作品展示

背景需求:
【教学类-52-03】20240412动物数独(4宫格)难度1-9 打印版-CSDN博客文章浏览阅读603次,点赞20次,收藏8次。【教学类-52-03】20240412动物数独(4宫格)难度1-9 打印版 https://blog.csdn.net/reasonsummer/article/details/137695074
https://blog.csdn.net/reasonsummer/article/details/137695074
前文提到4宫格16格子,抽取10%-90%的空格,并不能实现空1、空2、空3……空12的结果
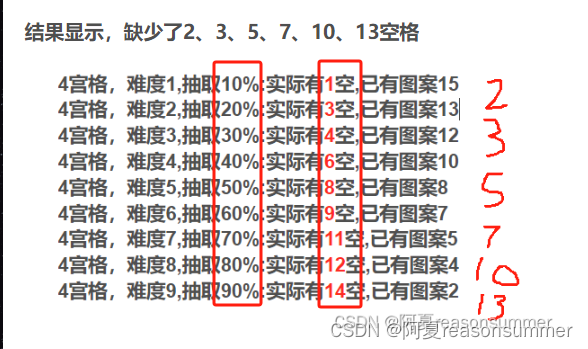
通过代码验证这个结果
'''
4宫格难度1-难度9(抽取10%-90%的空格)实际是几个空?
作者:阿夏
时间:2024年4月12日
'''
n=4
g=n*n
for i in range(1,10):
print(f'{n}宫格,难度{i},抽取{i*10}%:实际有{int(g*i*10/100)}空,已有图案{g-int(g*i*10/100)}')
# # 4宫格,难度1,抽取10%:实际有1空,已有图案15
# # 4宫格,难度2,抽取20%:实际有3空,已有图案13
# # 4宫格,难度3,抽取30%:实际有4空,已有图案12
# # 4宫格,难度4,抽取40%:实际有6空,已有图案10
# # 4宫格,难度5,抽取50%:实际有8空,已有图案8
# # 4宫格,难度6,抽取60%:实际有9空,已有图案7
# # 4宫格,难度7,抽取70%:实际有11空,已有图案5
# # 4宫格,难度8,抽取80%:实际有12空,已有图案4
# # 4宫格,难度9,抽取90%:实际有14空,已有图案2
如何确保第1关空1格、第2关空2格呢?
'''
4宫格难度1-难度9(抽取10%-90%的空格)实际是几个空?用float作出1-12空所有的可能性
作者:阿夏
时间:2024年4月12日
'''
# 宫格数
n=4
# 多少个格子
g=n*n
a=[]
# 用1-100来测试百分比数字
for i in range(1,101):
# print(f'{n}宫格,难度{i:02d},抽取{i}%:实际有{int(g*i/100):02d}空,已有图案{g-int(g*i/100):02d}')
a.append(f'{n}宫格,难度{i:02d},抽取{i:02d}%:实际有{int(g*i/100):02d}空,已有图案{g-int(g*i/100):02d}')# 全部加2尾数,统一长度
print(a)
# ['4宫格,难度01,抽取1%:实际有00空,已有图案16', '4宫格,难度02,抽取2%:实际有00空,已有图案16', '4宫格,难度03,抽取3%:实际有00空,已有图案16', '4宫格,难度04,抽取4%:实际有00空,已有图案16', '4宫
# 格,难度05,抽取5%:实际有00空,已有图案16', '4宫格,难度06,抽取6%:实际有00空,已有图案16', '4宫格,难度07,抽取7%:实际有01空,已有图案15', '4宫格,难度08,抽取8%:实际有01空,已有图案15', '4宫格,难
# 度09,抽取9%:实际有01空,已有图案15', '4宫格,难度10,抽取10%:实际有01空,已有图案15', '4宫格,难度11,抽取11%:实际有01空,已有图案15', '4宫格,难度12,抽取12%:实际有01空,已有图案15', '4宫格,难度13,抽取13%:实际有02空,已有图案14', '4宫格,难度14,抽取14%:实际有02空,已有图案14', '4宫格,难度15,抽取15%:实际有02空,已有图案14', '4宫格,难度16,抽取16%:实际有02空,已有图案14', '4宫格,难度17,抽取17%:实际有02空,已有图案14', '4宫格,难度18,抽取18%:实际有02空,已有图案14', '4宫格,难度19,抽取19%:实际有03空,已有图案13', '4宫格,难度20,抽取20%:实际有03空,已有图案13', '4宫格,难度21,抽
# 取21%:实际有03空,已有图案13', '4宫格,难度22,抽取22%:实际有03空,已有图案13', '4宫格,难度23,抽取23%:实际有03空,已有图案13', '4宫格,难度24,抽取24%:实际有03空,已有图案13', '4宫格,难度25,抽取
# 25%:实际有04空,已有图案12', '4宫格,难度26,抽取26%:实际有04空,已有图案12', '4宫格,难度27,抽取27%:实际有04空,已有图案12', '4宫格,难度28,抽取28%:实际有04空,已有图案12', '4宫格,难度29,抽取29%:实际有04空,已有图案12', '4宫格,难度30,抽取30%:实际有04空,已有图案12', '4宫格,难度31,抽取31%:实际有04空,已有图案12', '4宫格,难度32,抽取32%:实际有05空,已有图案11', '4宫格,难度33,抽取33%:实际有05空,已有图案11', '4宫格,难度34,抽取34%:实际有05空,已有图案11', '4宫格,难度35,抽取35%:实际有05空,已有图案11', '4宫格,难度36,抽取36%:实际有05空,已有图案11', '4宫格,难度37,抽取37%:实
# 际有05空,已有图案11', '4宫格,难度38,抽取38%:实际有06空,已有图案10', '4宫格,难度39,抽取39%:实际有06空,已有图案10', '4宫格,难度40,抽取40%:实际有06空,已有图案10', '4宫格,难度41,抽取41%:实际
# 有06空,已有图案10', '4宫格,难度42,抽取42%:实际有06空,已有图案10', '4宫格,难度43,抽取43%:实际有06空,已有图案10', '4宫格,难度44,抽取44%:实际有07空,已有图案09', '4宫格,难度45,抽取45%:实际有
# 07空,已有图案09', '4宫格,难度46,抽取46%:实际有07空,已有图案09', '4宫格,难度47,抽取47%:实际有07空,已有图案09', '4宫格,难度48,抽取48%:实际有07空,已有图案09', '4宫格,难度49,抽取49%:实际有07空,已有图案09', '4宫格,难度50,抽取50%:实际有08空,已有图案08', '4宫格,难度51,抽取51%:实际有08空,已有图案08', '4宫格,难度52,抽取52%:实际有08空,已有图案08', '4宫格,难度53,抽取53%:实际有08空
# ,已有图案08', '4宫格,难度54,抽取54%:实际有08空,已有图案08', '4宫格,难度55,抽取55%:实际有08空,已有图案08', '4宫格,难度56,抽取56%:实际有08空,已有图案08', '4宫格,难度57,抽取57%:实际有09空,
# 已有图案07', '4宫格,难度58,抽取58%:实际有09空,已有图案07', '4宫格,难度59,抽取59%:实际有09空,已有图案07', '4宫格,难度60,抽取60%:实际有09空,已有图案07', '4宫格,难度61,抽取61%:实际有09空,已
# 有图案07', '4宫格,难度62,抽取62%:实际有09空,已有图案07', '4宫格,难度63,抽取63%:实际有10空,已有图案06', '4宫格,难度64,抽取64%:实际有10空,已有图案06', '4宫格,难度65,抽取65%:实际有10空,已有
# 图案06', '4宫格,难度66,抽取66%:实际有10空,已有图案06', '4宫格,难度67,抽取67%:实际有10空,已有图案06', '4宫格,难度68,抽取68%:实际有10空,已有图案06', '4宫格,难度69,抽取69%:实际有11空,已有图
