






论文题目《CICERO:对话中情境化常识推理的数据集》
Abstract
本文通过上下文化的常识推理解决了对话推理的问题。我们策划了 CICERO,这是一个二元对话数据集,具有五种基于话语级推理的推理:原因、后续事件、先决条件、动机和情绪反应。该数据集包含来自 5,672 个对话的 53,105 个此类推论。我们使用这个数据集来解决相关的生成和判别任务:原因和后续事件的生成;产生先决条件、动机和听众的情绪反应;并选择合理的替代方案。我们的结果确定了这种以对话为中心的常识知识数据集的价值。我们希望 CICERO 将为基于常识的对话推理开辟新的研究途径。
1 Introduction
互联网上的对话内容正在迅速增长,这些内容拥有关于演讲者之间如何进行信息交换的宝贵知识。理解此类对话的关键一步是获得对对话中共享的信息进行推理的能力。为此,我们策划了一个名为 CICERO(对话中的上下文化 CommonsEnse InfeRence)的二元对话数据集,其中包含围绕对话中的话语进行的推论。该数据集侧重于对话中给定话语的五种基于推理的推理:原因、后续事件、先决条件、动机和情绪反应(cause, subsequent event, prerequisite, motivation, and emotional reaction)。
可以说,做出这种基于推理的推断往往需要常识性的知识,尤其是当推断是隐含的时候。图1a显示了这样一个案例,目标语词背后的原因在语境中并不明确。然而,应用常识知识,例如 戴手套 买一副新手套 就允许注释者推断出该词语的可能原因,另一方面,常识在从语境中筛选出相关信息方面可能是至关重要的。图1b描述了一个从语境中推断出目标话语背后原因的例子。这个推理可以从常识知识解释为这样子 重复消费相同的食品
厌倦
改变食物
在麦当劳吃饭。因此,我们有理由认为,这种知识可以帮助弥补输入和目标推理之间的差距。
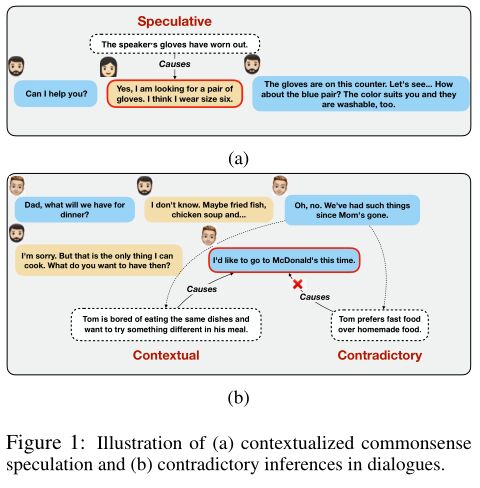
图 1:(a) 情境化常识推测和 (b) 对话中相互矛盾的推论的图示。
ATOMIC (Sap et al., 2019; Hwang et al., 2020) 就是这样一个基于常识推理的推理数据集,它允许大量推理类型。然而,ATOMIC 是上下文无关的,因为它只提供对短语的推断,而忽略了它们周围更广泛的上下文。另一方面,对整个话语进行推断需要了解它周围的上下文。根据 Grice 的格言(Grice,1975),在对话中,对话者提供任何需要的信息,仅此而已。因此,理解话语所需的大部分信息可能散布在对话中,而不一定局限于给定的话语中。例如,在图 1b 的示例中,要了解一位说话者想要去麦当劳的原因,需要了解之前话语的上下文。因此,ATOMIC 不适用于基于常识推理的对话推理,其中上下文对于理解话语的含义至关重要。我们在后续部分(§4)中的实验证实了这一点。
