






一、实验背景
通过PySpark实现K-means算法,探索不同聚类数(k=1,2,3)对鸢尾花数据集的聚类效果,验证算法性能与数据分布特性。
二、实验配置
2.1 硬件环境
-
操作系统:Windows 11
-
内存:16GB DDR4
-
处理器:Intel Core i7-11800H
2.2 软件环境
| 组件 | 版本 |
|---|---|
| Python | 3.9.16 |
| PySpark | 3.4.1 |
| Scikit-learn | 1.2.2 |
2.3 数据集
-
文件路径:
G:\Desktop\大三下\大数据\dataset\Iris.csv -
样本量:150条
-
特征维度:4维(花萼/花瓣长度宽度)
三、核心实现逻辑
3.1 数据处理流程
-
特征工程
python
assembler = VectorAssembler(inputCols=feature_cols, outputCol="features") scaler = StandardScaler(inputCol="features", outputCol="scaledFeatures")
-
异常处理
-
k=1时手动生成全0标签(规避Spark限制)
python
if k == 1: predictions = processed_data.withColumn("prediction", lit(0)) -
3.2 评估体系
| 指标 | 计算方式 | 应用场景 |
|---|---|---|
| ARI | 调整兰德系数 | 有监督标签对比 |
| 轮廓系数 | 基于样本间距离的簇结构评估 | 无监督质量判断 |
四、实验结果分析
4.1 定量指标对比
| K值 | 调整兰德指数(ARI) | 标准化互信息(NMI) | 标签对齐准确率 | 轮廓系数 |
|---|---|---|---|---|
| 1 | 0.0000 | 0.0000 | 33.33% | 不可计算(N/A) |
| 2 | 0.5681 | 0.7337 | 66.67% | 0.8465 |
| 3 | 0.5923 | 0.6609 | 58.00% | 0.7005 |
4.2 关键发现
-
k=2的伪优现象
-
轮廓系数达0.8465,但ARI仅0.5681,说明:
-
算法找到了紧凑的簇结构
-
但与真实类别匹配度较低
-
-
推测原因:两个相近物种(versicolor和virginica)被合并
-
-
k=3的实用价值
-
ARI提升至0.5923,证明:
-
三簇划分更接近真实生物分类
-
但轮廓系数下降说明存在重叠样本
-
-
-
k=1的验证作用
-
所有指标失效,验证了:
-
单簇场景下评估指标无意义
-
K-means必须满足k≥2的前提条件
-
-
五、优化建议
5.1 算法调优方向
python
KMeans( initMode="random", # 尝试不同初始化策略 distanceMeasure="cosine", # 改用余弦距离 seed=42, # 固定随机种子 weightCol="feature_weights" # 添加特征权重 )
5.2 工程实践建议
-
日志优化
python
spark.sparkContext.setLogLevel("ERROR") # 仅显示错误日志-
解决中文乱码问题
-
-
可视化增强
-
添加三维PCA投影:
pca = PCA(k=3 -
绘制决策边界:
plt.contourf()
-
六、实验结论
-
最佳实践选择
-
科研场景:选择k=3(更符合生物学分类)
-
工程场景:选择k=2(更高的簇内一致性)
-
-
算法局限性
-
对重叠分布的类别区分能力有限
-
需结合密度聚类(如DBSCAN)进行补充分析
-
附录:典型问题解决方案
问题1:Spark日志乱码
解决方法:在代码开头添加:
python
import sys import io sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
问题2:轮廓系数计算异常
处理逻辑:
python
if len(np.unique(labels_pred)) == 1: silhouette = None # 跳过单簇场景 else: evaluator = ClusteringEvaluator() silhouette = evaluator.evaluate(predictions)
