









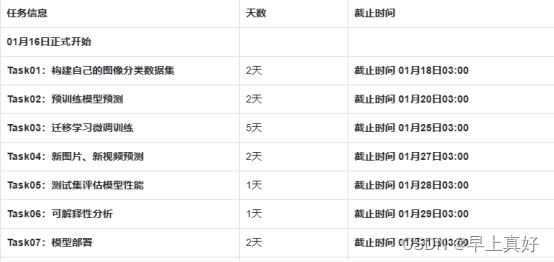
Task5:在测试集上评估图像分类算法的精度
对B站up同济子豪兄的图像分类系列的学习(大佬的完整代码在GitHub开源)
任务介绍与想法
本次任务是测试集上评估图像分类算法的精度。在大佬开源的代码中,无论是准确率评估指标还是混淆矩阵、PR曲线、ROC曲线、降维可视化,都可以很容易地得到结果。而在这些代码中可能出现的问题,也都在前面的任务中已经解决,比如matplotlib绘制中文的处理、gpu上训练的权重用于cpu上需要加映射参数等。可以说,只要前面的任务认真完成,这次的任务至少在代码运行上是没有任何问题。
基于此种情况,我认为这个任务的重点实际上是对以上的几种评估指标的理解。
机器学习分类评估指标
手绘笔记讲解:手绘图解分类器评估指标_哔哩哔哩_bilibili
混淆矩阵: 混淆矩阵详解_哔哩哔哩_bilibili
ROC曲线: ROC曲线详解_哔哩哔哩_bilibili
F1-score:F1-Score详解_哔哩哔哩_bilibili
F-beta-score:正负样本不均衡时的分类评估指标_哔哩哔哩_bilibili
语义特征降维可视化
【斯坦福CS231N】可视化卷积神经网络:【子豪兄】精讲CS231N斯坦福计算机视觉公开课(2020最新)_哔哩哔哩_bilibili
五万张ImageNet 验证集图像的语义特征降维可视化:t-SNE visualization of CNN codes
谷歌可视化降维工具Embedding Projector 谷歌可视化降维工具Embedding Projector_哔哩哔哩_bilibili
学习评估指标
混淆矩阵
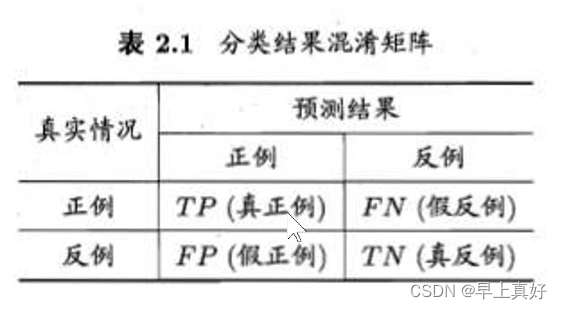
“混淆矩阵是一个误差矩阵,常用于监督学习中评判算法的性能。”混淆矩阵的含义在图中已经很明显了,但还是有必要举出二分类与多分类的混淆矩阵的例子加强理解
