







1. 决策树的优缺点
优点:计算复杂度不高,输出结果易于理解,对中间值的确实不敏感,可以处理不相关特征数据
缺点:可能会产生过渡匹配问题
使用数据类型:数值型和标称型
2. 决策树的一般流程
(1)收集数据:可以使用任何方法
(2)准备数据:树构造算法只适用于标称型数据,因此数值型数据必须离散化
(3)分析数据:可以使用任何方法,构造树完成之后,我们应该检查图形是否符合预期
(4)训练算法:构造树的数据结构
(5)测试算法:使用经验树计算错误率
(6)实用算法:次步骤可以适用于任何监督学习算法,而使用据侧书可以更好地理解数据的内在含义
3. 决策树的构建
(1)信息
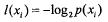
(2)熵
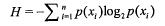
(3)信息增益:熵的变化量
(4)构建步骤

4. 样例代码
DataUtil.py
(1)用于随机生成数据集
(2)用于随机生成测试向量
(3)用于归一化
(4)用于按照比例随机切分训练集和测试集
# -*- coding: utf-8 -*-
from numpy import *
class DataUtil:
def __init__(self):
pass
def randomDataSet(self, row, column, classes):
'''rand data set'''
if row <= 0 or column <= 0 or classes <= 0:
return None, None
dataSet = random.rand(row, column)
dataLabel = [random.randint(classes)+1 for i in range(row)]
return dataSet, dataLabel
def randomDataSet4Int(self, maxinum, row, column, classes):
'''rand int data set'''
if row <= 0 or column <= 0 or classes <= 0:
return None, None
dataSet = random.randint(maxinum, size=(row, column))
dataLabel = [random.randint(classes)+1 for i in range(row)]
return dataSet, dataLabel
def file2DataSet(self, filePath):
'''read data set from file'''
f = open(filePath)
lines = f.readlines()
dataSet = None
dataLabel = []
i = 0
for line in lines:
items = line.strip().split('\t')
if dataSet is None:
dataSet = zeros((len(lines), len(items)-1))
dataSet[i,:] = items[0:-1]
dataLabel.append(items[-1])
i += 1
return dataSet, dataLabel
def randomX(self, column):
'''rand a vector'''
return random.rand(1, column)[0]
def norm(self, dataSet):
'''normalize'''
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
m = dataSet.shape[0]
return (dataSet - tile(minVals, (m, 1)))/tile(ranges, (m, 1))
def spitData(self, dataSet, dataLabel, ratio):
'''split data with ratio'''
totalSize = dataSet.shape[0]
trainingSize = int(ratio*totalSize)
testingSize = totalSize - trainingSize
# random data
trainingSet = zeros((trainingSize, dataSet.shape[1]))
trainingLabel = []
testingSet = zeros((testingSize, dataSet.shape[1]))
testingLabel = []
trainingIndex = 0
testingIndex = 0
for i in range(totalSize):
r = random.randint(1, totalSize)
if (r <= trainingSize and trainingIndex < trainingSize) or testingIndex >= testingSize:
trainingSet[trainingIndex,:] = dataSet[i,:]
trainingLabel.append(dataLabel[i])
trainingIndex += 1
else:
testingSet[testingIndex,:] = dataSet[i,:]
testingLabel.append(dataLabel[i])
testingIndex += 1
return trainingSet, trainingLabel, testingSet, testingLabel
DecisionTree.py
(1)决策树的实现
# -*- coding: utf-8 -*-
from numpy import *
from operator import *
class DecisionTree:
def __init__(self):
pass
def calcShannonEnt(self, dataSet):
'''calculate shannon ent'''
n = len(dataSet)
# calculate label counts
labelCounts = {}
for vec in dataSet:
if vec[-1] not in labelCounts.keys():
labelCounts[vec[-1]] = 0
labelCounts[vec[-1]] += 1
# calculate shannonEnt
shannonEnt = 0.0
for label in labelCounts.keys():
p = float(labelCounts[label]) / n
shannonEnt -= p * math.log(p, 2)
return shannonEnt
def splitDataSet(self, dataSet, axis, value):
'''split data set'''
subDataSet = []
if axis >= dataSet.shape[1] - 1:
return dataSet
for vec in dataSet:
if vec[axis] == value:
tmp = concatenate((vec[:axis], vec[axis+1:]))
subDataSet.append(tmp)