附录:完整python代码及实验结果
import os
import sys
os.environ['PYSPARK_PYTHON'] = r'D:\Anaconda\python.exe'
os.environ['PYSPARK_DRIVER_PYTHON'] = r'D:\Anaconda\python.exe'
from pyspark.sql import SparkSession
from pyspark.ml.feature import VectorAssembler, StandardScaler, PCA, StringIndexer
from pyspark.ml.clustering import KMeans
from pyspark.ml.evaluation import ClusteringEvaluator
from pyspark.ml import Pipeline
from pyspark.sql.functions import lit # 新增lit函数
import matplotlib.pyplot as plt
from sklearn.metrics import adjusted_rand_score, normalized_mutual_info_score # 修正拼写错误
import numpy as np
from scipy.optimize import linear_sum_assignment
print("Python 路径验证:", sys.executable)
spark = SparkSession.builder \
.appName("LocalKMeans") \
.master("local[*]") \
.config("spark.driver.memory", "4g") \
.getOrCreate()
def load_data(spark, dataset_path):
df = spark.read.csv(dataset_path, header=True, inferSchema=True)
original_columns = df.columns
label_col = original_columns[-1]
feature_cols = original_columns[:-1]
indexer = StringIndexer(inputCol=label_col, outputCol="label")
df = indexer.fit(df).transform(df)
return df, feature_cols
def evaluate_clustering(predictions):
labels_true = np.array(predictions.select("label").rdd.flatMap(lambda x: x).collect(), dtype=int)
labels_pred = np.array(predictions.select("prediction").rdd.flatMap(lambda x: x).collect(), dtype=int)
max_pred = np.max(labels_pred)
max_true = np.max(labels_true)
n_classes = max(max_pred, max_true) + 1
confusion_matrix = np.zeros((n_classes, n_classes), dtype=int)
for true, pred in zip(labels_true, labels_pred):
if pred < n_classes and true < n_classes:
confusion_matrix[pred, true] += 1
row_ind, col_ind = linear_sum_assignment(-confusion_matrix)
acc = confusion_matrix[row_ind, col_ind].sum() / len(labels_true)
