




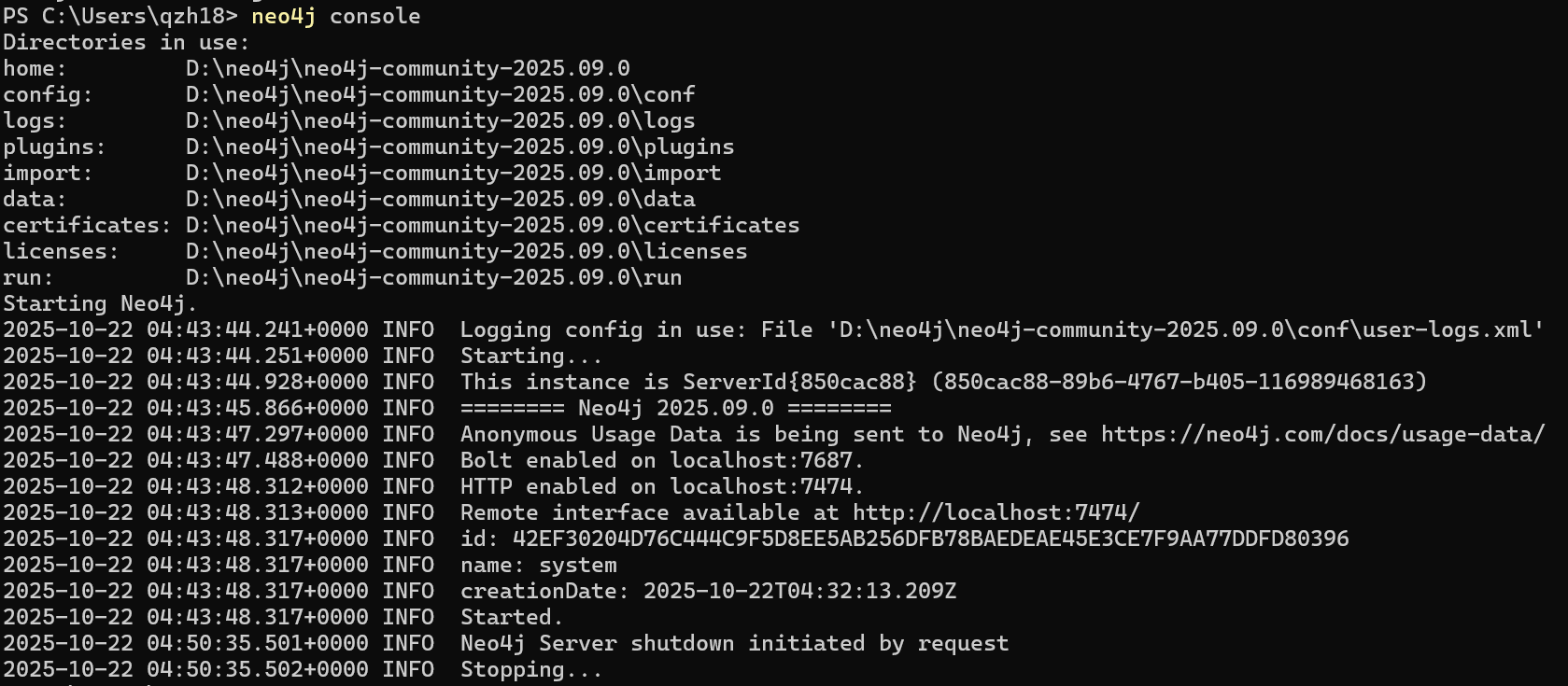
安装
目录说明:
bin:存放启动 / 停止数据库的脚本(如 neo4j.bat 是 Windows 启动脚本);
conf:核心配置文件目录(重点修改 neo4j.conf);
data:存储数据库数据(节点、关系等);
logs:日志文件目录(排查错误用)。
neo4j
一、概念
neo4j 基本操作元素
neo4j可支持语言:.NET、Java、Spring、JavaScript、Python、Ruby、PHP、R、Go、C / C++、Clojure、Perl、Haskell
几个专有名词:变量(标识符)、节点、关系、实体、标签、属性、索引、约束。
实体包括节点和关系
在操作前,先记住Neo4j的3个核心组件,后续所有操作都围绕它们:
- 节点(Node):代表“实体”,比如“人”“电影”,可添加属性(如姓名、年龄、电影名)。
- 关系(Relationship):连接两个节点,代表“关联”,比如“看过”“导演”,也可加属性(如评分、观看时间)。
- 属性(Property):键值对形式,附着在节点或关系上,比如
name: "张三"、score: 9.2。
二、步骤1:创建节点与关系(用Cypher构建数据)
1.1 创建单个节点(带属性)
在Web界面的输入框中输入以下语句,点击右上角“▶️”执行(执行后会显示创建的节点):
# 创建“人物”节点:姓名张三,年龄28,职业程序员
CREATE (p:Person {name: "张三", age: 28, job: "程序员"})
RETURN p; # RETURN 用于显示创建的结果
- 解释:
(p:Person)中,p是节点的“变量名”(方便后续引用),:Person是节点的“标签”(类似分类,比如“人物”类节点)。
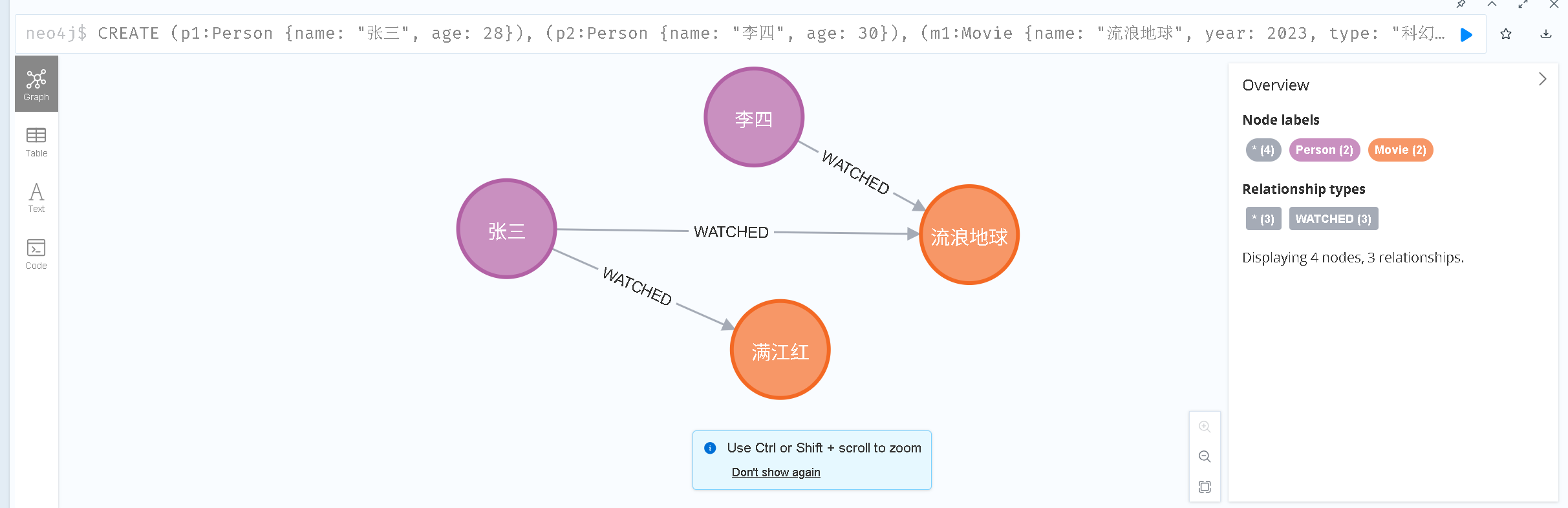
1.2 批量创建节点与关系(一次性构建关联)
用CREATE同时创建多个节点和它们的关系,更高效:
