向量E的变化量也随之减小,以改变向量h的值,在迭代过程中,的值可以从5减小到0。由图6可知,| E | < 1迫使斑点鬣狗群向猎物攻击。攻击猎物的数学表述如下:
![]()
其中保存最佳解,并根据最佳搜索代理的位置更新其他搜索代理的位置。SHO算法允许搜索代理更新其位置并向猎物发起攻击。
🌼2.2.4 寻找猎物(探索)
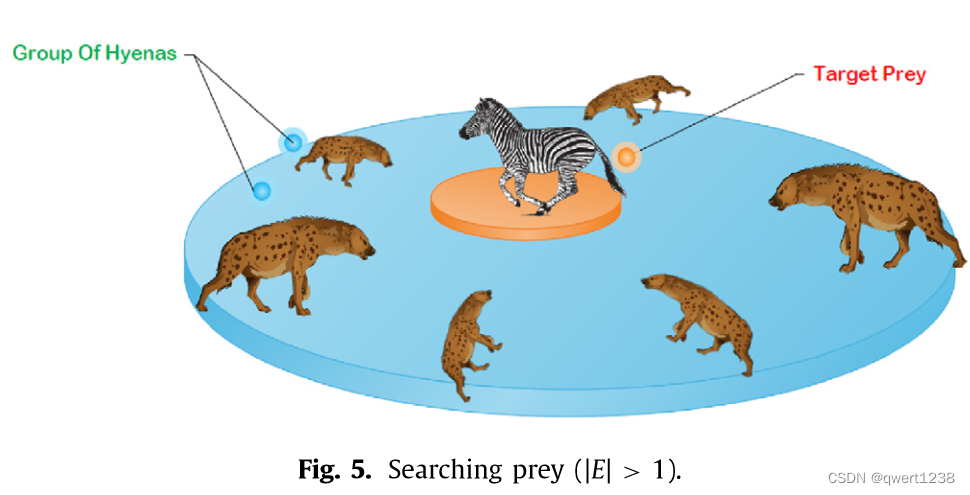
斑点鬣狗大多根据栖息在Ch载体上的斑点鬣狗群体或集群的位置来搜寻猎物。它们相互远离以搜寻和攻击猎物。因此,我们使用随机值大于1或小于- 1的E来迫使搜索代理远离猎物。该机制允许SHO算法进行全局搜索。为了寻找合适的猎物,图5显示| E | > 1有利于斑点鬣狗远离猎物。使探索成为可能的SHO算法的另一个组成部分是B。( 3 )式中,B向量包含随机值,提供了食饵的随机权重。式中:( 3 )式中,B向量包含随机值,提供了食饵的随机权重。为了显示SHO算法更多的随机行为,假设向量B > 1优先于B < 1,以显示在距离上的效果,如式( 1 )所示。( 3 ) .这将有助于探索和避免局部最优。根据斑点鬣狗的位置,它可以随机地决定对猎物的重量,并可能使斑点鬣狗变得僵硬或无法到达。我们有意识地需要向量B为探索提供随机值,不仅在初始迭代中,而且在最终迭代中也是如此。这种机制非常有助于避免局部最优问题,在最后的迭代中比以往任何时候都更有效。最后,通过满足终止准则来终止SHO算法。
SHO算法的伪代码说明了SHO如何求解优化问题,可以注意到以下几点:
•所提出的算法在迭代过程中保存了迄今为止获得的最好的解。
•所提出的环绕机制定义了解周围的一个圆形邻域,该邻域可以扩展到更高的维度作为超球体。
•随机向量B和E帮助候选解具有不同随机位置的超球体。
•所提出的狩猎方法允许候选解定位猎物的可能位置。
·通过调整向量E和h的值来探索和利用的可能性,并允许SHO在探索和利用之间轻松切换。
·对于向量E,一半的迭代用于搜索(探索) ( | E |≥1),另一半用于狩猎(利用) ( | E |≤1)。
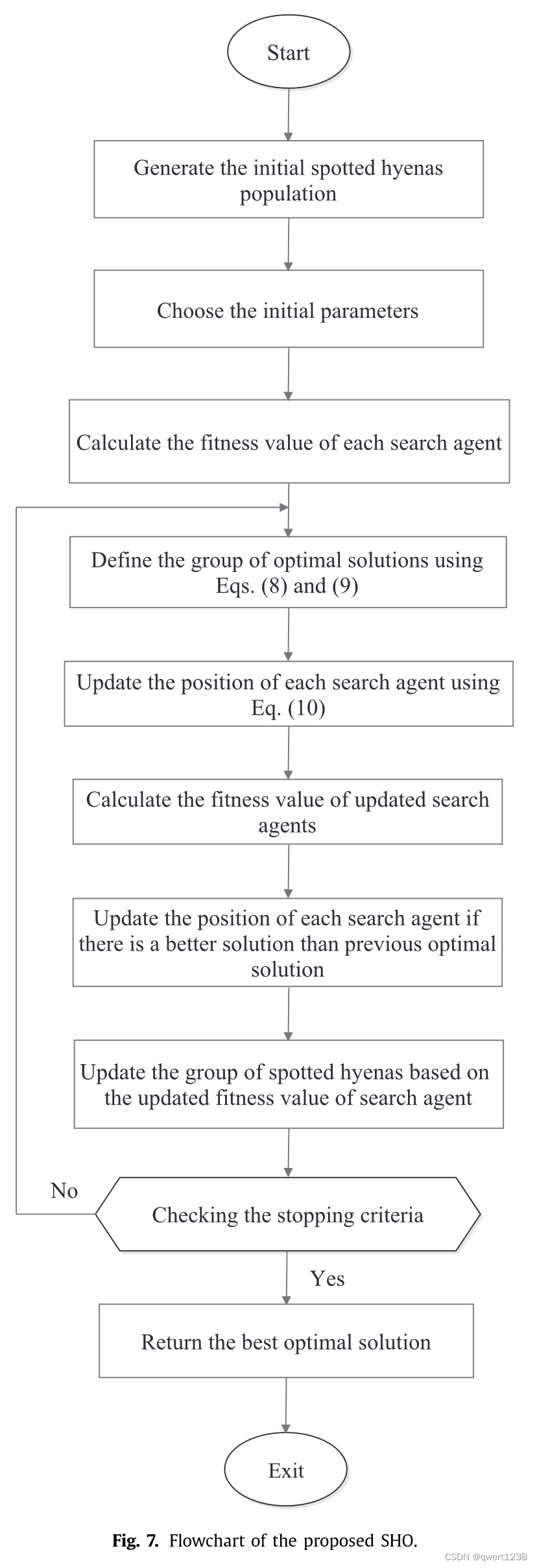
🌼2.3 SHO的步骤和流程
SHO的步骤总结如下:
步骤1:初始化斑点鬣狗种群Pi,其中i = 1,2,..,n。