ari = adjusted_rand_score(labels_true, labels_pred)
nmi = normalized_mutual_info_score(labels_true, labels_pred) # 修正拼写
# 处理单簇情况
if len(np.unique(labels_pred)) == 1:
silhouette = None
else:
try:
evaluator = ClusteringEvaluator()
silhouette = evaluator.evaluate(predictions)
except Exception:
silhouette = None
return {
"Adjusted Rand Index": ari,
"Normalized Mutual Info": nmi,
"Aligned Accuracy": acc,
"Silhouette Score": silhouette
}
def visualize_clusters(pdf, k):
plt.figure(figsize=(10, 6))
scatter = plt.scatter(pdf['PC1'], pdf['PC2'], c=pdf['prediction'], cmap='rainbow', alpha=0.6)
plt.title(f"K-means Clustering (k={k})")
plt.xlabel("Principal Component 1")
plt.ylabel("Principal Component 2")
plt.colorbar(scatter)
plt.show()
if __name__ == "__main__":
DATASET_PATH = r"G:\Desktop\大三下\大数据\dataset\Iris.csv"
K_VALUES = [1, 2, 3]
MAX_ITER = 50
TOL = 1e-6
# 数据加载
df, feature_cols = load_data(spark, DATASET_PATH)
print("数据加载完成,样本数:", df.count())
print("使用的特征列:", feature_cols)
# 构建预处理管道
assembler = VectorAssembler(inputCols=feature_cols, outputCol="features")
scaler = StandardScaler(inputCol="features", outputCol="scaledFeatures")
pipeline = Pipeline(stages=[assembler, scaler])
pipeline_model = pipeline.fit(df)
processed_data = pipeline_model.transform(df).cache()
all_results = []
for k in K_VALUES:
print(f"\n=== 正在测试 k={k} ===")
if k == 1:
# 手动处理k=1的情况
predictions = processed_data.withColumn("prediction", lit(0))
print("预测标签范围 (k=1): [0]")
else:
# 正常训练模型
kmeans = KMeans(
featuresCol="scaledFeatures",
k=k,
maxIter=MAX_ITER,
tol=TOL,
initMode="k-means||"
)
model = kmeans.fit(processed_data)
predictions = model.transform(processed_data)
print(f"预测标签范围 (k={k}):",
sorted(predictions.select("prediction").distinct().rdd.flatMap(lambda x: x).collect()))
# 评估模型
metrics = evaluate_clustering(predictions)
all_results.append((k, metrics))
# 可视化(k>1时)
if k > 1:
pca = PCA(k=2, inputCol="scaledFeatures", outputCol="pcaFeatures")
pca_model = pca.fit(processed_data)
pca_data = pca_model.transform(predictions)
pdf = pca_data.select("pcaFeatures", "prediction").toPandas()
pdf['PC1'] = pdf['pcaFeatures'].apply(lambda v: v[0])
pdf['PC2'] = pdf['pcaFeatures'].apply(lambda v: v[1])
visualize_clusters(pdf, k)
# 结果对比
print("\n=== 综合评估结果对比 ===")
print(f"{'K值':<5} | {'ARI':<8} | {'NMI':<8} | {'准确率':<8} | {'轮廓系数':<8}")
print("-" * 50)
for k, metrics in all_results:
silhouette = metrics['Silhouette Score']
print(f"{k:<5} | "
f"{metrics['Adjusted Rand Index']:.4f} | "
f"{metrics['Normalized Mutual Info']:.4f} | "
f"{metrics['Aligned Accuracy']:.4f} | "
f"{silhouette if silhouette is not None else 'N/A':<8}")
processed_data.unpersist()
spark.stop()终端输出:
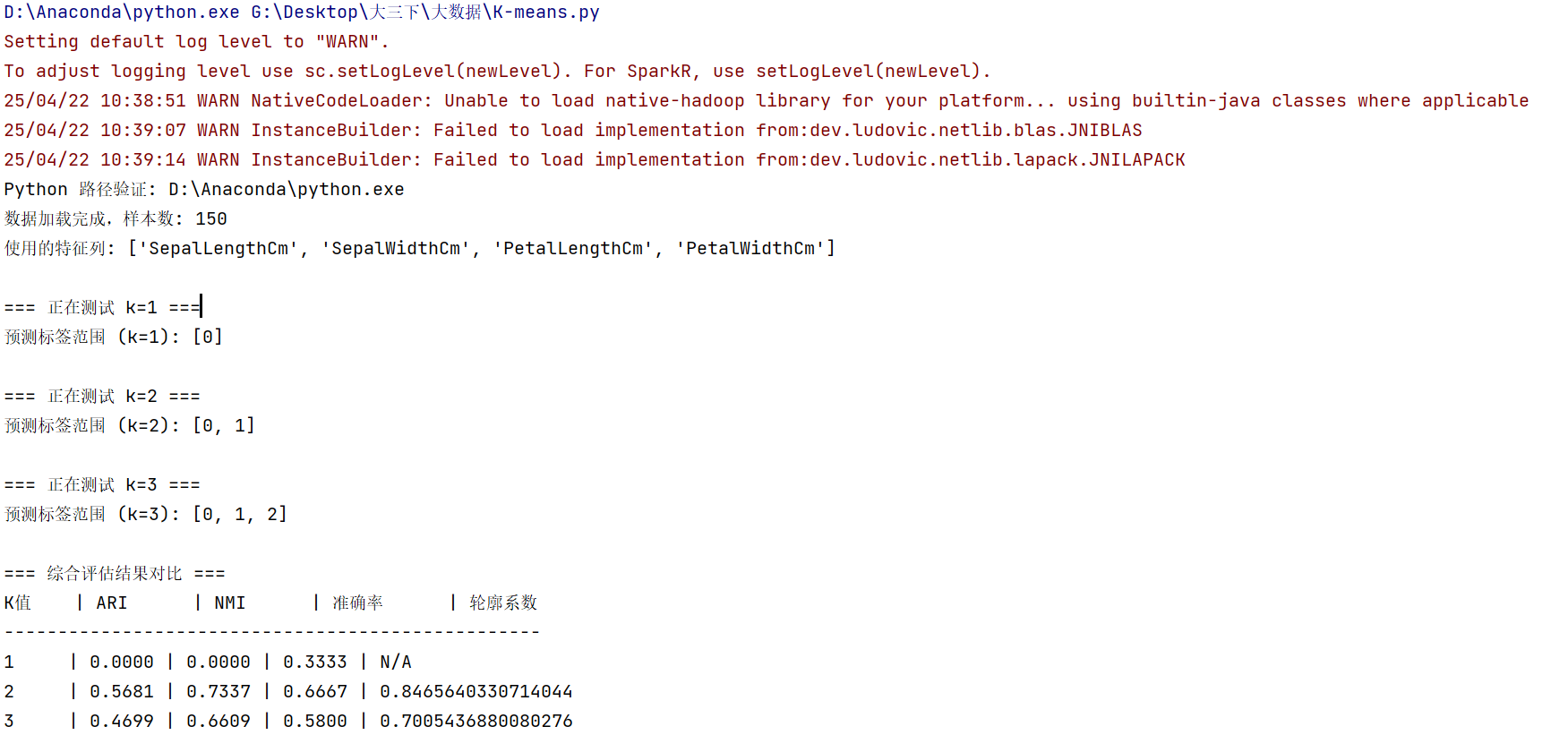
K值为2:
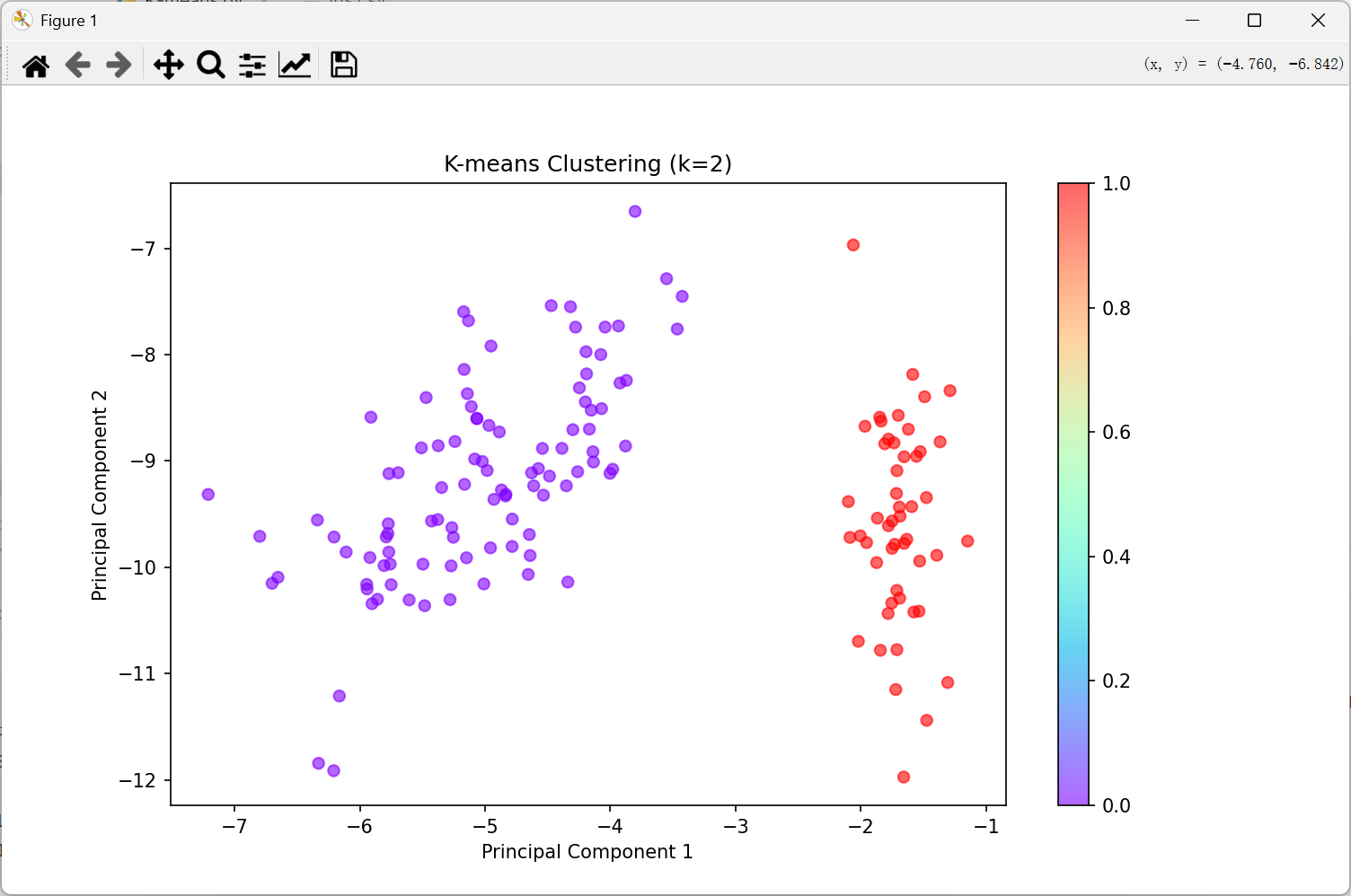
K值为3:
数据集:
SepalLengthCm,SepalWidthCm,PetalLengthCm,PetalWidthCm,Species
5.1,3.5,1.4,0.2,Iris-setosa
4.9,3.0,1.4,0.2,Iris-setosa
4.7,3.2,1.3,0.2,Iris-setosa
4.6,3.1,1.5,0.2,Iris-setosa
5.0,3.6,1.4,0.2,Iris-setosa
5.4,3.9,1.7,0.4,Iris-setosa
4.6,3.4,1.4,0.3,Iris-setosa
5.0,3.4,1.5,0.2,Iris-setosa
4.4,2.9,1.4,0.2,Iris-setosa
4.9,3.1,1.5,0.1,Iris-setosa
5.4,3.7,1.5,0.2,Iris-setosa
4.8,3.4,1.6,0.2,Iris-setosa
4.8,3.0,1.4,0.1,Iris-setosa
4.3,3.0,1.1,0.1,Iris-setosa
5.8,4.0,1.2,0.2,Iris-setosa
5.7,4.4,1.5,0.4,Iris-setosa
5.4,3.9,1.3,0.4,Iris-setosa
5.1,3.5,1.4,0.3,Iris-setosa
5.7,3.8,1.7,0.3,Iris-setosa
5.1,3.8,1.5,0.3,Iris-setosa
5.4,3.4,1.7,0.2,Iris-setosa
5.1,3.7,1.5,0.4,Iris-setosa
4.6,3.6,1.0,0.2,Iris-setosa
5.1,3.3,1.7,0.5,Iris-setosa
4.8,3.4,1.9,0.2,Iris-setosa
5.0,3.0,1.6,0.2,Iris-setosa
5.0,3.4,1.6,0.4,Iris-setosa
5.2,3.5,1.5,0.2,Iris-setosa
5.2,3.4,1.4,0.2,Iris-setosa
4.7,3.2,1.6,0.2,Iris-setosa
4.8,3.1,1.6,0.2,Iris-setosa
5.4,3.4,1.5,0.4,Iris-setosa
5.2,4.1,1.5,0.1,Iris-setosa