# 案05', '4宫格,难度70,抽取70%:实际有11空,已有图案05', '4宫格,难度71,抽取71%:实际有11空,已有图案05', '4宫格,难度72,抽取72%:实际有11空,已有图案05', '4宫格,难度73,抽取73%:实际有11空,已有图案
# 05', '4宫格,难度74,抽取74%:实际有11空,已有图案05', '4宫格,难度75,抽取75%:实际有12空,已有图案04', '4宫格,难度76,抽取76%:实际有12空,已有图案04', '4宫格,难度77,抽取77%:实际有12空,已有图案04', '4宫格,难度78,抽取78%:实际有12空,已有图案04', '4宫格,难度79,抽取79%:实际有12空,已有图案04', '4宫格,难度80,抽取80%:实际有12空,已有图案04', '4宫格,难度81,抽取81%:实际有12空,已有图案04', '4宫格,难度82,抽取82%:实际有13空,已有图案03', '4宫格,难度83,抽取83%:实际有13空,已有图案03', '4宫格,难度84,抽取84%:实际有13空,已有图案03', '4宫格,难度85,抽取85%:实际有13空,已有图案03', '4宫格,难度86,抽取86%:实际有13空,已有图案03', '4宫格,难度87,抽取87%:实际有13空,已有图案03', '4宫格,难度88,抽取88%:实际有14空,已有图案02', '4宫格,难度89,抽取89%:实际有14空,已有图案02', '4
# 宫格,难度90,抽取90%:实际有14空,已有图案02', '4宫格,难度91,抽取91%:实际有14空,已有图案02', '4宫格,难度92,抽取92%:实际有14空,已有图案02', '4宫格,难度93,抽取93%:实际有14空,已有图案02', '4宫
# 格,难度94,抽取94%:实际有15空,已有图案01', '4宫格,难度95,抽取95%:实际有15空,已有图案01', '4宫格,难度96,抽取96%:实际有15空,已有图案01', '4宫格,难度97,抽取97%:实际有15空,已有图案01', '4宫格
# ,难度98,抽取98%:实际有15空,已有图案01', '4宫格,难度99,抽取99%:实际有15空,已有图案01', '4宫格,难度100,抽取100%:实际有16空,已有图案00']
print(len(a))
# 100
# 创建一个空列表用于存储匹配的元素
b = []
# 遍历原始列表
for element in a:
# 如果找到匹配的元素,以":"为分隔符将字符串分割成两部分
parts = element.split(":")
# print(parts)
# # 提取第一部分中包含的数字信息
info = parts[1]
b.append(info)
# 对列表b进行排序,并去除重复项
b = list(set(b))
# 倒叙排列
b.sort(reverse=False)
print(b)
# ['实际有00空,已有图案16', '实际有01空,已有图案15', '实际有02空,已有图案14', '实际有03空,已有图案13', '实际有04空,已有图案12', '实际有05空,已有图案11', '实际有06空,已有图案10', '实际有07空,已
# 有图案09', '实际有08空,已有图案08', '实际有09空,已有图案07', '实际有10空,已有图案06', '实际有11空,已有图案05', '实际有12空,已有图案04', '实际有13空,已有图案03', '实际有14空,已有图案02', '实
# 际有15空,已有图案01', '实际有16空,已有图案00']
print(len(b))
# 17
#当“实际有08空,已有图案08”文字与a列表元素后半部分相同,就写入第一个,后面相同的都跳过(第一个就是最先出现空格数量的百分比,
f=[]
g=[]
for d in range(len(b)):
for c in a:
# print(c)
# 读取一个就中断
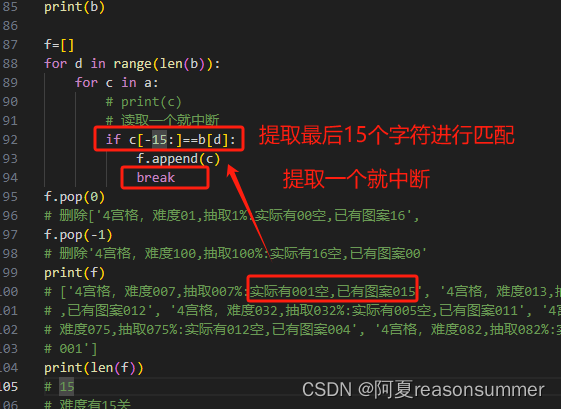
if c[-13:]==b[d]:
f.append(c)
break
# g.append(f)
f.pop(0)
# 删除['4宫格,难度01,抽取1%:实际有00空,已有图案16',
f.pop(-1)
# 删除'4宫格,难度100,抽取100%:实际有16空,已有图案00'
print(f)
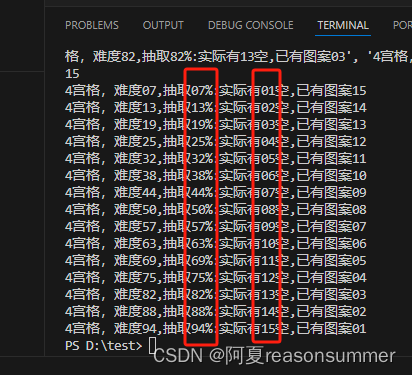
# ['4宫格,难度07,抽取7%:实际有01空,已有图案15', '4宫格,难度13,抽取13%:实际有02空,已有图案14', '4宫格,难度19,抽取19%:实际有03空,已有图案13', '4宫格,难度25,抽取25%:实际有04空,已有图案12', '4宫格,难度32,抽取32%:实际有05空,已有图案11', '4宫格,难度38,抽取38%:实际有06空,已有图案10', '4宫格,难度44,抽取44%:实际有07空,已有图案09', '4宫格,难度50,抽取50%:实际有08空,已有图案08', '4宫
# 格,难度57,抽取57%:实际有09空,已有图案07', '4宫格,难度63,抽取63%:实际有10空,已有图案06', '4宫格,难度69,抽取69%:实际有11空,已有图案05', '4宫格,难度75,抽取75%:实际有12空,已有图案04', '4宫格
# ,难度82,抽取82%:实际有13空,已有图案03', '4宫格,难度88,抽取88%:实际有14空,已有图案02', '4宫格,难度94,抽取94%:实际有15空,已有图案01']
print(len(f))
# 15
# 难度有15关
for ff in f:
print(ff)
抽空格的百分数字,及实现的空格数量
修改代码


代码展示
# 测试11*11格,2*2一共4套3*3 宫格
'''
目的:
1、动物数独04 a4横版 2个4*4宫格(连在一起的,横版加标题、
2、测试空1格,需要抽多少百分数,空2格需要多少百分树,用int(float)作出1-15空所有的可能性
时间:2024年4月12日
作者:「Vaeeeeeee」,AI对话大师,阿夏
时间:2024年4月12日 13:35
'''
import random,time
from win32com.client import constants,gencache
from win32com.client.gencache import EnsureDispatch
from win32com.client import constants # 导入枚举常数模块
import os,time
import docx
from docx import Document
from docx.shared import Pt
from docx.shared import RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
from docxtpl import DocxTemplate
import pandas as pd
from docx2pdf import convert
from docx.shared import RGBColor
from docx import Document
from docx.shared import Cm