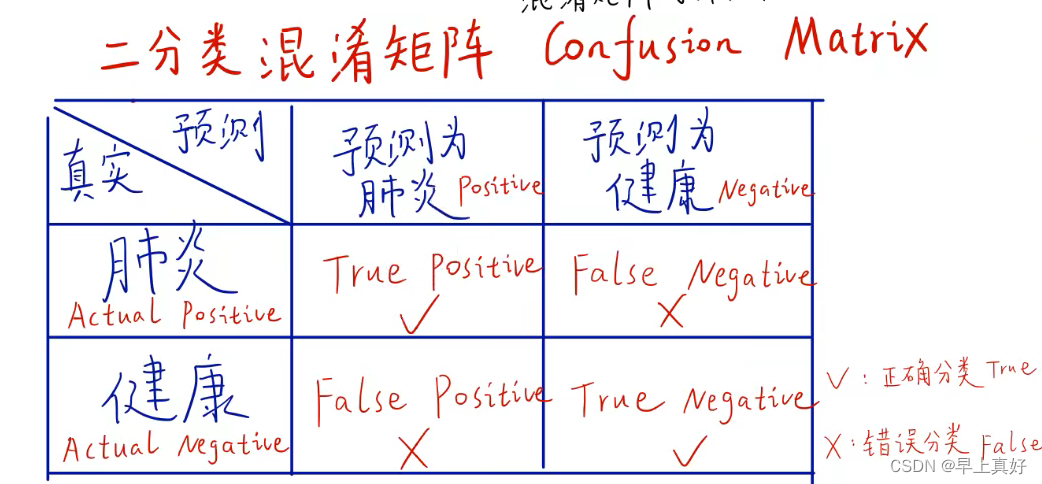
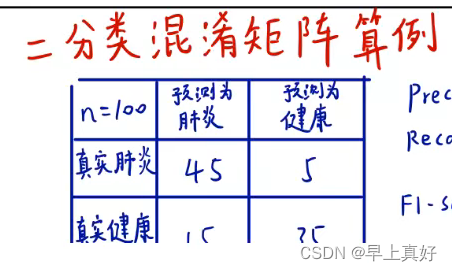
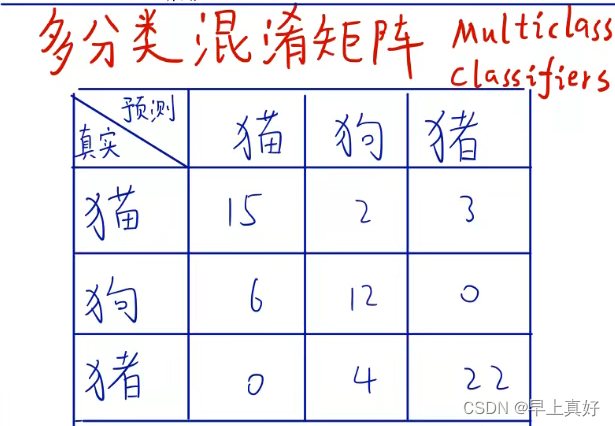
后续的多种指标都是基于混淆矩阵得来的,而我们在运行代码种得到的混淆矩阵可视化后应该是长成这个样子。通过颜色的深浅,直观地表现出误差
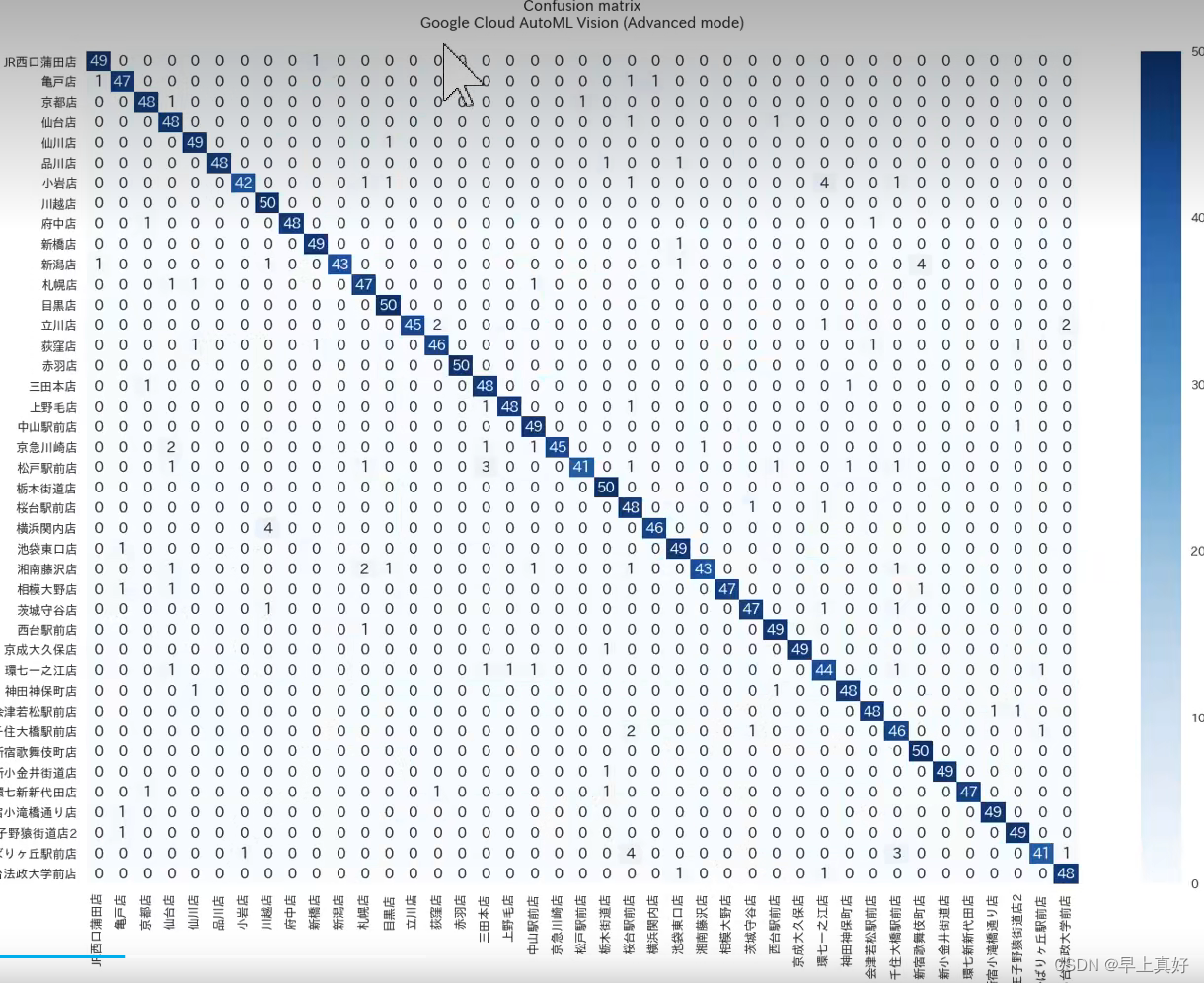
from sklearn.metrics import confusion_matrix
confusion_matrix_model = confusion_matrix(df['标注类别名称'], df['top-1-预测名称'])
我们可以使用scikit-learn中的混淆矩阵函数confusion_matrix来得到混淆矩阵,那么真正例假正例也就清晰了。
然后我们对这个混淆矩阵进行可视化。由于混淆矩阵本身不含有标签,所以还需要我们自己传入标签的列表。
def cnf_matrix_plotter(cm, classes, cmap=plt.cm.Blues):
"""
传入混淆矩阵和标签名称列表,绘制混淆矩阵
"""
plt.figure(figsize=(10, 10))
plt.imshow(cm, interpolation='nearest', cmap=cmap)
# plt.colorbar() # 色条
tick_marks = np.arange(len(classes))
plt.title('混淆矩阵', fontsize=30)
plt.xlabel('预测类别', fontsize=25, c='r')
plt.ylabel('真实类别', fontsize=25, c='r')