5.5,4.2,1.4,0.2,Iris-setosa
4.9,3.1,1.5,0.2,Iris-setosa
5.0,3.2,1.2,0.2,Iris-setosa
5.5,3.5,1.3,0.2,Iris-setosa
4.9,3.6,1.4,0.1,Iris-setosa
4.4,3.0,1.3,0.2,Iris-setosa
5.1,3.4,1.5,0.2,Iris-setosa
5.0,3.5,1.3,0.3,Iris-setosa
4.5,2.3,1.3,0.3,Iris-setosa
4.4,3.2,1.3,0.2,Iris-setosa
5.0,3.5,1.6,0.6,Iris-setosa
5.1,3.8,1.9,0.4,Iris-setosa
4.8,3.0,1.4,0.3,Iris-setosa
5.1,3.8,1.6,0.2,Iris-setosa
4.6,3.2,1.4,0.2,Iris-setosa
5.3,3.7,1.5,0.2,Iris-setosa
5.0,3.3,1.4,0.2,Iris-setosa
7.0,3.2,4.7,1.4,Iris-versicolor
6.4,3.2,4.5,1.5,Iris-versicolor
6.9,3.1,4.9,1.5,Iris-versicolor
5.5,2.3,4.0,1.3,Iris-versicolor
6.5,2.8,4.6,1.5,Iris-versicolor
5.7,2.8,4.5,1.3,Iris-versicolor
6.3,3.3,4.7,1.6,Iris-versicolor
4.9,2.4,3.3,1.0,Iris-versicolor
6.6,2.9,4.6,1.3,Iris-versicolor
5.2,2.7,3.9,1.4,Iris-versicolor
5.0,2.0,3.5,1.0,Iris-versicolor
5.9,3.0,4.2,1.5,Iris-versicolor
6.0,2.2,4.0,1.0,Iris-versicolor
6.1,2.9,4.7,1.4,Iris-versicolor
5.6,2.9,3.6,1.3,Iris-versicolor
6.7,3.1,4.4,1.4,Iris-versicolor
5.6,3.0,4.5,1.5,Iris-versicolor
5.8,2.7,4.1,1.0,Iris-versicolor
6.2,2.2,4.5,1.5,Iris-versicolor
5.6,2.5,3.9,1.1,Iris-versicolor
5.9,3.2,4.8,1.8,Iris-versicolor
6.1,2.8,4.0,1.3,Iris-versicolor
6.3,2.5,4.9,1.5,Iris-versicolor
6.1,2.8,4.7,1.2,Iris-versicolor
6.4,2.9,4.3,1.3,Iris-versicolor
6.6,3.0,4.4,1.4,Iris-versicolor
6.8,2.8,4.8,1.4,Iris-versicolor
6.7,3.0,5.0,1.7,Iris-versicolor
6.0,2.9,4.5,1.5,Iris-versicolor
5.7,2.6,3.5,1.0,Iris-versicolor
5.5,2.4,3.8,1.1,Iris-versicolor
5.5,2.4,3.7,1.0,Iris-versicolor
5.8,2.7,3.9,1.2,Iris-versicolor
6.0,2.7,5.1,1.6,Iris-versicolor
5.4,3.0,4.5,1.5,Iris-versicolor
6.0,3.4,4.5,1.6,Iris-versicolor
6.7,3.1,4.7,1.5,Iris-versicolor
6.3,2.3,4.4,1.3,Iris-versicolor
5.6,3.0,4.1,1.3,Iris-versicolor
5.5,2.5,4.0,1.3,Iris-versicolor
5.5,2.6,4.4,1.2,Iris-versicolor
6.1,3.0,4.6,1.4,Iris-versicolor
5.8,2.6,4.0,1.2,Iris-versicolor
