






1.摘要
这篇文章是针对开放域的多跳问题,通过文本检索的方式得到答案。
本文贡献:
• 我们提出了一种新颖的多跳检索方法,我们认为这对于真正解决开放域多跳QA 任务是必不可少的。
• 我们展示了我们方法的有效性,它在单跳和多跳开放域QA 基准测试中都取得了最先进的结果。
• 我们还建议使用句子级表示进行检索,并展示这种方法相对于段落级表示的可能优势。
2.任务定义
首先定义了一个三维向量(KS,Q,A),在这里KS={P1,P2,...,P|KS|},在这里每一个P就代表一个段落每一个P又由l个token组成。Q=(q1,q2,...,qm)是一个文本问题由m个token组成。A=(a1,a2,...,an)是一个文本答案同样由n个token组成。
本论文的任务是从背景知识源KS中找到问题Q的答案A,学习得到一个函数,A=
(Q,KS)。
3.解决方案
解决方案称为MUPPET(multi-hop paragraph retrieval),依赖于两个主要组件组成基本方案,(a)一个段落和问题编码器(a paragraph and question encoder),(b)一个段落阅读器(a paragraph reader)。
编码器经过训练,可以将段落编码为 d 维向量,并将问题编码为同一向量空间中的搜索向量。 然后,应用最大内积搜索 (MIPS) 算法来查找与给定问题最相似的段落。 存在几种用于快速(可能是近似)MIPS 的算法,例如 Johnson 等人(2017)提出的算法。 然后将最相似的段落传递给段落阅读器,段落阅读器反过来提取问题的最可能答案。
段落编码不依赖于问题是至关重要的。 这可以在给定新的搜索向量时存储预先计算的段落编码并执行高效的 MIPS。 如果没有这个属性,任何新问题都需要处理完整的知识源(或其中的重要部分)。
对于多跳检索,作者对方案进行了扩展,简单来说就是先对问题Q进行编码获得一个q,然后将q转换为一个搜索向量,这个搜索向量用于搜索前k个相关段落(意思应该是不相关就不搜索),然后得到k个新的搜索向量,然后以此类推继续下去直到结束,具体见下图。

3.1Paragraph and Question Encoder
作者定义了一个f作为编码器模型。给定一个段落P包含有k句话,即和m个tokens,即
![]() ,又有
,又有![]() ,其中l代表了句子的长度,作者的encoder通过以上输入生成了k个相应的d维编码,也就是一个句子一个。然后对
,其中l代表了句子的长度,作者的encoder通过以上输入生成了k个相应的d维编码,也就是一个句子一个。然后对![]() 通过以下层进行编码。
通过以下层进行编码。
Word Embedding 每一个token t 通过字母级别的信息和单词级别的信息被嵌入进一个向量t中。单词级别的嵌入是通过预训练的词嵌入获得的。一个有个字母的token t的字母级别的嵌入是通过以下步骤获得的:每一个字母
都会被嵌入一个固定大小的向量
。然后我们将每一个token的字母级别的嵌入传递到一个一维卷积神经网络中,然后经过最大池化。这制造了一个固定大小的字母级别的表征为每一个token。最后,我们连接单词级别和字母级别的嵌入组成最终的单词表示t = [
.
