







JAVA 应用必须通过 JDBC 从数据库中取数,有时候我们会发现,数据库的负担一点也不重而且 SQL 很简单,但取数的速度仍然很慢。仔细测试会发现,性能瓶颈主要在 JDBC 上,比如 MySQL 的 JDBC 性能就非常差,Oracle 也不好。但是,JDBC 是数据库厂商提供的包,我们在外部没办法提高性能。
可以想到的办法是利用多 CPU 手段采用并行方案来提速,但 Java 的并行程序非常难写,要考虑资源共享冲突等麻烦事务。
下面介绍使用集算器的并行技术来提升数据库 JDBC 取数性能,可以避免 JAVA 硬编码的复杂性,还能够方便实现多线程结果集的合并。适用于:
- 源数据规模较大的查询报表
- 多数据集报表
- ETL 数据抽取
集算器并行配置
通过集算器进行并行取数前需要配置集算器的并行属性。IDE 中通过菜单“工具 - 选项”设置 IDE 支持的最大并行数量,一般建议最大并行数不要超过 CPU 核数。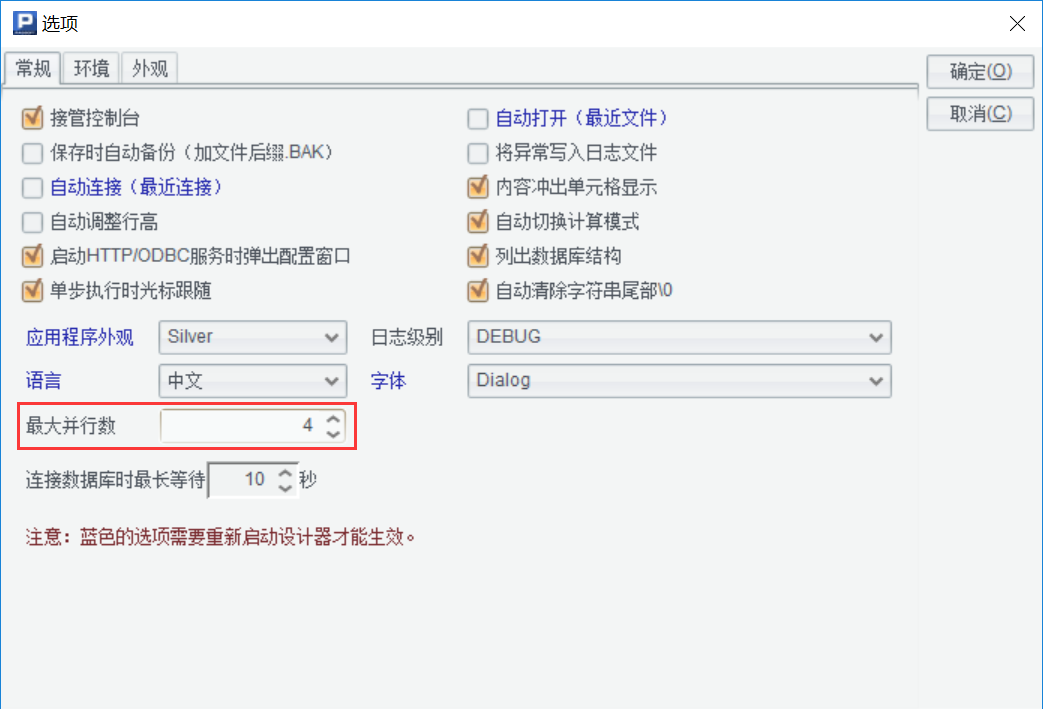