from docx.enum.text import WD_ALIGN_PARAGRAPH, WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import nsdecls
from docx.oxml import parse_xml
# 生成题库
import random
import copy
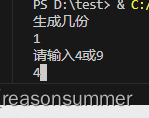
num=int(input('生成几份\n'))
# 制作"单元格"# 几宫格
hsall=int(input('请输入4或9\n'))
hs=hsall
# kk=int(input('空格数量,输入5,就是50%,就是空一半)\n'))
print('------1、如果正好想生成1空、2空、3空、4空的数字,需要测算百分比的具体数字------')
n=hsall
g=n*n
a=[]
for i in range(1,101):
# 因为有100,所以三位数
print(f'{n}宫格,难度{i:03d},抽取{i:03d}%:实际有{int(g*i/100):03d}空,已有图案{g-int(g*i/100):03d}')
a.append(f'{n}宫格,难度{i:03d},抽取{i:03d}%:实际有{int(g*i/100):03d}空,已有图案{g-int(g*i/100):03d}')
# print(a)
# print(len(a))
# 用冒号分割,如果0空,加入,
# 创建一个空列表用于存储匹配的元素
b = []
# 遍历原始列表
for element in a:
# 如果找到匹配的元素,以":"为分隔符将字符串分割成两部分
parts = element.split(":")
# print(parts)
# # 提取第一部分中包含的数字信息
info = parts[1]
b.append(info)
# 对列表b进行排序,并去除重复项
b = list(set(b))
b.sort(reverse=False)
print(b)
f=[]
for d in range(len(b)):
for c in a:
# print(c)
# 读取一个就中断
if c[-15:]==b[d]:
f.append(c)
break
f.pop(0)
# 删除['4宫格,难度01,抽取1%:实际有00空,已有图案16',
f.pop(-1)
# 删除'4宫格,难度100,抽取100%:实际有16空,已有图案00'
print(f)
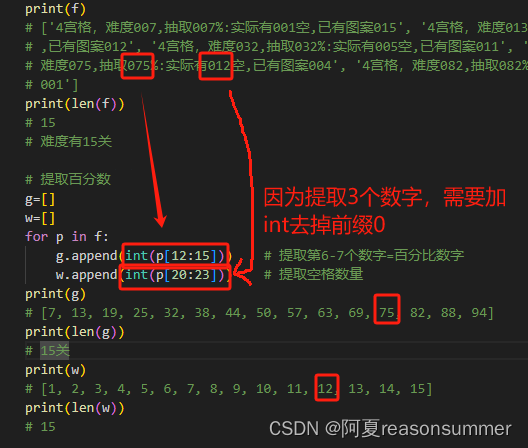
# ['4宫格,难度007,抽取007%:实际有001空,已有图案015', '4宫格,难度013,抽取013%:实际有002空,已有图案014', '4宫格,难度019,抽取019%:实际有003空,已有图案013', '4宫格,难度025,抽取025%:实际有004空
# ,已有图案012', '4宫格,难度032,抽取032%:实际有005空,已有图案011', '4宫格,难度038,抽取038%:实际有006空,已有图案010', '4宫格,难度044,抽取044%:实际有007空,已有图案009', '4宫格,难度050,抽取050%:实际有008空,已有图案008', '4宫格,难度057,抽取057%:实际有009空,已有图案007', '4宫格,难度063,抽取063%:实际有010空,已有图案006', '4宫格,难度069,抽取069%:实际有011空,已有图案005', '4宫格,
# 难度075,抽取075%:实际有012空,已有图案004', '4宫格,难度082,抽取082%:实际有013空,已有图案003', '4宫格,难度088,抽取088%:实际有014空,已有图案002', '4宫格,难度094,抽取094%:实际有015空,已有图案
# 001']
print(len(f))
# 15
# 难度有15关
# 提取百分数
g=[]
w=[]
for p in f:
g.append(int(p[12:15])) # 提取第6-7个数字=百分比数字
w.append(int(p[20:23])) # 提取空格数量
print(g)
# [7, 13, 19, 25, 32, 38, 44, 50, 57, 63, 69, 75, 82, 88, 94]
print(len(g))
# 15关
print(w)
# [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]
print(len(w))
# 15
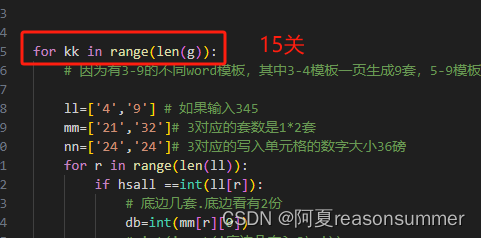
for kk in range(len(g)):
# 因为有3-9的不同word模板,其中3-4模板一页生成9套,5-9模板一页生成6套,这里直接生成边长
ll=['4','9'] # 如果输入345
mm=['21','32']# 3对应的套数是1*2套
nn=['24','24']# 3对应的写入单元格的数字大小36磅
for r in range(len(ll)):
if hsall ==int(ll[r]):
# 底边几套.底边看有2份
db=int(mm[r][0])
# int(input('底边几套? 3\n'))
# 侧边几套 侧边看也是2份
print(db )
cb=int(mm[r][1])
# int(input('侧边几套? 2\n'))
print(cb)
size=int(nn[r])
print(size) # 写入单元格数字的大小(撑满格子)
path=r'C:\Users\jg2yXRZ\OneDrive\桌面\动物数独'
# 新建一个”装N份word和PDF“的临时文件夹
imagePath=path+r'\\零时Word'
if not os.path.exists(imagePath): # 判断存放图片的文件夹是否存在
os.makedirs(imagePath) # 若图片文件夹不存在就创建
# 计算不同模板中的单元格坐标,放在bg里
# 棋盘格子数量,
# 如果正方形:底边2*侧边2,就是3*3宫格 2*2=4套,底边边格子数量就是3*2+1=7,侧边格子数量就是3*2+1=7,
# 如果长方形:底边3*侧边2,就是3*3宫格,3*2=6套 底边格子数量就是3*3+2=11,侧边格子数量就是3*2+1=7,
# if db==cb:
db_size = hs*db+db-1
cb_size= hs*cb+cb-1
print('{}宫格排列底{}侧{}共{}套,底边格子数{}'.format(hs,db,cb,db*cb,db_size ))
print('{}宫格排列底{}侧{}共{}套,侧边格子数{}'.format(hs,db,cb,db*cb,cb_size ))
# 确定每个宫格的左上角坐标 00 04 40 44
bgszm=[]
for a in range(0,cb_size,hs+1): # 0-11每隔4,写一个坐标 侧边y
for b in range(0,db_size,hs+1): # 0-11每隔4,写一个坐标 侧边x
bgszm.append('{}{}'.format('%02d'%a,'%02d'%b))
print(bgszm)
# 3宫格排列底3侧2共6套,底边格子数11
# 3宫格排列底3侧2共6套,侧边格子数7
# ['0000', '0004', '0008', '0400', '0404', '0408']
# 转为元祖
start_coordinates = [(int(s[0:2]), int(s[2:4])) for s in bgszm]
