







一、原理
Tensorboard是通过读取日志文件, 绘制图结构和一些scalar变量的。
如果每次运行都在同一个日志文件,那么Tensorboard会将其合并起来,因此需要使用不同的日志文件。
二、图例意义
- 空心椭圆
操作 - 矩阵
命名空间 - 空心圆圈
常量 - 实线箭头
数据流 - 虚线箭头
依赖
二、设置不同的日志文件
这里用时间戳来设置。
from datetime import datetime
now = datetime.utcnow().strftime("%Y%m%d%H%M%S")
root_logdir = "tf_logs"
logdir = "{}/run-{}/".format(root_logdir, now)
三、记录统计相关变量
构建阶段结束后才统计的。
X = tf.placeholder(tf.float32, shape=(None, n + 1), name="X")
y = tf.placeholder(tf.float32, shape=(None, 1), name="y")
theta = tf.Variable(tf.random_uniform([n + 1, 1], -1.0, 1.0, seed=42), name="theta")
y_pred = tf.matmul(X, theta, name="predictions")
error = y_pred - y
mse = tf.reduce_mean(tf.square(error), name="mse")
optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
training_op = optimizer.minimize(mse)
init = tf.global_variables_initializer()
上面是网络的构建阶段,接下来就是Tensorboard相关操作。
mse_summary = tf.summary.scalar('MSE', mse)
file_writer = tf.summary.FileWriter(logdir, tf.get_default_graph())
注意:mse之前网络构建阶段就定义了,这里只不过在tf.summary.scalar又重新记录了。
with tf.Session() as sess:
sess.run(init)
for epoch in range(n_epochs):
for batch_index in range(n_batches):
X_batch, y_batch = fetch_batch(epoch, batch_index, batch_size)
if batch_index % 10 == 0:
summary_str = mse_summary.eval(feed_dict={X: X_batch, y: y_batch})
step = epoch * n_batches + batch_index
file_writer.add_summary(summary_str, step)
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
可以看出mse_summary.eval() 和 training_op的更新是分离开的。
add_summary(self, summary, global_step=None)这是add_summary的函数定义。
如果每个batch都记录一次训练数据,那么会影响训练速度的。
注意:summary_mse得到的是byte流,而mse得到的是确定的值。**
mse = tf.reduce_mean(tf.square(error), name="mse")
mse_summary = tf.summary.scalar('MSE', mse)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# 下面这两个是有区别的。
summary_mse = mse_summary.eval(feed_dict={X: X_batch, y: y_batch})
mse = mse.eval(feed_dict={X: X_batch, y: y_batch})
3.1 快捷记录全部summary指标
如果summary指标太多,一一列出显得繁琐。
此时可以使用tf.summary.merge_all函数整理所有的日志生成操作。
运行时只需要执行一次,就能把所有日志写入文件。
merged = tf.summary.merge_all()
with tf.Session() as sess:
summary_writer = tf.summary.FileWriter(SUMMARY_DIR, sess.graph)
sess.run(tf.global_variables_initializer())
for _ in range(5):
summary, _ = sess.run([merged, train_step], feed_dict={x: xs, y_: ys})
summary_writer.add_summary(summary, i)
四、关闭读写流
file_writer.close()
五、使用Tensorboard查看网络图和变量
windows: 在cmd中输入:
tensorboard --logdir ./log
./log是存放log的地址。
然后cmd中会输出一个地址, 复制该地址到chrome中即可查看。
如果该地址打不开,可以尝试指定host。
tensorboard --logdir ./log --host=127.0.0.1
六、tensorboard同时显示训练曲线和测试曲线
# 使用的时候
train_log = 'log/train/'
dev_log = 'logs/dev/'
megred = tf.summary.merge_all()
with tf.Graph().as_default():
train_summary = tf.summary.FileWriter(train_log, tf.get_default_graph())
dev_summary = tf.summary.FileWriter(dev_log)
with tf.Session() as sess:
train_summary_losses = tf.summary.scalar('loss', losses)
dev_summary_losses = tf.summary.scalar('loss', losses)
[......]
train_losses = sess.run(train_summary_losses, feed={X: train_data, Y:train_labels})
dev_losses = sess.run(dev_summary_losses, feed={X: dev_data, Y:dev_labels})
train_summary.add_summary(train_losses, step)
dev_summary.add_summary(dev_losses, step)
七、分析各个操作耗费时间和内存
7.1 代码:
for epoch in range(epoches):
for step in range(steps):
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
run_metadata = tf.RunMetadata()
_, loss = sess.run([g.train_op, g.global_loss],
feed_dict={g.x: X_train, g.y: Y_train},
options=run_options, run_metadata=run_metadata)
train_summay.add_run_metadata(run_metadata=run_metadata, tag="step:{}".format(step))
注意:Tag参数必须唯一,否则会报错。
7.2 具体操作:
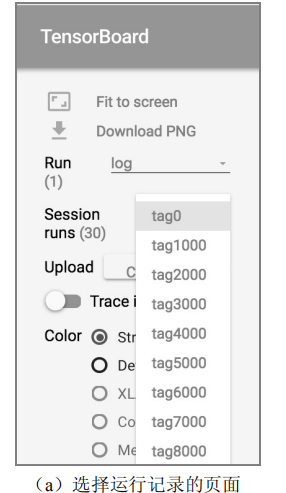
1、点击页面左侧的 Session runs 选项,这时就会出现一个下拉单,在这个下拉单中会出现所有通过train_summary.add_run_metadata 函数记录的运行数据。

2、经过1操作后,Color栏中Compute time和Memory这两个选项可以被选择。
在Color 栏中选择 Compute time 可以看到在这次运行中每个 TensorFlow 计算节点的运行时间。类似的,选择 Memory 可以看到这次运行中每个 TensorFlow 计算节点所消耗的内存。
图中颜色越深的节点表示时间消耗越大。
在性能调优时,一般会选择迭代轮数较大时的数据作为不同计算节点时间/空间消耗的标准,这样可以减少Tensorflow初始化对性能的影响。















 8103
8103











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