plt.tick_params(labelsize=2) # 设置类别文字大小
plt.xticks(tick_marks, classes, rotation=90) # 横轴文字旋转
plt.yticks(tick_marks, classes)
# 写数字
threshold = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > threshold else "black",
fontsize=12)
plt.tight_layout()
plt.savefig('混淆矩阵.pdf', dpi=300) # 保存图像
plt.show()注意:要导入itertools库用于创建迭代器。
常见的指标
Accuracy:准确率,表示判定正确的次数与所有判定次数的比例。即(TP+TN)/(TP+TN+FP+FN)
Precision:一般被叫做精确率,但是一个准确率一个精确率让人云里雾里的。子豪兄大佬在视频中将其解释为查准率,我感到这种叫法要更好理解,表示正确判定为正例的次数与所有判定为正例的次数的比例,也就是我说他阳了中他真的阳了与我说阳了的人数的比例。TP/(TP+FP),如果理解起来有困难,可以对照前面的表进行理解
Recall:一般叫做召回率,我也感到不明觉厉,子豪兄大佬解释为查全率,我认为更容易理解,示正确判定为正例的次数与所有实际为正例的次数的比例,也就是说在所有阳了的人里面我说他阳了的人占的比例(没说完就是没查全)。TP/(TP+FN),假反例就是实际为真嘛。
F1-score:这是precision与recall的调和平均。因为一般情况下,P和R任意一个过大都是不该视之为正常的,通过上面的概念很好理解这件事儿。因此需要一个指标表示P和R的共同作用。调和平均的特点是,两数和一定,当相等时,其调和平均能够得到最大值。虽然P和R并不是和一定的,但是他们是负相关的关系,所以大体上可以使用这种方法。
