






SMOTE算法过采样
解决类不平衡问题,用于机器学习的分类问题
========================
SMOTE是一种综合采样人工合成数据算法,用于解决数据类别不平衡问题(Imbalanced class problem),以Over-sampling少数类和Under-sampling多数类结合的方式来合成数据。
案例数据中前9列为特征变量,最后一列为类别标签
按相应格式准备自己数据即可,运行后输出新数据到excel
Matlab代码,main为主程序,备注清晰,有助于新手使用(不适于不同类别差别太大的数据)
(Example_22)
ID:7630659920547734
Matlab编程
SMOTE算法过采样:解决机器学习中的类不平衡问题
在机器学习的分类问题中,经常会遇到类别不平衡的情况,即其中一个类别的样本数量远远超过另一个类别的样本数量。这种不平衡的数据分布会对分类器的训练和性能产生负面影响,导致分类结果偏向样本数量较多的类别。为了解决这个问题,研究人员提出了多种方法,其中之一就是SMOTE算法。
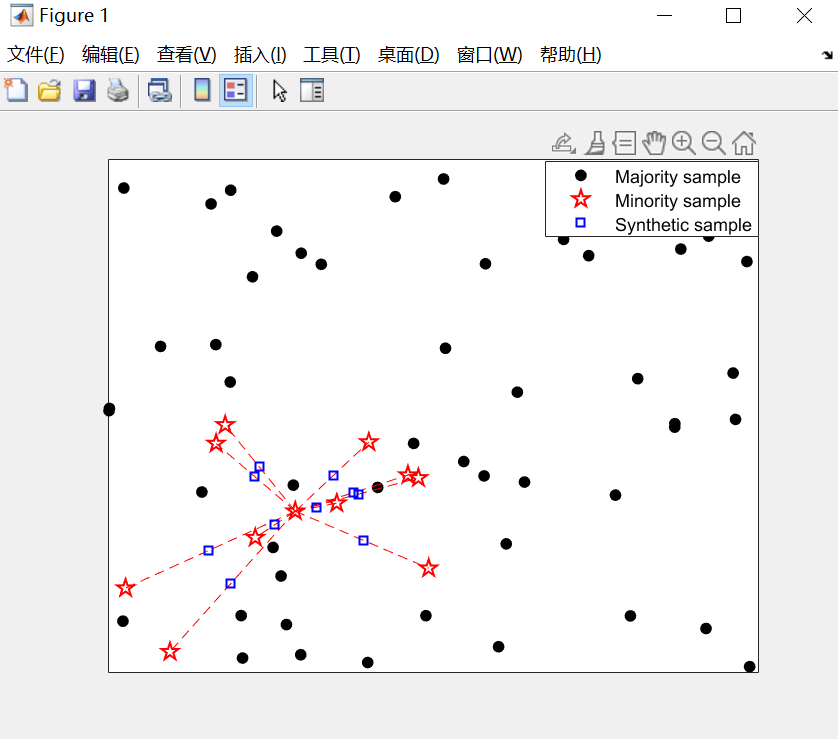
SMOTE算法(Synthetic Minority Over-sampling Technique)是一种综合采样人工合成数据算法,它通过合成新的少数类样本来平衡数据集中各个类别的样本数量。SMOTE算法的基本思想是对少数类样本进行插值,生成一些与原始样本相似但不同的合成样本,从而扩充少数类样本的数量。
下面我们以一个案例来说明SMOTE算法在解决类不平衡问题上的应用。
假设我们有一个数据集,其中前9列为特征变量,最后一列为类别标签。我们按照相应的格式准备好自己的数据,并且使用Matlab编写SMOTE算法的主程序(名为main)来实现:
% main.m
% 加载数据
data = load('data.txt');
X = data(:, 1:9); % 特征变量
y = data(:, end); % 类别标签
% 运行SMOTE算法进行过采样
newData = smote(X, y); % smote函数是SMOTE算法的具体实现,具体细节不在本文讨论范围内
% 将新数据输出到excel
xlswrite('new_data.xlsx', newData);
在上述代码中,我们首先加载了数据,然后将特征变量和类别标签分开。接下来,我们调用了一个名为smote的函数,该函数是SMOTE算法的具体实现。为了简化说明,我们并没有在本文中提供具体的SMOTE算法代码,但是可以在互联网上找到很多开源实现的代码,供读者参考。最后,我们将合成的新数据输出到一个名为new_data.xlsx的Excel文件中。
需要注意的是,SMOTE算法适用于数据类别之间差异不大的情况。如果数据类别之间差异较大,SMOTE算法可能会导致合成的新样本过于接近少数类,从而引入噪声和错误分类。对于这种情况,需要结合其他方法进行处理,例如基于距离的采样方法或集成学习算法等。
总结起来,SMOTE算法是一种用于解决机器学习中类不平衡问题的有效方法。通过合成新的少数类样本,可以平衡数据集中各个类别的样本数量,提升分类器的训练和性能。在实际应用中,我们可以根据自己的数据格式和需求,编写相应的代码来实现SMOTE算法,并将合成的新数据输出到Excel或其他格式的文件中。
希望本文对读者理解和应用SMOTE算法有所帮助。当然,除了SMOTE算法,还有其他一些方法可以用于解决类不平衡问题,读者可以进一步研究和探索。
相关的代码,程序地址如下:http://coupd.cn/659920547734.html
















 596
596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