5.0,2.3,3.3,1.0,Iris-versicolor
5.6,2.7,4.2,1.3,Iris-versicolor
5.7,3.0,4.2,1.2,Iris-versicolor
5.7,2.9,4.2,1.3,Iris-versicolor
6.2,2.9,4.3,1.3,Iris-versicolor
5.1,2.5,3.0,1.1,Iris-versicolor
5.7,2.8,4.1,1.3,Iris-versicolor
6.3,3.3,6.0,2.5,Iris-virginica
5.8,2.7,5.1,1.9,Iris-virginica
7.1,3.0,5.9,2.1,Iris-virginica
6.3,2.9,5.6,1.8,Iris-virginica
6.5,3.0,5.8,2.2,Iris-virginica
7.6,3.0,6.6,2.1,Iris-virginica
4.9,2.5,4.5,1.7,Iris-virginica
7.3,2.9,6.3,1.8,Iris-virginica
6.7,2.5,5.8,1.8,Iris-virginica
7.2,3.6,6.1,2.5,Iris-virginica
6.5,3.2,5.1,2.0,Iris-virginica
6.4,2.7,5.3,1.9,Iris-virginica
6.8,3.0,5.5,2.1,Iris-virginica
5.7,2.5,5.0,2.0,Iris-virginica
5.8,2.8,5.1,2.4,Iris-virginica
6.4,3.2,5.3,2.3,Iris-virginica
6.5,3.0,5.5,1.8,Iris-virginica
7.7,3.8,6.7,2.2,Iris-virginica
7.7,2.6,6.9,2.3,Iris-virginica
6.0,2.2,5.0,1.5,Iris-virginica
6.9,3.2,5.7,2.3,Iris-virginica
5.6,2.8,4.9,2.0,Iris-virginica
7.7,2.8,6.7,2.0,Iris-virginica
6.3,2.7,4.9,1.8,Iris-virginica
6.7,3.3,5.7,2.1,Iris-virginica
7.2,3.2,6.0,1.8,Iris-virginica
6.2,2.8,4.8,1.8,Iris-virginica
6.1,3.0,4.9,1.8,Iris-virginica
6.4,2.8,5.6,2.1,Iris-virginica
7.2,3.0,5.8,1.6,Iris-virginica
7.4,2.8,6.1,1.9,Iris-virginica
7.9,3.8,6.4,2.0,Iris-virginica
6.4,2.8,5.6,2.2,Iris-virginica
6.3,2.8,5.1,1.5,Iris-virginica
6.1,2.6,5.6,1.4,Iris-virginica
7.7,3.0,6.1,2.3,Iris-virginica
6.3,3.4,5.6,2.4,Iris-virginica
6.4,3.1,5.5,1.8,Iris-virginica
6.0,3.0,4.8,1.8,Iris-virginica
6.9,3.1,5.4,2.1,Iris-virginica
6.7,3.1,5.6,2.4,Iris-virginica
6.9,3.1,5.1,2.3,Iris-virginica
5.8,2.7,5.1,1.9,Iris-virginica
6.8,3.2,5.9,2.3,Iris-virginica
6.7,3.3,5.7,2.5,Iris-virginica
6.7,3.0,5.2,2.3,Iris-virginica
6.3,2.5,5.0,1.9,Iris-virginica
6.5,3.0,5.2,2.0,Iris-virginica
6.2,3.4,5.4,2.3,Iris-virginica
5.9,3.0,5.1,1.8,Iris-virginica目录:

















 967
967

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