Recurrent Layer 在获得了词表示之后,我们使用一个双向的GRU去处理段落以及获得其上下文化的词表示。
![]()
Sentence-wise max-pooling 最后,我们将段落标记的上下文表示分块为相应的句子组,并在每个句子组的时间维度上应用 max-pooling 以获得 parargaph 的 d 维句子表示。图 3a 显示了句子编码器的高级轮廓,其中我们可以看到一系列 m 个token通过上述层,产生 k 个句子表示。
类似地计算问题 Q 的编码 q,使得 q = f(Q)。 请注意,我们为任何给定问题生成单个向量,因此最大池操作一次应用于所有问题词,而忽略句子信息。

上图注释:上图是sentence encoder的架构,该模型接受了一系列的token作为input然后生成一系列的句子表示。
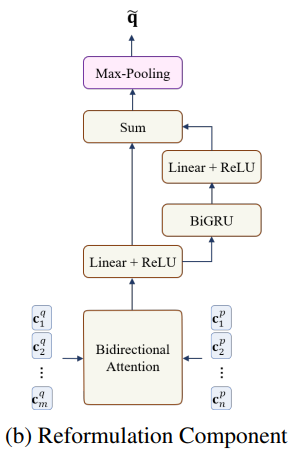
Reformulation Component 重构组件接收一个段落 P 和一个问题 Q,并产生一个向量 。首先,使用与初始编码相同的嵌入和循环层获得上下文化的词表示,
对应于问题Q,
对应于段落P。我们然后将上下文化的词表示传递进一个双向注意层中。问题单词i与段落词j之间的attention是通过下式计算的:
![]()
对于每一个问题词,我们计算一个向量:
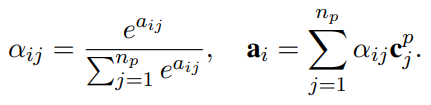
段落到问题的向量 计算如下:
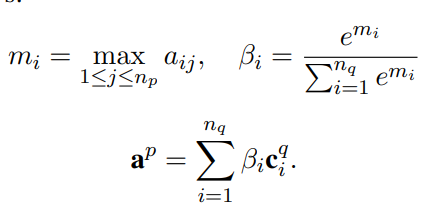
作者把,
,
和
连接起来,然后将结果通过具有 ReLU 激活的线性层来计算最终的双向注意力向量。我们还使用了一个残差连接,我们用一个双向 GRU 和另一个带有 ReLU 激活的线性层来处理这些表示。 最后,我们将两个线性层的输出相加。 和以前一样,我们在残差层的输出上使用最大池化层推导出 d 维重新制定的问题表示 q。 图 3b 给出了重构层的高级轮廓,其中 m 个问题的上下文化令牌表示和段落的 n 个上下文化令牌表示通过组件的层传递以产生重构的问题表示 q。
Relevance Scores 给定段落 P 的句子表示 (s1, s2, ..., sk),以及 Q 的问题编码 q,P 与问题 Q 的相关性分数按以下方式计算:
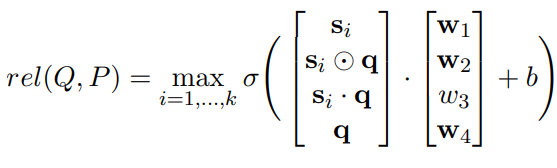
Conneau 提出了一种类似的最大池编码方法以及评分层的结构,并在各种句子级任务中展示了它们的功效。 我们发现这种逐句表述是有益的,因为段落中的一个句子与一个问题相关就足以使整个段落被认为是相关的。 这允许更细粒度的段落表示和更准确的检索。 图 4 给出了使用这种句子级模型的一个示例,其中我们看到两个不同的句子回答了两个问题。 我们的模型允许每个问题仅与段落的某些部分相似,而不一定与所有问题相似。

Search Vector Derivation 回想一下,我们的检索算法是基于在段落编码空间中执行 MIPS。 为了从编码 q 的问题中推导出这样一个搜索向量,我们观察到:

因此,最终问题Q的搜索向量是 =
。当预测第二次检索迭代的相关性分数时,同样的方程适用,在这种情况下,q 与 q~ 交换。