# 批量创建:2个人物、2部电影,以及“看过”关系(带评分属性)
CREATE
(p1:Person {name: "张三", age: 28}),
(p2:Person {name: "李四", age: 30}),
(m1:Movie {name: "流浪地球", year: 2023, type: "科幻"}),
(m2:Movie {name: "满江红", year: 2023, type: "悬疑"}),
(p1)-[r1:WATCHED {score: 9.0}]->(m1), # 张三看过流浪地球,评分9.0
(p1)-[r2:WATCHED {score: 8.5}]->(m2), # 张三看过满江红,评分8.5
(p2)-[r3:WATCHED {score: 8.8}]->(m1) # 李四看过流浪地球,评分8.8
RETURN p1, p2, m1, m2, r1, r2, r3;
- 执行后,界面会显示“节点+关系”的图形化结果:两个橙色
Person节点、两个蓝色Movie节点,以及连接它们的WATCHED关系。
三、步骤2:基础查询(用MATCH找数据)
查询是Neo4j的核心,用MATCH语句“匹配”图中的节点/关系,再用WHERE过滤条件、RETURN显示结果。
2.1 查询所有节点(查看数据库现有数据)
# 匹配所有节点(n是变量名,代表任意节点),返回节点和它的标签
MATCH (n)
RETURN n, labels(n) AS node_label; # labels(n) 用于显示节点的标签(如Person/Movie)
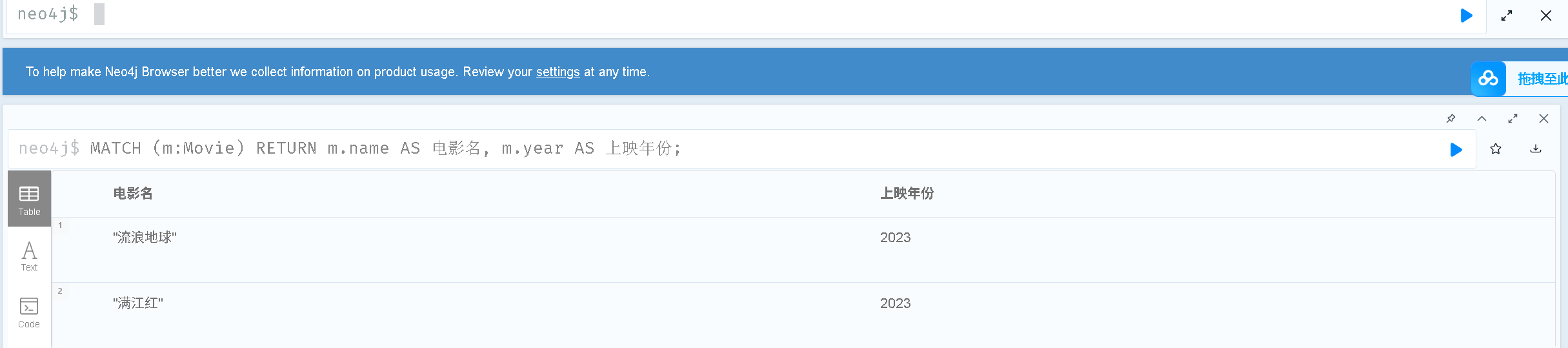
2.2 按标签查询节点(过滤分类)
# 查询所有“电影”节点,只返回电影名和年份
MATCH (m:Movie) # 只匹配标签为Movie的节点
RETURN m.name AS 电影名, m.year AS 上映年份;
2.3 按关系查询(找关联数据,核心功能)
这是图数据库的优势——快速查“关系链”,比如“找所有看过《流浪地球》的人”:
# 匹配“人-看过-流浪地球”的关系链
MATCH (p:Person)-[r:WATCHED]->(m:Movie {name: "流浪地球"})
RETURN p.name AS 观众姓名, r.score AS 评分, m.name AS 电影名;
- 结果会显示:张三(评分9.0)、李四(评分8.8),以及对应的电影信息。
2.4 带条件过滤的查询(用WHERE缩小范围)
比如“找年龄大于28岁、且给电影评分≥8.8的人”:
MATCH (p:Person)-[r:WATCHED]->(m:Movie)
WHERE p.age > 28 AND r.score >= 8.8 # 过滤条件:年龄>28且评分≥8.8
RETURN p.name AS 姓名, p.age AS 年龄, m.name AS 电影名, r.score AS 评分;
- 结果会显示:李四(30岁,给《流浪地球》评8.8分)。

四、步骤3:修改与删除数据(完善数据管理)
3.1 修改属性(更新数据)
比如“将张三的年龄改为29岁,给《满江红》的评分改为8.6”:
# 先匹配到张三和他与满江红的关系,再更新属性
MATCH (p:Person {name: "张三"})-[r:WATCHED]->(m:Movie {name: "满江红"})
SET p.age = 29, r.score = 8.6 # SET 用于修改属性
RETURN p.name, p.age, r.score, m.name;

3.2 删除节点/关系(注意:删除节点前必须先删关联的关系)
# 1. 先删除李四与所有电影的关系(避免删节点时报错)
MATCH (p:Person {name: "李四"})-[r:WATCHED]->()
DELETE r;
# 2. 再删除李四节点
MATCH (p:Person {name: "李四"})
DELETE p;
# 验证:查询所有节点,确认李四已被删除
MATCH (n) RETURN n;
五、进阶:常用Cypher语法速查(备查)
| 功能 | 关键字 | 示例 |
|---|---|---|