cell_coordinates = []
# 推算每个起始格子后面的单元格数字
for start_coord in start_coordinates:
i, j = start_coord
subgrid_coordinates = []
for x in range(hs):
for y in range(hs):
subgrid_coordinates.append((i + x, j + y))
cell_coordinates.append(subgrid_coordinates)
# 打印结果(元祖样式)
bg=[]
for coordinates in cell_coordinates:
# print(coordinates) # [(4, 8), (4, 9), (4, 10), (5, 8), (5, 9), (5, 10), (6, 8), (6, 9), (6, 10)]
for c in coordinates:
print(c) # 元组 (1, 2) 样式
s = ''.join(str(num).zfill(2) for num in c) # zfill将元组 (1, 2) 转换为字符串 '0102' 特别是(5,10)这种必须转成2个数字0510
print(str(s)) # '12'
bg.append(s) # '0102'
print(bg)
# 生成PDf
P=[]
for z in range(num):
P.clear()
# 制作4份数据
for j in range(db*cb): # 3宫格,4*3=12套
# ————————————————
# 版权声明:本文为CSDN博主「Vaeeeeeee」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
# 原文链接:https://blog.csdn.net/m0_46366547/article/details/131334720
def generate_sudoku_board():
# 创建一个9x9的二维列表,表示数独棋盘
board = [[0] * hs for _ in range(hs)]
# 递归函数,用于填充数独棋盘的每个单元格
def filling_board(row, col):
# 检查是否填充完成整个数独棋盘
if row == hs:
return True
# 计算下一个单元格的行和列索引
next_row = row if col < hs-1 else row + 1
next_col = (col + 1) % hs
import math
r = int(math.sqrt(hs))
print(r)
# 获取当前单元格在小九宫格中的索引
box_row = row // r
box_col = col // r
# 随机生成1到9的数字
numbers = random.sample(range(1, hs+1), hs)
for num in numbers:
# 检查行、列、小九宫格是否已经存在相同的数字
if num not in board[row] and all(board[i][col] != num for i in range(hs)) and all(num != board[i][j] for i in range(box_row*r, box_row*r+r) for j in range(box_col*r, box_col*r+r)):
board[row][col] = num
# 递归填充下一个单元格
if filling_board(next_row, next_col):
return True
# 回溯,将当前单元格重置为0
board[row][col] = 0
return False
# 填充数独棋盘
filling_board(0, 0)
return board
# 这一块是按照等级随机产生空格,数量不稳定,
# def create_board(level): # level数字越大代表游戏难度越大,空白格子越多
# """
# 生成一个随机的数独棋盘,空白格少
# """
# board = generate_sudoku_board()
# board1 = copy.deepcopy(board)
# for i in range(hs*hs):
# row = i // hs
# col = i % hs
# if random.randint(0, hs) < level: # 随机数量
# board1[row][col] = 0 # 格子填充为0
# return (board,board1)
# if hs==9:
# v = create_board(5)[1]
# print(v)
# if hs==4:
# v = create_board(3)[1]
# print(v)
# 定量出现空白格子
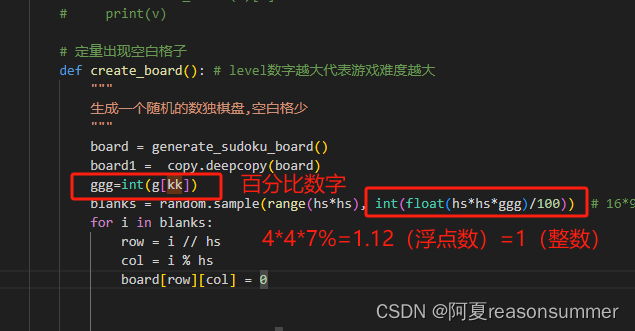
def create_board(): # level数字越大代表游戏难度越大
"""
生成一个随机的数独棋盘,空白格少
"""
board = generate_sudoku_board()
board1 = copy.deepcopy(board)
ggg=int(g[kk])
blanks = random.sample(range(hs*hs), int(float(hs*hs*ggg)/100)) # 16*97/100=15.52是浮点数,然后再转成整数
for i in blanks:
row = i // hs
col = i % hs
board[row][col] = 0
# if random.randint(0, hs) < level:
# board1[row][col] = 0
return board
v = create_board()
# 数字越小,空格少
# 数字大,空格多
# 这里无法控制空格的数量
# 提取每个元素
for a1 in v: # 第一次读取,[a,b][c,d][e,f]的内容-列表
for a2 in a1: # 第二次读取,[a,b,c,d,e,f]的内容-元素
if a2==0: # 如果某个元素==0,就替换成空
P.append('')
else: # 如果某个元素非0,就写入本身的数字
P.append(a2)
print(P)
print(len(P))
Q=P
doc = Document(path+r'\动物数独(四宫格横板).docx')
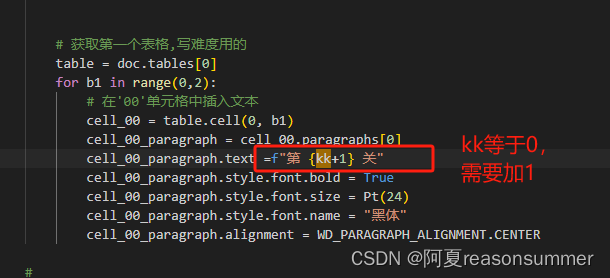
# 获取第一个表格,写难度用的
table = doc.tables[0]
for b1 in range(0,2):
# 在'00'单元格中插入文本
cell_00 = table.cell(0, b1)
cell_00_paragraph = cell_00.paragraphs[0]
cell_00_paragraph.text =f"第 {kk+1} 关"
cell_00_paragraph.style.font.bold = True
cell_00_paragraph.style.font.size = Pt(24)
cell_00_paragraph.style.font.name = "黑体"
cell_00_paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
#
table = doc.tables[1] # 表0,表2 写标题用的