PR曲线与AP值
在代码中使用了PR曲线,实际上就是就是以P和R为横纵坐标得到的图像。
在众多学习器对数据进行学习后,如果其中一个学习器的PR曲线A完全包住另一个学习器B的PR曲线,则可断言A的性能优于B。但是A和B发生交叉,那性能该如何判断呢?我们可以根据曲线下方的面积大小来进行比较,但更常用的是平衡点F1。平衡点(BEP)是P=R时的取值(斜率为1),F1值越大,我们可以认为该学习器的性能较好。F1的计算如下所示:
F1 = 2 * P * R /( P + R )
————————————————
版权声明:本文为CSDN博主「gz7seven」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/guzhao9901/article/details/107961184
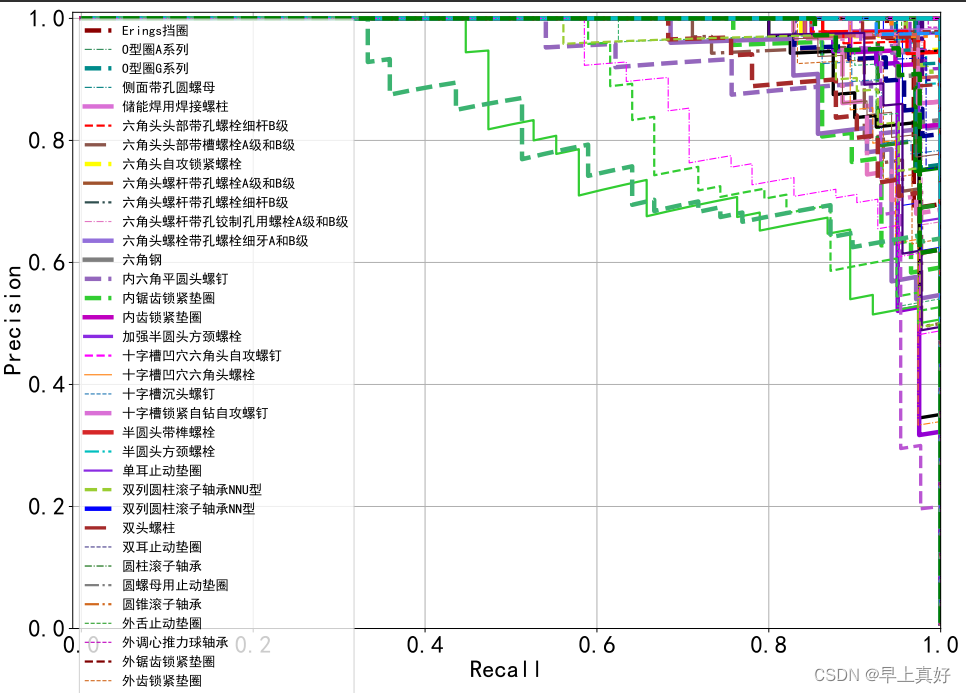
AP值相当于对Precision取平均值,用以判断模型在一个类别上的好坏。mAP相当于对AP取平均,判断模型在整个数据集上的好坏。
ROC曲线
是真正率(TPR)与假正率(FPR)分别作为横纵坐标得到的曲线,可以作为判断模型好坏的依据。
通过这个网站可以感受ROC曲线的特性,这是一个交互式的ROC曲线图像:http://navan.name/roc/
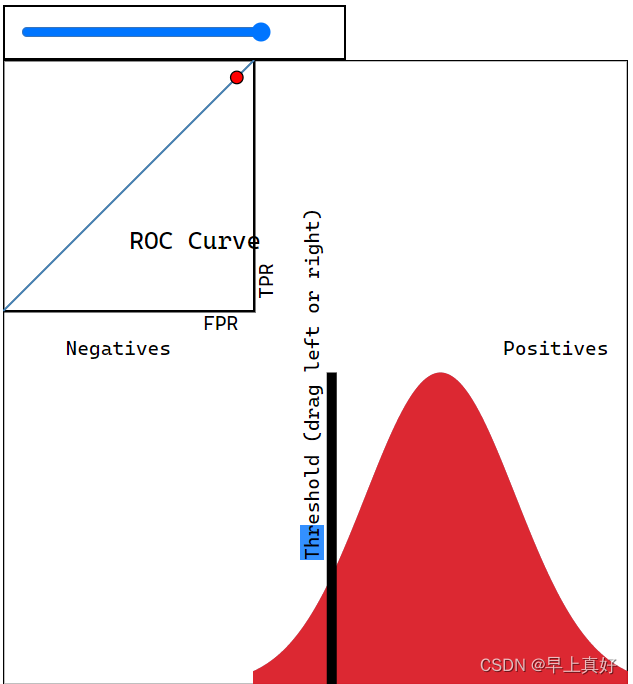
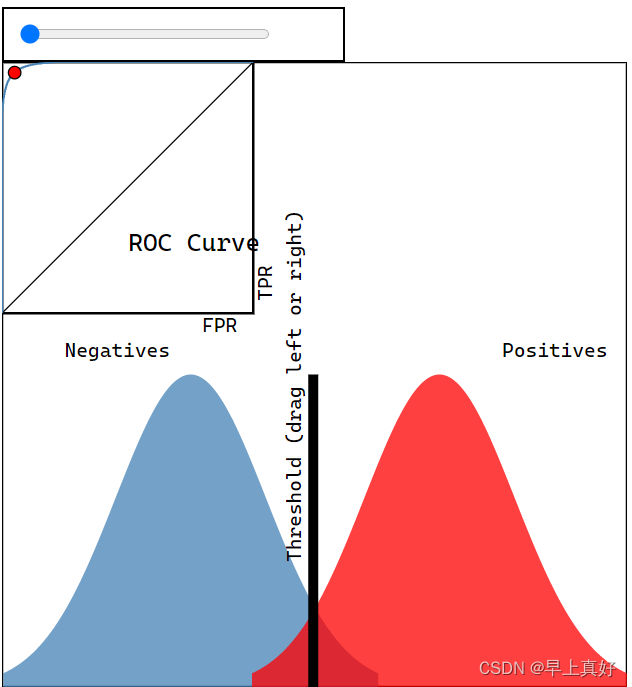
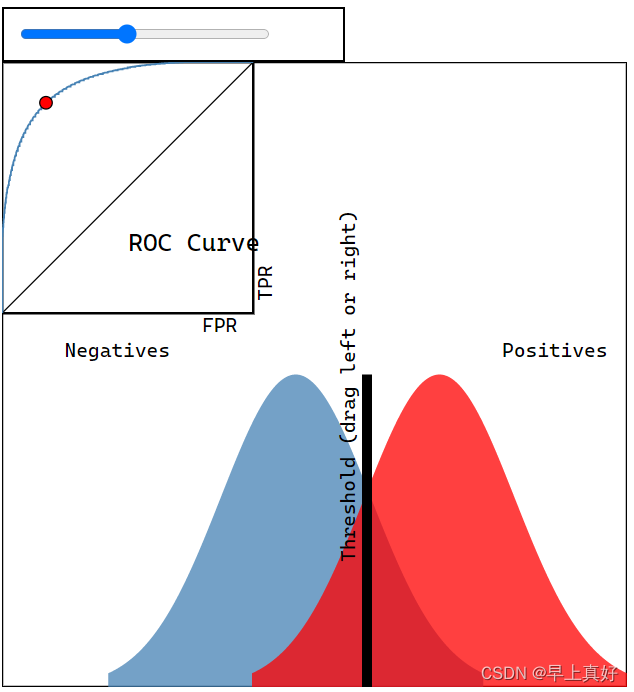
如图所示,正反例完全重合时呈现45度线,随后一直在该线上方,重合越少,越接近直角。如果正反例交换位置,可以预见到曲线将会出现在45度显得下方。