| 创建数据 | CREATE | CREATE (p:Person {name: "王五"}) |
| 查询数据 | MATCH | MATCH (m:Movie) RETURN m.name |
| 过滤条件 | WHERE | WHERE m.year = 2023 |
| 修改属性 | SET | SET p.age = 30 |
| 删除数据 | DELETE | DELETE p(删节点)、DELETE r(删关系) |
| 统计数量 | COUNT() | MATCH (p:Person) RETURN COUNT(p) |
| 排序 | ORDER BY | MATCH (m:Movie) RETURN m.name ORDER BY m.year DESC |
与python结合的py2neo使用教程
Py2neo 是一个用于与 Neo4j 图数据库进行交互的 Python 库。它提供了简洁、直观的 API,方便开发者在 Python 环境中对 Neo4j 数据库进行各种操作,包括创建节点、关系、路径、子图,执行事务,以及进行查询、更新、删除等操作。
通过 Py2neo,开发者可以无需直接编写复杂的 Cypher 语句(当然也支持执行 Cypher 语句),而是通过 Python 代码中的类和方法来操作 Neo4j 图数据库,大大降低了使用 Neo4j 的门槛,尤其适合熟悉 Python 的开发者。
参考资料
https://zhuanlan.zhihu.com/p/436687958
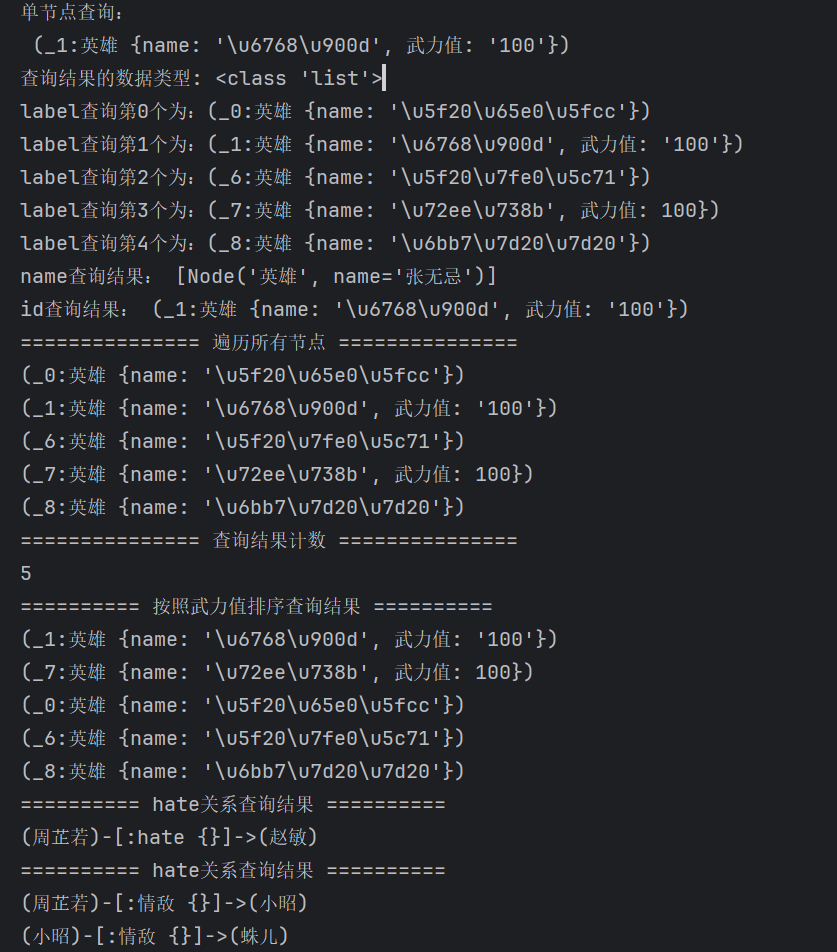
1. 连接数据库与初始化
test_graph = Graph("http://localhost:7474", auth=("neo4j", "new_password"))
test_graph.delete_all() # 清空数据库中已有数据
test_graph=Graph("bolt://localhost:7687", auth=("neo4j", "new_password"))
. 强制使用 Bolt 协议连接(必做)