# 标题写入3、5单元格
for t in range(0,len(bg)): # 0-5是最下面一行,用来写卡片数字
pp=int(bg[t][0:2]) #
qq=int(bg[t][2:4])
k=str(Q[t]) # 提取list图案列表里面每个图形 t=索引数字
print(pp,qq,k)
# 图案符号的字体、大小参数
run=table.cell(pp,qq).paragraphs[0].add_run(k) # 在单元格0,0(第1行第1列)输入第0个图图案
run.font.name = '黑体'#输入时默认华文彩云字体
# run.font.size = Pt(46) #输入字体大小默认30号 换行(一页一份大卡片
run.font.size = Pt(size) #是否加粗
# run.font.color.rgb = RGBColor(150,150,150) #数字小,颜色深0-255
run.font.color.rgb = RGBColor(50,50,50) #数字小,颜色深0-255
run.bold=True
# paragraph.paragraph_format.line_spacing = Pt(180) #数字段间距
r = run._element
r.rPr.rFonts.set(qn('w:eastAsia'), '黑体')#将输入语句中的中文部分字体变为华文行楷
table.cell(pp,qq).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER#居中
doc.save(imagePath+r'\{}.docx'.format('%02d'%(z+1)))#保存为XX学号的电话号码word
time.sleep(1)
from docx import Document
from docx.shared import Cm
# 读取四张卡通动物的文件名
animal_path = path+r'\02动物图片' # 替换为实际的文件夹路径
# 获取文件夹中所有文件的完整路径
file_paths = [os.path.join(animal_path, file_name) for file_name in os.listdir(animal_path)]
print(file_paths)
# 把数字1替换成01图片
# 打开Word文档
doc = Document(imagePath+r'\{}.docx'.format('%02d'%(z+1)))
# 获取所有表格
tables = doc.tables
# 遍历每个表格
for table in tables:
# 遍历表格的行
for i, row in enumerate(table.rows):
# 遍历行的单元格
for j, cell in enumerate(row.cells):
# 读取单元格的文本值
cell_text = cell.text
for x in range(0,4):
# 判断单元格的值是否为1
if cell_text == f'{x+1}':
# 删除原来的文本
cell.text = ''
# 插入图片
run = cell.paragraphs[0].add_run()
run.add_picture(file_paths[x], width=Cm(3), height=Cm(3))
# 设置图片对齐方式为居中
run.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
# 设置单元格的水平和垂直对齐方式为居中
cell.vertical_alignment = WD_ALIGN_PARAGRAPH.CENTER
cell.paragraphs[0].alignment = WD_ALIGN_PARAGRAPH.CENTER
# 保存修改后的文档
doc.save(imagePath+r'\{}.docx'.format('%02d'%(z+1)))
time.sleep(2)
# # 关闭Word文档
# doc.close()
time.sleep(2)
from docx2pdf import convert
# docx 文件另存为PDF文件
inputFile = imagePath+"\{}.docx".format('%02d'%(z+1))# 要转换的文件:已存在
outputFile = imagePath+"\{}.pdf".format('%02d'%(z+1)) # 要生成的文件:不存在
# 先创建 不存在的 文件
f1 = open(outputFile, 'w')
f1.close()
# 再转换往PDF中写入内容
convert(inputFile, outputFile)
print('----------第4步:把都有PDF合并为一个打印用PDF------------')
# 多个PDF合并(CSDN博主「红色小小螃蟹」,https://blog.csdn.net/yangcunbiao/article/details/125248205)
import os
from PyPDF2 import PdfMerger
target_path = imagePath
pdf_lst = [f for f in os.listdir(target_path) if f.endswith('.pdf')]
pdf_lst = [os.path.join(target_path, filename) for filename in pdf_lst]
pdf_lst.sort()
file_merger = PdfMerger()
for pdf in pdf_lst:
print(pdf)
file_merger.append(pdf)
# vv=w[kk]
file_merger.write(path+fr"\(打印合集) 动物拼图{hs}宫格 难度{kk+1:02d} 空{int(w[kk]):03d}格({db}乘{cb}等于{num}份{db*cb}张).pdf")
file_merger.close()
# doc.Close()
# # print('----------第5步:删除临时文件夹------------')
import shutil
shutil.rmtree(imagePath) #递归删除文件夹,即:删除非空文件夹
time.sleep(3) # 防止转换时报错,预留生成时间
# 最后把PDF合并
import os
from PyPDF2 import PdfMerger, PdfFileReader
# 创建一个PdfMerger对象
merger = PdfMerger()
# 遍历文件夹中的所有PDF文件
folder_path = path
for filename in os.listdir(folder_path):
if filename.endswith('.pdf'):
# 打开PDF文件
pdf_path = os.path.join(folder_path, filename)
pdf_file = open(pdf_path, 'rb')
pdf_reader = PdfFileReader(pdf_file)
# 将PDF文件添加到合并器中
merger.append(pdf_reader)
# 关闭当前打开的PDF文件
pdf_file.close()
# 保存合并后的PDF文件
output_path = path+r"\动物数独4宫格(空格1-15).pdf"
merger.write(output_path)
merger.close()
print("PDF文件合并完成!")