Training and Loss Functions 每个训练样本由一个问题和两个段落(Q,P1,P2)组成,其中 P1 对应于在第一次迭代中检索到的段落,而 P2 对应于使用重构向量 在第二次迭代中检索到的段落。 如果 P1 构成回答问题的必要证据段落之一,则认为 P1 是相关的。 只有当 P1 和 P2 一起构成回答问题所需的完整证据段落集时,才认为 P2 是相关的。 两次迭代都具有相同形式的损失函数,并且通过优化迭代损失的总和来训练模型。
每次迭代的训练目标由两部分组成:二元交叉熵损失函数和排名损失函数。 交叉熵损失定义如下:
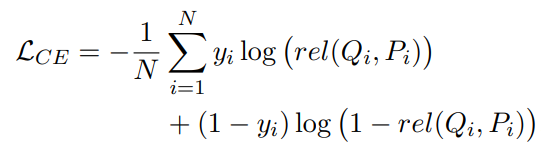
其中 yi ∈ {0, 1} 是一个二进制标签,表示在计算 rel(Qi, Pi) 的迭代中 Pi 与 Qi 的真正相关性,N 是当前批次中的样本数。
排名损失按以下方式计算,首先,对于给定批次中的每个问题 Qi,我们找到每个问题的正负段落得分的平均值
![]()
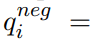
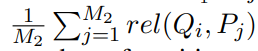
M1和M2分别是Qi的正负样本数。
然后,我们将边际排名损失(Socher et al., 2013)定义为
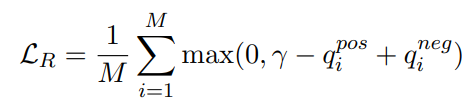
其中 M 是当前批次中不同问题的数量,γ 是超参数。 最终目标是两个损失的总和:
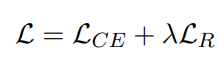
3.2 Paragraph Reader
段落阅读器接收问题 Q 和段落 P 作为输入,并从 P 中提取 Q 的最可能答案跨度。我们使用 Clark 和 Gardner (2018) 提出的 S-norm 模型。 该模型的详细说明在附录 A 中给出。
Training 段落阅读器的输入样本由一个问题和一个上下文(Q,P)组成。 我们针对跨度开始边界优化 S-范数模型中使用的相同负对数似然函数:
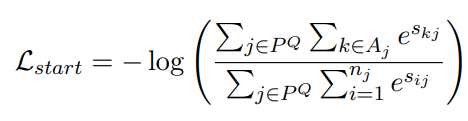
其中 是与相同问题 Q 配对的段落集,Aj 是在第 j 段中开始答案跨度的标记集,sij 是给予第 j 段中第 i 个标记的分数 . 跨度结束边界使用相同的公式,因此最终的目标函数是两者之和:
。
4 Experiments and Results
我们在两个数据集上测试我们的方法,并使用标准精确匹配 (EM) 和 F1 指标以及 Yang 等人提出的指标来测量端到端 QA 性能。 (2018) 用于 HotpotQA 数据集(参见附录 B)。
4.1 Datasets
HotpotQA 杨等人。 (2018)引入了一个基于维基百科的问题数据集,需要对多个段落进行推理才能找到正确的答案。 该数据集还包括对句子级支持事实的硬监督,这鼓励模型给出可解释的答案预测。 该数据集有两个基准设置可用:(1)干扰设置,其中给读者一个问题以及一组段落,其中包括支持事实和不相关的段落; (2) 完整的 wiki 设置,它是数据集的开放域版本。 我们将此数据集用作多跳检索设置的基准。 必须从第 3.2 节向阅读器添加几个扩展,以使其适用于 HotpotQA 数据集。 附录 B 中给出了我们提议的扩展的详细描述。