GLUCOSE (Mostafazadeh et al., 2020) 专门从独白中策划因果推论——原因、启用和结果。因此,对对话进行上下文辅音推断并不理想。此外,诸如动机和反应等特定于对话的维度超出了其范围。
另一方面,CIDER (Ghosal et al., 2021a) 确实为基于常识的对话推理提供了数据集,但它仅限于在对话中明确可观察到的推理。因此,基于 CIDER 的系统无法有效地围绕对话进行隐式推理推测。
CICERO 努力通过创建一个数据集来充分利用这三个数据集,该数据集可以通过考虑上下文并在答案不明显时进行推测,使模型能够有效地对对话进行操作。
2 Construction of CICERO
我们创建了 CICERO——一个大型的英语二元对话数据集,在人类注释者的帮助下,用五种类型的推理进行了注释,人类注释者接受了一套精心设计的指导方针的指导。
2.1 Annotation Instructions(2.1 注释说明)
注释者被给予对话和目标话语,如图 2 所示。然后要求注释者对目标话语做出推断,作为问题提出。他们写了一个语法正确、简洁且与对话一致的一句话答案。答案可能包含公开和推测的场景。对话上下文中明确或隐含地存在一个公开的场景。如果这样的上下文场景回答了问题,注释者将它们写成一个格式良好的句子。然而,在许多情况下,对话可能不包含答案,无论是明确的还是隐含的。在这种情况下,要求注释者使用常识和世界知识推测对话周围的合理场景,以设计与给定对话上下文不矛盾的答案。

图 2:对话-目标对。带有红色边框的话语是此对话的目标。
给定图 2 中的对话-目标对,以下关于目标的五个推断中至少有一个是由注释者做出的
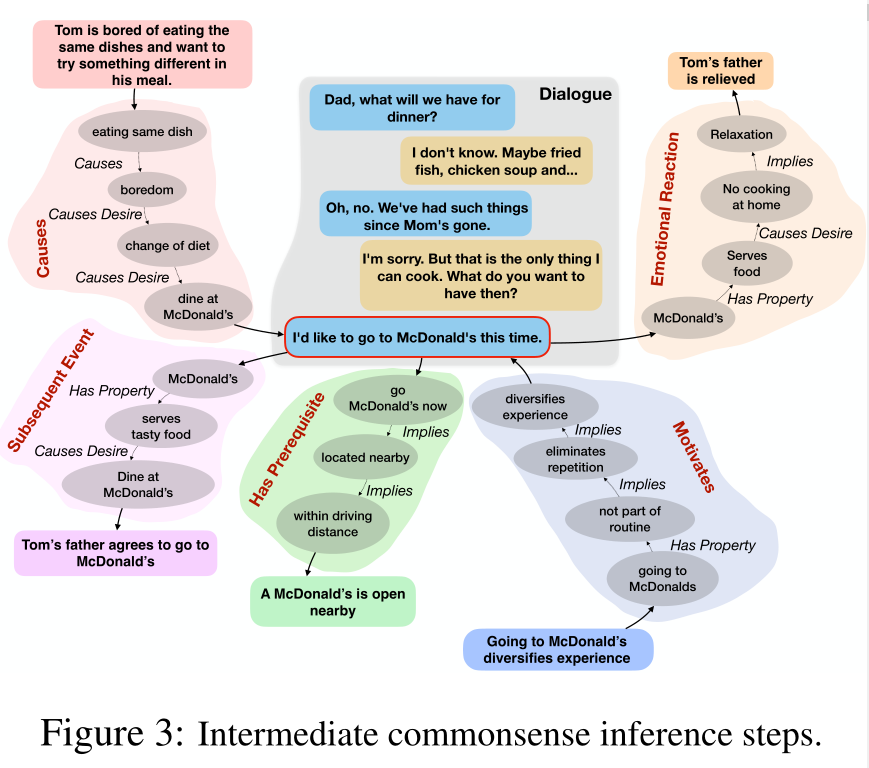
Q1.直接导致(公开)或可能导致(推测)目标的事件是什么?注释者考虑是否有任何可能或可能先于目标的事件会导致目标。
答:琳达在冬天没有经常锻炼。备注:注释者提供了可能的推测性答案,因为对话本身并没有为琳达的体重增加提供任何理由。
Q2.目标之后发生(公开)或可能发生(推测)的后续事件是什么?注释者写下目标之后发生或可能发生的事件。此外,注释者被告知,有时,目标的此类后续事件会被目标触发或可能被目标触发。
答:琳达开始节食并尝试减肥。备注:答案是推测性的,因为对话不包含显式/隐式后续事件。
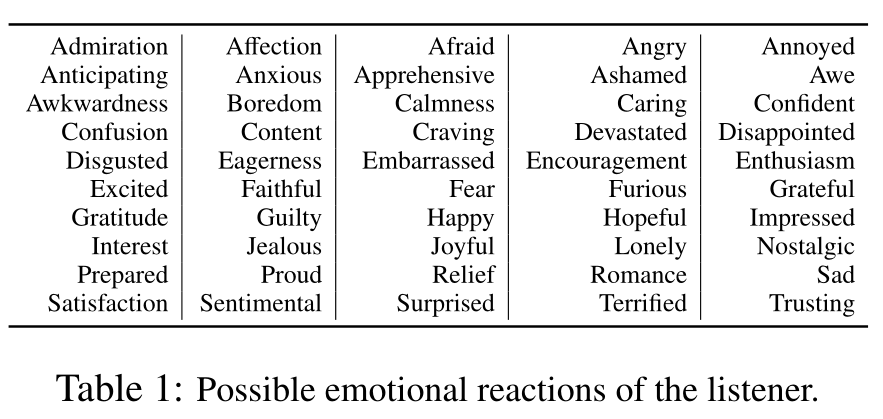
Q3.什么是(公开的)或可能是(推测的)Target 的先决条件?目标是否有任何必须首先发生或满足的直接先决条件或依赖关系? (在大多数情况下,先决条件是在另一个事件导致目标之前必须满足的状态/事件。)答案是使目标发生的状态/事件。换言之,先决条件是对话者就上下文达成一致的先验假设或背景信息。
答:琳达在冬天之前比较苗条。
