







学习了哈弗曼树之后做了一个小项目—文件压缩,最近在复习,就顺便把项目也再梳理一遍。
1)首先是哈弗曼树的原理:
如果有一些结点的权值分别是1,2,3,4,5,6
那么它们构建出来的哈弗曼树是什么样子呢?
结果如图:
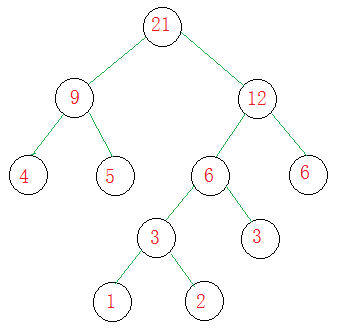
思想是每次从数组中取两个当前权值最小的数去创建结点,并作为叶子结点,它们的根节点的权值是两者之和,把它再放回数组,第一次选择1,2;第二次选择3,3;第三次选择4,5;~~~~
2)哈弗曼树的构建:
因为要每次选择最小的两个数,自然想到要用堆啦~堆的代码以前实现过的,直接头文件加进来用,但是问题就来了,这里要用小堆,所以要用<,
堆里面是结点,可要比较的是结点的权值大小,以前实现的堆对直接用堆里面的数据去比较大小的,所以就要去重写一下传到堆里面的那个仿函数啦~
3)文件压缩的原理:
哈弗曼树建好,现在要正式开始文件压缩啦~
文件压缩真正要用到的是哈夫曼编码,还是刚才那棵树,它的哈弗曼编码怎么来的呢?
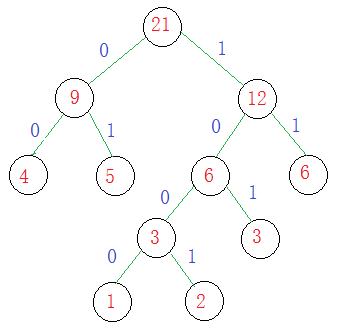
权值为1的结点的哈夫曼编码就是1000
权值为2的结点的哈夫曼编码就是1001
权值为3的结点的哈夫曼编码就是101
权值为4的结点的哈夫曼编码就是00
权值为5的结点的哈夫曼编码就是01
权值为6的结点的哈夫曼编码就是11
哈夫曼编码只是对叶子节点编码哦~~~
可以发现一个规律就是权值越小的,它的哈夫曼编码越长,权值越大的,哈夫曼编码越短。
那么如何运用到文件压缩中呢?
举一个简单的例子吧,假设有一个文件的内容是“abbcccdddd“,‘a’出现的次数是1,‘b’出现的次数是2,‘c’出现的次数是3,‘d’出现的次数是4,以各字符出现的次数构建一个哈夫曼树,并为各字符编码,结果是:
‘a’:100; ‘b’:101; ‘c’:11; ‘d’:0;
以编码的形式按照原字符的顺序写入压缩文件,就应该是这样滴:
1001011011111110000
这一个0或1代表一个二进制位,那压缩文件是多大呢?3个字节
原文件是多大呢?10个字节
这就是文件压缩的原理。
4)文件压缩的过程:
根据上面的例子,首先要统计待压缩文件中各字符出现的次数,然后构造哈弗曼编码,把编码写入压缩文件,不够一个字节的就在后面补零,因为还要解压缩,所以还得写一个配置文件,配置文件里面写每个字符出现的次数。
5)文件解压缩的过程:
先去读配置文件,构建哈弗曼树和哈弗曼编码,用压缩文件里的编码去哈弗曼树里面找,找到叶子结点,就把叶子节点的字符写入解压缩文件中。
项目测试:通过Beyond Compare对文件压缩前和压缩后的内容进行比对,验证程序的正确性。
6 )性能测试,一个25M左右的大文件,在Debug版本下压缩的时间大约为30s,解压缩时间大约为10s,压缩文件的大小为20M左右;一个6k左右的小文件在Debug版本下压缩的时间大约为30ms,解压缩时间大约为30ms,压缩文件的大小为3.5K左右;在release版本下会更高效一些,时间会缩短很多。
我的代码:https://github.com/ranxiaoxu/FileCompress
再说说项目过程中出现的问题的问题吧,我测试的时候发现如果待压缩文件中出现中文,程序就会崩溃,将错误定位到构造哈弗曼编码的函数处,通过单步调试发现是数组越界所致,终于明白是为什么了,如果只是字符的话,它的范围是0~127,程序中通过一个char类型的变量作为数组的下标,是没有问题的,但汉字的编码是两个字节,所以会发生数组越界,解决方法是将char强转为unsigned char。















 217
217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









