







目录
一、事务
事务: 指的是逻辑上的⼀组操作,组成这组操作的各个单元要么全都成功,要么全都失败
事务作⽤:保证在⼀个事务中多次SQL操作要么全都成功,要么全都失败.
比如:银行转账,小明有50元,小红有10元,小明向小红转账10元,在数据库操作中相当于执行了两条SQL语句。如果不同时成功或失败,那么转账系统将会出问题
UPDATE account SET money=money-10 WHERE id=1;-- 小明账户减10元
UPDATE account SET money=money+10 WHERE id=2;-- 小红账户加10元
想让这两个操作要么全成功,要么全失败。如何保证呢?就需要把他们放到同一个事务里面进行操作。
在datagrip上执行:
# 创建账号表
create table account(
id int primary key auto_increment COMMENT '主键',
name varchar(20) COMMENT '姓名',
money double COMMENT '余额'
);
# 初始化数据
insert into account values (1,'小明',50);
insert into account values (2,'小红',10);
自动提交事务功能的开启与关闭
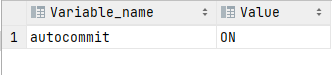
MySQL有一个系统变量autocommit,用来自动提交事务
SHOW VARIABLES LIKE 'autocommit';
默认是开启的也
就意味着在默认情况下,如果不显示地执行 START TRANSACTION 或者 BEGIN 开启一个事务,
那么每条SQL语句都算是一个独立的事务,这种特性被称作事务的自动提交
如果想关闭这种自动提交的功能,可以使用两种办法
1、显式使用START TRANSACTION 或者 BEGIN 开启一个事务。这样在本次事务中提交或者回滚前会暂时关闭自动提交的u
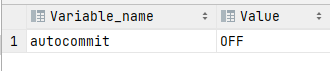
2、把系统变量 autocommit 设置为 OFF(设置开为ON)
SET AUTOCOMMIT = off;
事务的特性(ACID)
1、原子性(Atomicity)
原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚
2、一致性(Consistency)
一致性是指事务必须使数据库从一个一致性状态变换到另一个一致性状态,也就是说一个事务执行之前和执行之后都必须处于一致性状态。拿转账来说,假设用户A和用户B两者的钱加起来一共是5000,那么不管A和B之间如何转账,转几次账,事务结束后两个用户的钱相加起来应该还得是5000,这就是事务的一致性。
3、隔离性(Isolation)
隔离性是当多个用户并发访问数据库时,比如操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。一个事务的执行不能被其他事务干扰。一个事务内部的操作及使用的数据,对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。关于事务的隔离性数据库提供了多种隔离级别。
4、持久性(Durability)
持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。(相当于把数据已经写到硬盘里,关不关机不改变结果)
1、事务回滚
在虚拟机上登录数据库,各种步骤在这里就不列举了,看前面的文章吧

开启一个事务:
begin;

rollback; # 此指令可将之前的操作恢复原样
2、事务提交
commit;

3、隐式提交
当使用start transaction或者begin语句时开启了一个事务。或者把系统变量的值设置为off时,事物就不会进行自动提交。如果输入了某些语句,且这些语句会导致之前的事物,悄悄的提交(就像输入了commit命令一样),那么因为某种特殊的语句而导致,事务提交的情况称为隐式提交。
会导致隐式提交的语句有:
1、数据库定义语言DDL,像create、alter、drop
2、务控制或关于锁定的语句,比如,前一个事务未提交,又开启了一个新的事务
3、加载数据的语句,比如load data
4、关于MySQL复制的一些语句 :slave
保存点
如果已经开启了一个事物,并且输入了很多语句,这是忽然发现前面已经执行完的某个语句。
参数写错了,只好使用rollback语句,让数据库状态恢复到事务执行之前的样子,然后一切从头再来。
这种感觉很不爽,因此就有了保存点的概念。
语法:
-- 定义保存点
savepoint 保存点名称;
-- 回滚到某个保存点,如果rollback后面不跟随保存点名称,则直接回滚到事务之前的状态
rollback [work] to [savepoint] 保存点名称 ;
-- 删除保存点
release savepoint 保存点名称;

二、索引
索引用于快速找出在某个列中有一特定值的行。
不使用索引,MySQL必须从第1条记录开始读完整个表,直到找出相关的行。
表越大,查询数据所花费的时间越多,如果表中查询的列有一个索引,MySQL能快速到达。
某个位置去搜寻数据文件,而不必查看所有的数据,就是与索引相关的内容。
索引是对数据库中一列或多列的值进行排序的一种结构,使用索引可提高数据库中特定数据的查询速度。
索引是一个单独的存储在磁盘上的数据库结构,包含着对数据表里所有记录的引用指针。
使用索引可以快速找出在某个或多个列中的某个值。
所有MySQL列类型都可以被索引,对相关列使用索引是提高查询操作速度的最佳途径。
索引是在存储引擎中实现的,因此每一种存储引擎的索引,都不一定完全相同。
1、索引分类
(1)普通索引和唯一索引
普通索引是MySQL中的基本索引类型,允许在定义索引的列中插入重复值和空值。
唯一索引要求索引列的值必须唯一,但允许有空值。
如果是组合索引,则列值的组合,必须唯一。
主键索引是一种特殊的索引唯一,不允许有空值。
(2)单列索引和组合索引
单列索引及一个索引只包含单个列,一个表可以有多个单列索引。
组合索引是指在表的多个字段组合上创建的索引,只有在查询条件中使用了这些字段的左边字段时,索引才会被使用。
使用组合索引时遵循最左前缀原则。
2、创建索引
(1)创建表时创建
普通索引:
CREATE TABLE book(
id int AUTO_INCREMENT PRIMARY KEY ,
bookname varchar(255) NOT NULL ,
INDEX (bookname) # 创建普通索引
);

唯一索引:
CREATE TABLE book2(
id int AUTO_INCREMENT PRIMARY KEY ,
bookname varchar(255) NOT NULL ,
UNIQUE INDEX (bookname) # 创建唯一索引
);

给索引起名字:
CREATE TABLE book3(
id int AUTO_INCREMENT PRIMARY KEY ,
bookname varchar(255) NOT NULL ,
UNIQUE INDEX name_idx (bookname) # 设定索引名字
);

注意:index 和key是等价的
(2)单独创建索引
普通索引:
CREATE INDEX index_name
ON table_name (column_name);
唯一索引:
CREATE UNIQUE INDEX index_name
ON table_name (column_name);
组合索引:
CREATE INDEX index_name
ON table_name (column_name1,column_name2);
(3)修改表结构创建
ALTER TABLE table_name ADD INDEX name_idx(column_name);
3、删除索引
ALTER TABLE table_name DROP INDEX index_name;
DROP INDEX index_name ON table_name;















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