SQuAD-Open 陈等人。 (2017) 将原始 SQuAD 数据集 (Rajpurkar et al., 2016) 中的问题与其对应的上下文解耦,并通过将整个 Wikipedia 转储定义为背景知识源,从而形成数据集的开放域版本。 应提取问题的答案。 我们使用这个数据集来测试我们的方法在经典的单跳检索设置中的有效性。
4.2 Experimental Setup
Search Hyperparameters 对于我们在多跳设置中的实验,我们在第一次检索迭代中使用了 8 的宽度。 在我们所有的实验中,除非另有说明,否则读者会阅读前 45 段,通过这些段落独立推理并找到最可能的答案。 此外,我们发现将 MIPS 检索器的搜索空间限制为知识源的子集是有益的,这由 TF-IDF 启发式检索器确定。 我们将 ni 定义为检索迭代 i 的搜索空间的大小。 正如我们将看到的,选择不同的 ni 值需要权衡取舍。 较大的 ni 值提供更高召回率的可能性,而较小的 ni 值会以不相关段落的形式引入较少的噪声。
Knowledege Sources 对于 HotpotQA,我们的知识源与 Yang 等人使用的 Wikipedia 版本相同。 (2018) 3。 这个版本是整个维基百科所有第一段的集合。 对于 SQuAD-Open,我们使用 Chen 等人使用的相同 Wikipedia 转储。 (2017)。 对于这两种知识源,我们用于减少搜索空间的基于 TF-IDF 的检索器是 Chen 等人提出的。 (2017),它使用二元散列和 TF-IDF 匹配。 我们注意到,在 HotpotQA Wikipedia 版本中,每个文档都是一个段落,而在 SQuAD-Open 中,使用了完整的 Wikipedia 文档。
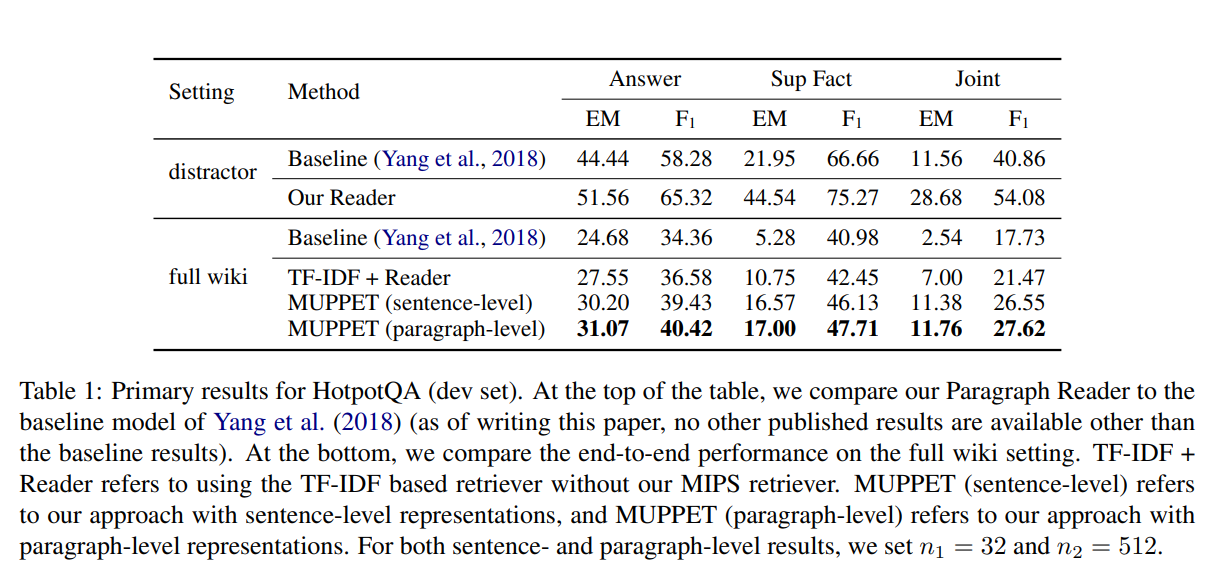
HotpotQA(开发集)的主要结果。 在表格的顶部,我们将段落阅读器与 Yang 等人的基线模型进行了比较。 (2018 年)(截至撰写本文时,除基线结果外,没有其他已发表的结果可用)。 在底部,我们比较了完整 wiki 设置上的端到端性能。 TF-IDF + Reader 是指在没有我们的 MIPS 检索器的情况下使用基于 TF-IDF 的检索器。 MUPPET(句子级)是指我们使用句子级表示的方法,而 MUPPET(段落级)是指我们使用段落级表示的方法。 对于句子和段落级别的结果,我们设置 n1 = 32 和 n2 = 512。
4.3 Results
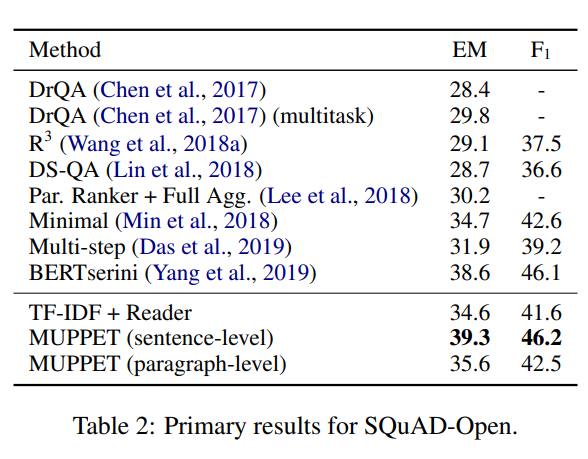
Primary Results 表 1 和表 2 分别显示了我们在 HotpotQA 和 SQuAD-Open 数据集上的主要结果。在 HotpotQA 干扰器设置中,我们的段落阅读器大大提高了基线阅读器的结果,将联合 EM 和 F1 分数分别提高了 17.12 (148%) 和 13.22 (32%) 点。在完整的 wiki 设置中,我们比较了三种检索方法:(1)TF-IDF,其中仅使用 TF-IDF 启发式。从前 10 个段落中向读者提供所有可能的段落对。 (2) 句子级,我们使用带有句子级编码的 MUPPET。 (3) 段落级,我们使用 MUPPET 和段落级编码(没有句子信息)。我们可以看到,这两种方法都明显优于 na¨ıve TF-IDF 检索器,表明我们方法的有效性。在撰写本文时,我们在 HotpotQA 完整 wiki 设置(测试集)排行榜中排名第二。对于 SQuAD-Open,我们的句子级方法建立了最先进的结果,将当前的非 BERT(Devlin 等人,2018)的最先进水平提高了 4.6(13%)和 3.6(8%) ) EM 和 F1 点,分别。这表明我们的编码器不仅可以用于多跳问题,还可以用于单跳问题。