集算器服务端则需要修改 raqsoftConfig.xml 配置: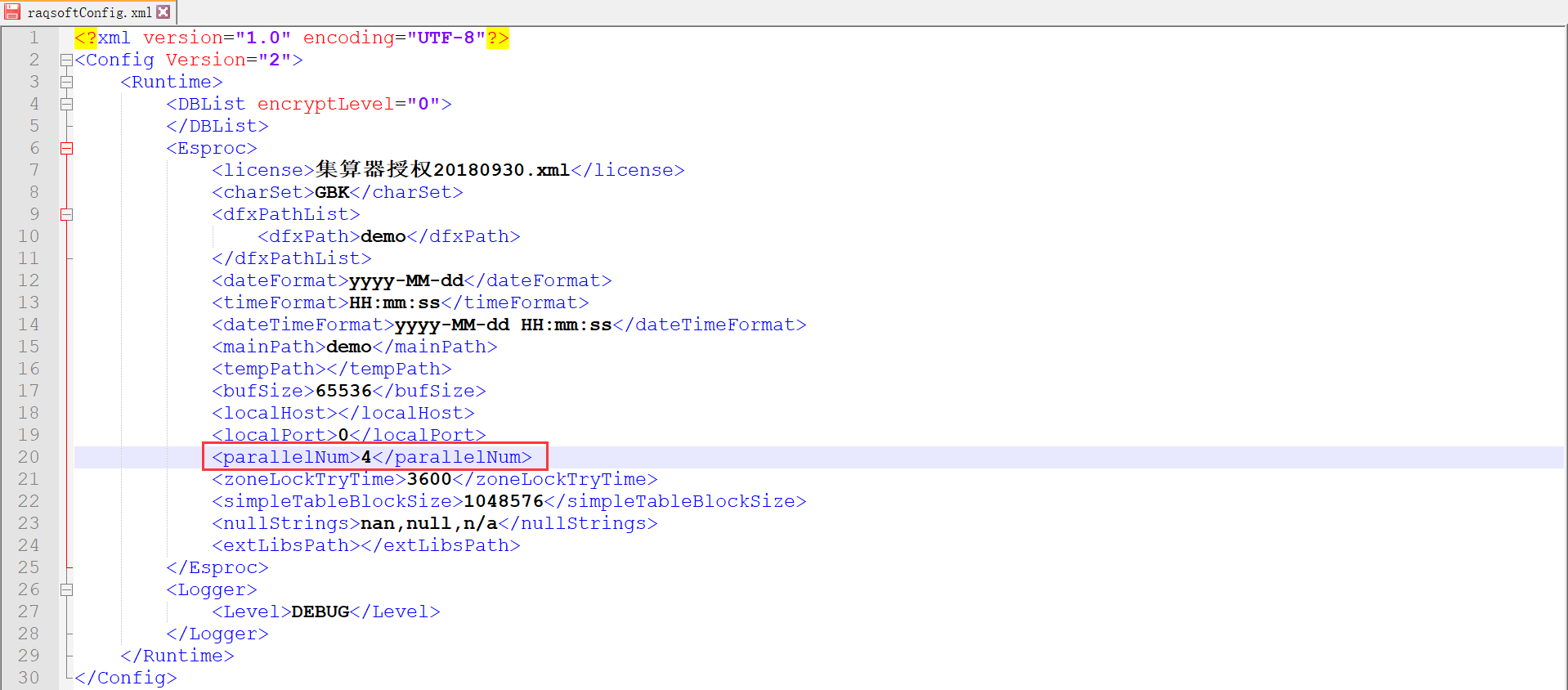
单表并行取数
有时我们查询的某个表数据量较大、时间较长,这时就可以通过集算器针对单表并行取数提升性能。这里所谓的单表是指通过条件并行读取一份(单表)数据。
全内存
假设内存可以容纳全部要读取的数据,并行取数后再进行下一步运算(全内存的计算速度最快)。
举例
订单(Orders)有订单 ID,订购日期,订单金额等字段,其中订单 ID 是递增的整数逻辑主键。
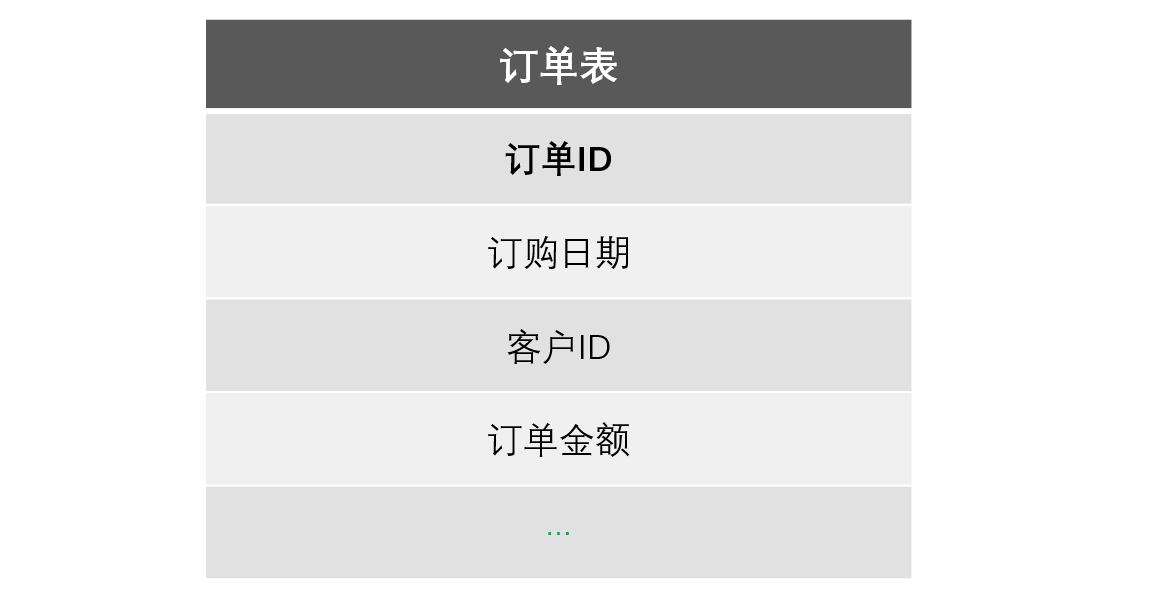
【计算目标】 并行读
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 560
560











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