通过这个可以判断分类器的优劣。视频弹幕上前辈疑惑说如果正例反例重合的话就不能得到满意的ROC曲线,我只能说一点也不错。因为正反例是否重合正是靠自己的模型是否能够将正反例区分开来决定的,因此才会有ROC曲线越接近直角,分类器分类效果越好的说法。
specific_class = '波形弹簧垫圈'
# 二分类标注
y_test = (df['标注类别名称'] == specific_class)
# 二分类置信度
y_score = df['波形弹簧垫圈-预测置信度']
from sklearn.metrics import roc_curve, auc
fpr, tpr, threshold = roc_curve(y_test, y_score)
plt.figure(figsize=(12, 8))
plt.plot(fpr, tpr, linewidth=5, label=specific_class)
plt.plot([0, 1], [0, 1],ls="--", c='.3', linewidth=3, label='随机模型')
plt.xlim([-0.01, 1.0])
plt.ylim([0.0, 1.01])
plt.rcParams['font.size'] = 22
plt.title('{} ROC曲线 AUC:{:.3f}'.format(specific_class, auc(fpr, tpr)))
plt.xlabel('False Positive Rate (1 - Specificity)')
plt.ylabel('True Positive Rate (Sensitivity)')
plt.legend()
plt.grid(True)
plt.savefig('{}-ROC曲线.pdf'.format(specific_class), dpi=120, bbox_inches='tight')
plt.show()我们使用scikit-learn中带有的roc_curve函数来进行处理。