步骤2:选择SHO的初始参数:h、B、E、N,并定义最大迭代次数。
步骤3:计算每个搜索代理的适应度值。
第四步:在给定的搜索空间中探索最优的搜索代理。
步骤5:定义最优解组,即利用等式进行聚类。( 8 )和( 9 )直到找到满意的结果.
步骤6:利用式( 6 )更新搜索代理的位置。( 10 ) .
步骤7:在给定的搜索空间中,检查搜索代理是否越界,并进行调整。
步骤8:计算更新搜索代理适应度值,如果存在比先前最优解更优的解,则更新向量Ph。
步骤9:更新斑点鬣狗群体
,更新搜索代理适应度值。
步骤10:如果满足停止准则,则停止算法。否则,返回步骤5。
步骤11:在满足停止准则后,返回最优解,至此得到。

🌼2.4 计算复杂度
本小节对所提算法的计算复杂度进行了讨论。所提算法的时间复杂度和空间复杂度如下所示(图7 )。
🌼2.4.1 时间复杂度
1 . SHO种群的初始化需要O( n × dim)次,其中n表示根据测试函数的搜索代理数、下界和上界生成随机种群的迭代次数。然而,dim表示测试函数的维度,用于检查和调整超出搜索空间的解。
2 .在下一步中,每个智能体的适应度需要O( Maxiter × n × dim)次,其中Maxiter为最大迭代次数,以模拟提出的算法。
3 .其中Maxiter是算法的最大迭代次数,N是斑点鬣狗的计数值,需要O( Maxiter × N)时间来定义斑点鬣狗的群体。
4 .重复步骤2和步骤3,直到找到满意的结果,所需时间为O ( k )。
因此,第二步和第三步的总复杂度为O( n × Maxiter × dim × N)。因此,SHO算法的整体时间复杂度为O( k × n × Maxiter × dim × N)。
🌼2.4.2 空间复杂性
SHO算法的空间复杂度是在其初始化过程中考虑的任意时刻所使用的最大空间量。因此,SHO算法的总空间复杂度为O( n × dim)。
参考文献:African vultures optimization algorithm: A new nature-inspired metaheuristic algorithm for global optimization problems

















 1449
1449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