Bolt 协议(7687 端口)是 Neo4j 推荐的连接方式,兼容性更好。修改代码中的连接地址:
2. 节点与关系的创建
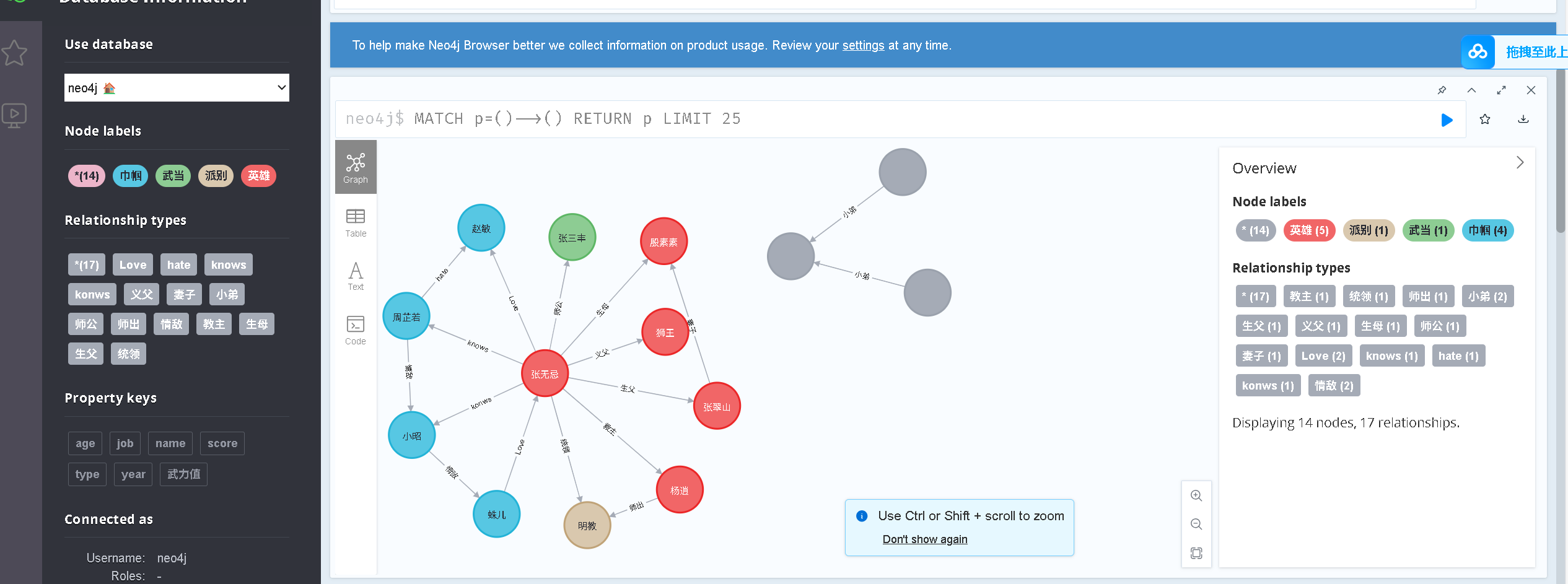
- 创建单个节点并添加到数据库
node_1 = Node('英雄', name='张无忌') test_graph.create(node_1) - 创建节点间的关系并添加到数据库
node_1_to_node_2 = Relationship(node_1, '教主', node_2) test_graph.create(node_1_to_node_2)
3. 路径(Path)的创建
node_4, node_5, node_6 = Node(name='阿大'), Node(name='阿二'), Node(name='阿三')
path_1 = Path(node_4, '小弟', node_5, Relationship(node_6, "小弟", node_5), node_6)
test_graph.create(path_1) # 一次性创建路径中的节点和关系
4. 子图(Subgraph)的创建
subgraph_1 = Subgraph(nodes=[node_7, node_8, node_9],
relationships=[relationship7, relationship8, relationship9])
test_graph.create(subgraph_1) # 批量创建子图中的节点和关系
5. 事务(Transaction)操作
transaction_1 = test_graph.begin() # 开启事务
transaction_1.create(node_10) # 在事务中创建节点
transaction_1.create(relationship_10) # 在事务

















 2633
2633

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