测试集语义特征降维可视化
抽取Pytorch训练得到的图像分类模型中间层的输出特征,作为输入图像的语义特征。
计算测试集所有图像的语义特征,使用t-SNE和UMAP两种降维方法降维至二维和三维,可视化。
分析不同类别的语义距离、异常数据、细粒度分类、高维数据结构。
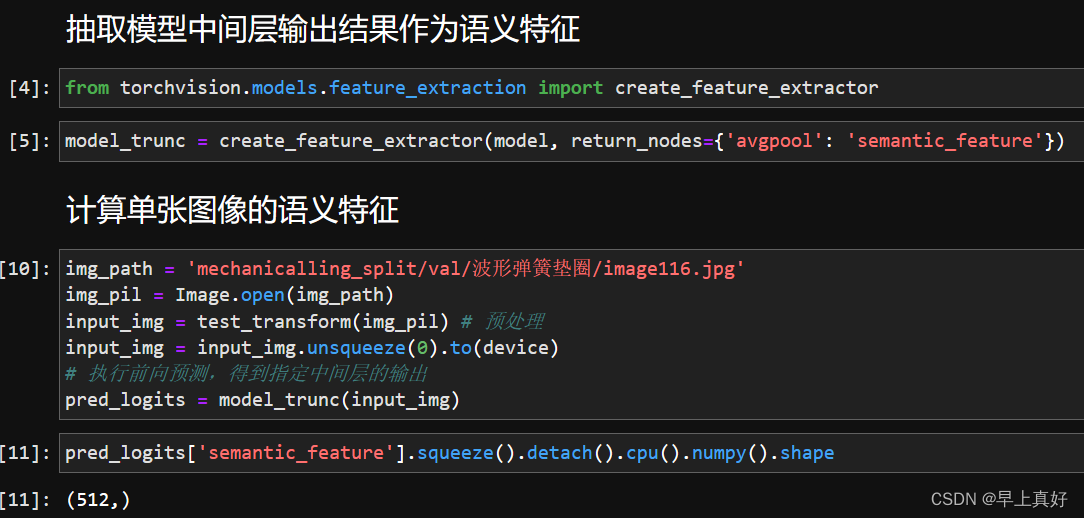 通过代码可以看到,我们进行了定位,抽取了特征(基础不好的弊端体现出来了)
通过代码可以看到,我们进行了定位,抽取了特征(基础不好的弊端体现出来了)
此时的特征是高维的,我们将其降到二维或三维。采用的方法是t-SNE和UMAP两种降维方法。t-SNE更经典,UMAP更快速,但需要自己安装(t-SNE可以通过sklearn调用)
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, n_iter=20000)
X_tsne_2d = tsne.fit_transform(encoding_array)# 官方文档:https://umap-learn.readthedocs.io/en/latest/index.html
!pip install umap-learn datashader bokeh holoviews scikit-image colorcet
import umap
import umap.plot
mapper = umap.UMAP(n_neighbors=10, n_components=2, random_state=12).fit(encoding_array)完整的代码请直接git子豪大佬的仓库,并观看子豪大佬的视频。我仅仅只记录了一些学习过程中需要了解而自己未了解的东西。
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