备注:要求注释者在进行最终注释之前清楚地了解原因和前提之间的区别。
事件 X 的原因是直接导致 X 的事件。事件 X 的先决条件是 X 发生必须满足的条件。
Q4。什么是激励或可能激励 Target 的情感或基本人类驱动力?考虑目标说话者的基本人类驱动力、需求(和/或可能的情绪)。人类的基本动力和需求是食物、水、衣服、温暖、休息、安全、安全、亲密关系、朋友、声望、成就感、自我实现、创造性活动、享受等。做任何这些人类动力/心态/情感激励目标?
答:不适用于此目标。
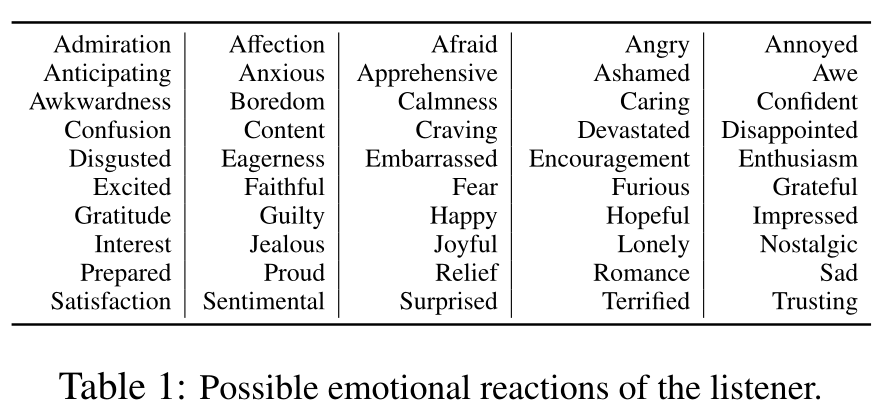
Q5.听者可能的情绪反应是什么:A(或B)?听众对目标的可能情绪反应或反应是什么?注释器使用表 1 中逐字列出的情感术语或相关词(例如,焦虑、困惑、感兴趣等)来捕捉听者的适当情感。
答案:听众鼓励琳达保持饮食。
附加指南。为确保样本的质量和多样性,我们还要求注释者遵守以下准则:
• 在猜测中要有创意。避免改写目标并写出不费吹灰之力的琐碎答案。如果改写目标是唯一可能的答案,建议跳过一个问题。
• 避免针对同一目标的不同问题重复相同的答案。
• 答案必须与给定的对话一致。
• 如果目标中包含多个短语,建议根据目标中最重要的短语来回答。
2.2 Dialogue Selection for CICERO
2.2.1 Source Datasets
为了构建 CICERO,我们使用以下三个数据集的二元对话:
DailyDialog (Li et al., 2017) 涵盖了广泛主题的对话——生活、工作、人际关系、旅游、金融等。组成的话语被标记为情感和对话-行为。
MuTual (Cui et al., 2020) 是一个多轮对话推理数据集。给定对话历史,目标是通过考虑意图、态度、代数、多事实和情境推理等方面来预测下一个话语。
DREAM (Sun et al., 2019) 是从英语作为外语的考试中收集的多项选择阅读理解数据集。该数据集提出了重大挑战,因为许多答案是非提取的,并且需要常识知识和多句推理。
2.2.2 Selection Process
我们使用以下过程从三个数据集中选择对话子集:
1. 我们删除在话语或单词级别上太短或太长的对话。平均每个话语少于 5 个话语或少于 6 个单词的对话被删除。总共超过 15 个话语或超过 275 个单词的对话也会被删除。
2. 所有三个源数据集都包含具有几乎相同话语的对话。我们删除了这些几乎重复的对话,以确保 CICERO 的主题多样性。我们使用基于微调 RoBERTa (Gao et al., 2021) 的句子嵌入模型来提取对话的密集特征向量。我们假设一对重复的对话具有至少 0.87 的余弦相似度,我们删除了重复项。
2.3 Target Utterance Selection(目标话语选择)
给定对话 D,我们选择目标话语如下:
• 我们首先确定 D 中目标话语的数量:如果 D 有 1-6 个话语,那么我们选择 2 或 3 个目标;如果它有 7-12 个话语,那么我们选择 3-5 个目标;否则,如果它有超过 12 个话语,我们选择 4-7 个目标。
• 我们将 D 分为 2-3 个片段,这些片段具有大致相等数量的连续话语。我们从每个片段中选择大致相等数量的排名靠前的话语。我们称这组话语为 x1。使用带有句子-BERT 嵌入(Reimers 和 Gurevych,2019a)的句子排名算法(Erkan 和 Radev,2004;Mihalcea 和 Tarau,2004)执行排名。
• 我们还选择 D 中最长的话语以及包含诸如 I'm、I'd、Ive、Ill 或它们的扩展等短语的话语。我们称这组话语为 x2。集合 x1 和 x2 不能不相交。
• 集合 x3 由 D 的最终话语组成。
我们从集合 x1、2、3 中选择目标话语的推理类型如下:
• 从 x1 ∪ x2: – 后续事件:80% 的目标。
– 原因和先决条件:60% 的目标。
– 唯一原因:28% 的目标。
– 独家先决条件:12% 的目标。
• 来自x2:所有目标的动机。
• 来自x3:侦听器对所有目标的反应。
2.4 Quality Assurance of CICERO
通过以下步骤确保数据集质量: • 最初,我们对 50 个随机对话进行抽样并手动注释其中的所有问题(如第 2.1 节)。然后对每个注释者在这些对话上进行评估,如果他/她的 95% 的注释被我们批准,则被选中执行注释任务。
• 我们在注释过程中不断审查并向注释者提供反馈。还指示注释者修改他们的答案。
• 完成注释后,我们雇用了三个额外的注释者,他们手动检查注释样本并对其可接受性进行评分。
这些注释者就批准这些样本中的 86% 达成了共识。从数据集中删除不具有多数协议的样本。
带注释的数据集的统计数据如表 3 所示。来自 CICERO 的一些带注释的示例也显示在表 2 中。

2.5 Features of CICERO
根据表 3,CICERO 中的大多数(~59%)推论本质上是因果关系。同样,大约 80% 的推论是推测性的和上下文相关的。因此,与仅包含显式上下文推断的 CIDER(Ghosal 等人,2021a)相比,CICERO 在其应用方面更加通用。 CICERO 还包含各种常识知识——从一般常识到物理和社会常识(更多详细信息,请参见附录 B)。
3 Commonsense Inference on CICERO
我们在 CICERO 上设计了生成式和多项选择的问答任务,以评估语言模型的对话级基于常识的推理能力。

















 2355
2355

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