return array(subDataSet)
def chooseBestFeatureToSplit(self, dataSet):
'''choose the best feature to split data set'''
m = len(dataSet[0]) - 1
shannonEnt = self.calcShannonEnt(dataSet)
bestIndex = -1
bestInfoGain = 0
for i in range(m):
values = [vec[i] for vec in dataSet]
uniqValues = set(values)
newShannonEnt = 0
for value in uniqValues:
subDataSet = self.splitDataSet(dataSet, i, value)
p = len(subDataSet)*1.0/len(dataSet)
newShannonEnt += p * self.calcShannonEnt(subDataSet)
infoGain = shannonEnt - newShannonEnt
# print 'shannonEnt=%d, newShannonEnt=%d' % (shannonEnt, newShannonEnt)
# print '%d, infoGain=%d' % (i, infoGain)
if infoGain > bestInfoGain:
bestIndex = i
bestInfoGain = infoGain
return bestIndex
def majorCnt(self, dataSet):
if dataSet.shape[0] == 0 or dataSet.shape[1] == 0:
return -1
labelCounts = {}
for vec in dataSet:
if vec[-1] not in labelCounts.keys():
labelCounts[vec[-1]] = 0
labelCounts[vec[-1]] += 1
sortedCounts = sorted(labelCounts.iteritems(), key=itemgetter(1), reverse=True)
return sortedCounts[0][0]
def buildTree(self, dataSet, featureNames):
labels = [vec[-1] for vec in dataSet]
if labels.count(labels[0]) == len(dataSet):
return labels[0]
if dataSet.shape[1] == 1:
return self.majorCnt(dataSet)
bestFeature = self.chooseBestFeatureToSplit(dataSet)
# print 'ddd:'
# print dataSet
if bestFeature == -1:
return self.majorCnt(dataSet)
bestFeatureName = featureNames[bestFeature]
# print 'bestFeature=%s' % bestFeatureName
tree = {bestFeatureName: {}}
values = [vec[bestFeature] for vec in dataSet]
uniqValues = set(values)
del(featureNames[bestFeature])
for value in uniqValues:
subDataSet = self.splitDataSet(dataSet, bestFeature, value)
subFeatureNames = featureNames[:]
tree[bestFeatureName][value] = self.buildTree(subDataSet, subFeatureNames)
return tree
def classify(self, tree, featureNames, x):
firstStr = tree.keys()[0]
secondDict = tree[firstStr]
index = featureNames.index(firstStr)
for key in secondDict.keys():
if x[index] == key:
if type(secondDict[key]).__name__ == 'dict':
label = self.classify(secondDict[key], featureNames, x)
else:
label = secondDict[key]
return label
def storeTree(self, tree, filePath):
import pickle
fw = open(filePath, 'w')
pickle.dump(tree, fw)
fw.close()
def loadTree(self, filePath):
import pickle
fr = open(filePath)
return pickle.load(fr)
Test4dt.py
(1)用于测试决策树算法
# -*- coding: utf-8 -*-
from DataUtil import *
from DecisionTree import *
from matplotlib import pyplot
def decisionTree():
# variables definition
MAX_FEATURE_VALUE = 2
ROW = 5
COLUMN = 3
CLASS_COUNT = 3
# random data
dt = DecisionTree()
dataUtil = DataUtil()
dataSet, dataLabel = dataUtil.randomDataSet4Int(MAX_FEATURE_VALUE, ROW, COLUMN, CLASS_COUNT)
for i in range(ROW):
dataSet[i][-1] = dataLabel[i]
featureNames = ['feature%d' % i for i in range(COLUMN-1)]
print 'dataSet:'
print dataSet
print 'dataLabel:'
print dataLabel
# plot the data
fig = pyplot.figure()
ax = fig.add_subplot(111)
ax.scatter(dataSet[:,0], dataSet[:,1], 15*array(dataLabel), 15*array(dataLabel))
# pyplot.show()
# build decision tree
print dt.buildTree(dataSet, featureNames)
if __name__ == '__main__':
decisionTree()















 484
484











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