终端运行
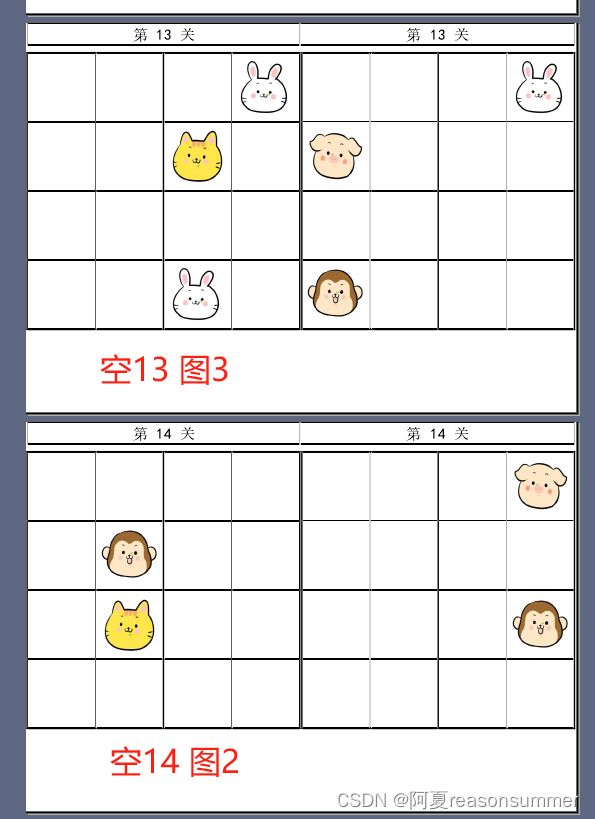
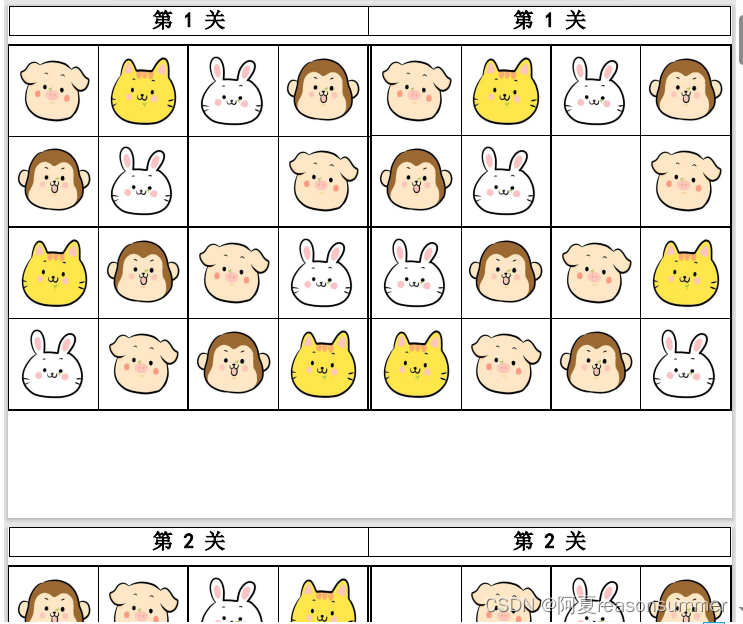
15种空格(空1-空15)

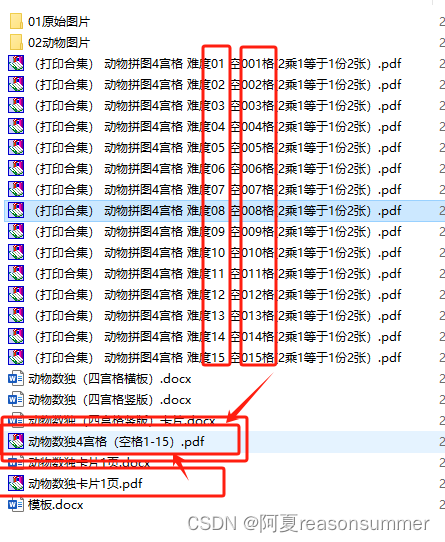
全部PDF合并在一起,第1个是数独卡片(dong)第2-16是排序的宫格图片(da)
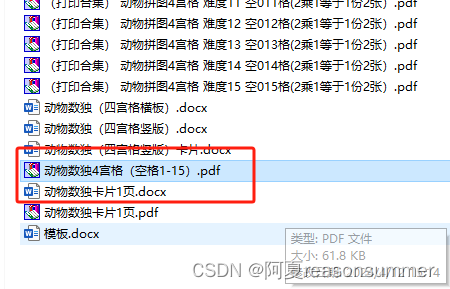
最终作品







特别说明:
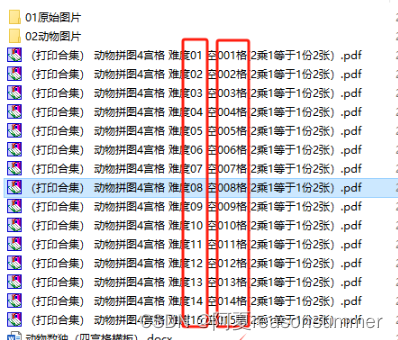
如果PDF的文件名不加“02d”和“03d”,PDF排序会出现“难度1”后面就是“难度10”的样式,最后的合并PDF会出现第1关后面是第10关,影响打印后的整理顺序。

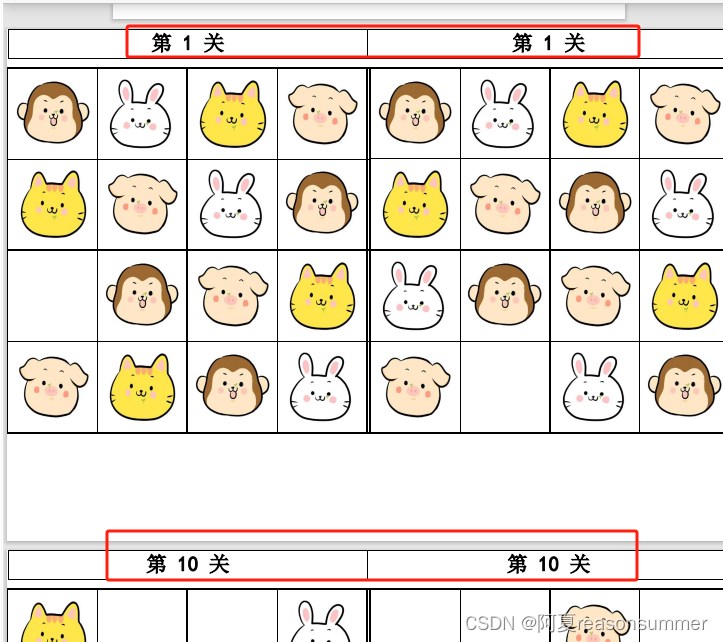
但是加“02d“和“03d”的文件名,不仅结构对称美观,而且PDF排序会出现“难度1”后面就是“难度2”的样式,让打印后不用整理
这下最完美的4*4宫格(16格)的空1-空15的代码都完成了,一共15关,但是打印1-12关就差不多了,
2024年4月27日,在做6宫格时,将动物卡片部分也并入数独底图代码中,合并成一个PDF打印
因此这里的4宫格数独,也制作成动物卡片(4张A4)并入输入底图代码中,合并成给一个PDF打印。
# 测试11*11格,2*2一共4套3*3 宫格
'''
4宫格合并版(复杂,图片很多)
0、制作动物数独的黏贴卡片 A4一页6张图片 9.85CM、
1、动物数独04 a4横版 2个4*4宫格(连在一起的,横版加标题、
2、测试空1格,需要抽多少百分数,空2格需要多少百分树,用int(float)作出1-15空所有的可能性
作者:AI对话大师,阿夏
时间:2024年4月26日
# '''
# print('----1、读取行列-------')
from docx import Document
from docx.shared import Cm
import os
path=r'C:\Users\jg2yXRZ\OneDrive\桌面\动物数独'
# # 新建一个”装N份word和PDF“的临时文件夹
imagePath=path+r'\零时Word'
os.makedirs(imagePath,exist_ok=True) # 若图片文件夹不存在就创建
imagePath2=path+r'\零时jpg'
os.makedirs(imagePath2,exist_ok=True)
imagePath3=path+r'\汇总'
os.makedirs(imagePath3,exist_ok=True)
# 打开.docx文件
doc = Document(path +r'\动物数独(四宫格竖版)卡片.docx')
# 获取文档中的所有表格
tables = doc.tables
# 选择你需要读取的表格(在这种情况下是第1张表格)
target_table = tables[0]
# 获取所选表格的行数和列数
num_rows = len(target_table.rows)
num_columns = len(target_table.columns)
print("行数:", num_rows)
# 3
print("列数:", num_columns)
# 2
# # 测算4类图片每种几张
sum=int(num_rows*num_columns)
print(sum)
#
print('----2、生成足够数量的图片-------')
import os
# 指定文件夹路径
folder_path =path+r'\02动物图片'
# 读取文件夹中所有文件的名称并加上路径
file_paths = [os.path.join(root, file) for root, dirs, files in os.walk(folder_path) for file in files]
print(file_paths)
file_paths=file_paths
pic_list=[]
# 打印文件名称和路径
for file_path in file_paths:
for i in range(int(sum/4)):
pic_list.append(file_path)
print(pic_list)
print(len(pic_list))
# # 5
print('----3、插入图片-------')
for f in range(4):
# 打开.docx文件
doc = Document(path+r'\动物数独(四宫格竖版)卡片.docx')
# 获取文档中的所有表格
tables = doc.tables
# 获取第一个表格
table = tables[0]
# 遍历表格的所有行和单元格
i = 0
for row in table.rows:
for cell in row.cells:
# 在单元格中插入图片
cell_paragraph = cell.paragraphs[0]
run = cell_paragraph.add_run()