Retrieval Recall Analysis 我们在图 5a 中分析了 HotpotQA 的 TF-IDF 检索器的性能。 我们可以看到,检索器成功地检索到每个问题的至少一个黄金段落(前 32 段超过 90%),但未能检索到两个黄金段落。 这证明了有效的多跳检索方法来帮助或替代经典信息检索方法的必要性。
Effect of Narrowing the Search Space 在图 5b 和 5c 中,我们将我们的方法的性能显示为最后一次检索迭代的搜索空间大小的函数。 对于 SQuAD Open,TF-IDF 检索器最初检索一组文档,然后将其拆分为段落以形成搜索空间。 top-k 段落的每个搜索空间将模型的潜在召回限制为 TF-IDF 检索器检索到的 top-k 段落的潜在召回。 这被证明对于非常小的 k 值是次优的,因为 TF-IDF 检索器的性能不够好。 然而,我们的模型无法从无限增加搜索空间中受益,这暗示它们对噪声的鲁棒性不如我们希望的那样。

图5:基于 TF-IDF 检索器的各种结果。 (a) HotpotQA 上 TF-IDF 启发式检索器的检索结果。 At Least One @ k 是在前 k 个段落中检索到至少一个包含支持事实的段落的问题数。 潜在完美@k 是在前 k 个段落中检索到包含支持事实的两个段落的问题数。 (b) 和 (c) 分别对 SQuAD-Open 和 HotpotQA 数据集进行性能分析,因为 TF-IDF 启发式检索器检索到更多文档/段落。 请注意,对于 SQuAD-Open,每个文档都包含几个段落,并且从搜索空间中的文档中为读者提供了前 k 个 TF-IDF 排名的段落。
Effectiveness of Sentence-Level Encodings 我们的方法建议使用句子级编码进行段落检索。 我们在图 5b 和 5c 中测试了这种方法的重要性。 虽然句子级编码似乎对于改善 SQuAD-Open 上的最新结果至关重要,但对于 HotpotQA 则不能这样说。 我们假设这是数据集创建方式的结果。 在 SQuAD 中,每个段落都作为几个问题的上下文,如图 4 所示。这导致问题被问到对段落主旨不太重要的事实,因此它们不会被封装在单个段落表示中。 然而,在 HotpotQA 中,训练集中的大部分段落最多只能作为一个问题的上下文。
5 Related Work