run.add_picture(pic_list[i], width=Cm(3.2), height=Cm(3.2))
cell_paragraph.alignment = 1 # 设置单元格中的文本居中
i += 1 # 移动到下一个图片路径
# 保存修改后的.docx文件
doc.save(imagePath + fr'\动物数独卡片{f:02d}页.docx')
from docx2pdf import convert
# docx 文件另存为PDF文件
inputFile =imagePath + fr'\动物数独卡片{f:02d}页.docx'# 要转换的文件:已存在
outputFile = imagePath + fr'\动物数独卡片{f:02d}页.pdf' # 要生成的文件:不存在
# 先创建 不存在的 文件
f1 = open(outputFile,'w')
f1.close()
# 再转换往PDF中写入内容
convert(inputFile, outputFile)
from docx2pdf import convert
import os
from PyPDF2 import PdfMerger
pdf_lst = [f for f in os.listdir(imagePath) if f.endswith('.pdf')]
pdf_lst = [os.path.join(imagePath, filename) for filename in pdf_lst]
pdf_lst.sort()
file_merger = PdfMerger()
for pdf in pdf_lst:
print(pdf)
file_merger.append(pdf)
file_merger.write(imagePath3+r"\(打印合集)动物数独3.2CM小卡片.pdf")
file_merger.close()
# # print('----------第5步:删除临时文件夹------------')
import shutil
shutil.rmtree(imagePath) #递归删除文件夹,即:删除非空文件夹
print('以下制作1-15关4*4')
import random,time
from win32com.client import constants,gencache
from win32com.client.gencache import EnsureDispatch
from win32com.client import constants # 导入枚举常数模块
import os,time
import docx
from docx import Document
from docx.shared import Pt
from docx.shared import RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
from docxtpl import DocxTemplate
import pandas as pd
from docx2pdf import convert
from docx.shared import RGBColor
from docx import Document
from docx.shared import Cm
from docx.enum.text import WD_ALIGN_PARAGRAPH, WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import nsdecls
from docx.oxml import parse_xml
# 新建一个”装N份word和PDF“的临时文件夹
imagePath=path+r'\零时Word'
os.makedirs(imagePath,exist_ok=True) # 若图片文件夹不存在就创建
# 生成题库
import random
import copy
num=1
# int(input('生成几份\n'))
# 制作"单元格"# 几宫格
hsall=4
# int(input('请输入4或9\n'))
hs=hsall
# kk=int(input('空格数量,输入5,就是50%,就是空一半)\n'))
print('------1、如果正好想生成1空、2空、3空、4空的数字,需要测算百分比的具体数字------')
n=hsall
g=n*n
a=[]
for i in range(1,101):
# 因为有100,所以三位数
print(f'{n}宫格,难度{i:03d},抽取{i:03d}%:实际有{int(g*i/100):03d}空,已有图案{g-int(g*i/100):03d}')
a.append(f'{n}宫格,难度{i:03d},抽取{i:03d}%:实际有{int(g*i/100):03d}空,已有图案{g-int(g*i/100):03d}')
# print(a)
# print(len(a))
# 用冒号分割,如果0空,加入,
# 创建一个空列表用于存储匹配的元素
b = []
# 遍历原始列表
for element in a:
# 如果找到匹配的元素,以":"为分隔符将字符串分割成两部分
parts = element.split(":")