陈等人。 (2017 年)首次使用文本知识源将神经方法用于开放域 QA 任务。他们提出了 DrQA,这是一种包含两个组件的管道方法:一个基于 TF-IDF 的检索器和一个多层神经网络,该网络经过训练可以在给定问题和段落的情况下找到答案范围。为了改进基于 TF-IDF 的组件的检索,许多现有的工作已经使用远程监督(DS)来进一步重新排列检索到的段落(Htut 等人,2018 年;Yan 等人,2018 年)。王等人。 (2018a) 使用强化学习以端到端的方式训练重新排序器和 RC 组件,并显示出其优于单独使用 DS 的优势。敏等人。 (2018) 训练了一个句子选择器,并展示了阅读最少上下文而不是完整文档的有效性。由于 DS 通常会导致错误的标签,Lin 等人。 (2018)提出了一种去噪方法来缓解这个问题。虽然这些方法已被证明可以提高各种开放域 QA 数据集的性能,但它们的重新排序方法在它可以处理的段落数量方面受到限制,因为它需要与所有可能的段落一起阅读问题。这与我们的方法形成对比,在我们的方法中,所有段落表示都是预先计算的,以允许有效的大规模检索。有些作品采用了类似的预计算方案。李等人。 (2018) 学习了问题和段落的编码函数,并根据段落与问题的点积相似度对段落进行排序。然而,他们的许多改进可以归因于 Wang 等人建议的答案聚合方法的结合。 (2018b)在他们的模型中,这显着增强了他们的结果。徐等人。 (2018) 提出了短语索引 QA (PI-QA),这是 QA 任务的一种新形式,需要对答案和问题进行独立编码。然后使用问题编码通过执行 MIPS 来检索正确答案。这更像是一项挑战任务,而不是开放域 QA 的解决方案。 Das 等人最近的一项工作。 (2019 年)提出了一种新的开放域 QA 框架,该框架采用检索者和读者之间的多步骤交互。此交互式框架用于细化问题表示,以使检索更加准确。他们的方法是对我们的补充——交互式框架用于增强单跳问题的检索性能,而不是处理多跳域。
另一个让人想起我们方法的工作是记忆网络(Weston et al., 2015)。记忆网络由一组单元组成,每个单元都能够存储一个向量,以及四个模块(输入、更新、输出和响应),这些模块允许为手头的任务操作记忆。已经提出了许多记忆网络的变体,例如端到端记忆网络 (Sukhbaatar et al., 2015)、键值记忆网络 (Miller et al., 2016) 和分层记忆网络 (Chandar et al., 2016)。 , 2016)。
6 Concluding Remarks
我们提出了 MUPPET,一种用于多跳段落检索的新方法,并在单跳和多跳 QA 数据集中展示了它的功效。 开放域多跳设置的一个困难是缺乏监督,单跳设置中的一个困难通过使用远程监督在一定程度上得到缓解。 我们希望在未来的工作中解决这个问题,以允许学习两次以上的检索迭代。 我们的方法的一个有趣的改进是允许检索器自动确定是否需要更多的检索迭代。 一个有前途的方向可能是多任务方法,其中单跳和多跳数据集是联合学习的。 我们把它留给未来的工作。
Acknowledgments
This research was partially supported by the Israel Science Foundation (grant No. 710/18).
原论文链接:https://arxiv.org/abs/1906.06606![]() https://arxiv.org/abs/1906.06606
https://arxiv.org/abs/1906.06606















 1320
1320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