# print(parts)
# # 提取第一部分中包含的数字信息
info = parts[1]
b.append(info)
# 对列表b进行排序,并去除重复项
b = list(set(b))
b.sort(reverse=False)
print(b)
f=[]
for d in range(len(b)):
for c in a:
# print(c)
# 读取一个就中断
if c[-15:]==b[d]:
f.append(c)
break
f.pop(0)
# 删除['4宫格,难度01,抽取1%:实际有00空,已有图案16',
f.pop(-1)
# 删除'4宫格,难度100,抽取100%:实际有16空,已有图案00'
print(f)
# ['4宫格,难度007,抽取007%:实际有001空,已有图案015', '4宫格,难度013,抽取013%:实际有002空,已有图案014', '4宫格,难度019,抽取019%:实际有003空,已有图案013', '4宫格,难度025,抽取025%:实际有004空
# ,已有图案012', '4宫格,难度032,抽取032%:实际有005空,已有图案011', '4宫格,难度038,抽取038%:实际有006空,已有图案010', '4宫格,难度044,抽取044%:实际有007空,已有图案009', '4宫格,难度050,抽取050%:实际有008空,已有图案008', '4宫格,难度057,抽取057%:实际有009空,已有图案007', '4宫格,难度063,抽取063%:实际有010空,已有图案006', '4宫格,难度069,抽取069%:实际有011空,已有图案005', '4宫格,
# 难度075,抽取075%:实际有012空,已有图案004', '4宫格,难度082,抽取082%:实际有013空,已有图案003', '4宫格,难度088,抽取088%:实际有014空,已有图案002', '4宫格,难度094,抽取094%:实际有015空,已有图案
# 001']
print(len(f))
# 15
# 难度有15关
# 提取百分数
g=[]
w=[]
for p in f:
g.append(int(p[12:15])) # 提取第6-7个数字=百分比数字
w.append(int(p[20:23])) # 提取空格数量
print(g)
# [7, 13, 19, 25, 32, 38, 44, 50, 57, 63, 69, 75, 82, 88, 94]
print(len(g))
# 15关
print(w)
# [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]
print(len(w))
# 15
for kk in range(len(g)):
# 因为有3-9的不同word模板,其中3-4模板一页生成9套,5-9模板一页生成6套,这里直接生成边长
ll=['4','9'] # 如果输入345
mm=['21','32']# 3对应的套数是1*2套
nn=['24','24']# 3对应的写入单元格的数字大小36磅
for r in range(len(ll)):
if hsall ==int(ll[r]):
# 底边几套.底边看有2份
db=int(mm[r][0])
# int(input('底边几套? 3\n'))
# 侧边几套 侧边看也是2份
print(db )
cb=int(mm[r][1])
# int(input('侧边几套? 2\n'))
print(cb)
size=int(nn[r])
print(size) # 写入单元格数字的大小(撑满格子)
path=r'C:\Users\jg2yXRZ\OneDrive\桌面\动物数独'
# 新建一个”装N份word和PDF“的临时文件夹
imagePath=path+r'\\零时Word'
if not os.path.exists(imagePath): # 判断存放图片的文件夹是否存在
os.makedirs(imagePath) # 若图片文件夹不存在就创建
# 计算不同模板中的单元格坐标,放在bg里
# 棋盘格子数量,
# 如果正方形:底边2*侧边2,就是3*3宫格 2*2=4套,底边边格子数量就是3*2+1=7,侧边格子数量就是3*2+1=7,
# 如果长方形:底边3*侧边2,就是3*3宫格,3*2=6套 底边格子数量就是3*3+2=11,侧边格子数量就是3*2+1=7,
# if db==cb:
db_size = hs*db+db-1
cb_size= hs*cb+cb-1
print('{}宫格排列底{}侧{}共{}套,底边格子数{}'.format(hs,db,cb,db*cb,db_size ))
print('{}宫格排列底{}侧{}共{}套,侧边格子数{}'.format(hs,db,cb,db*cb,cb_size ))
# 确定每个宫格的左上角坐标 00 04 40 44
bgszm=[]
for a in range(0,cb_size,hs+1): # 0-11每隔4,写一个坐标 侧边y
for b in range(0,db_size,hs+1): # 0-11每隔4,写一个坐标 侧边x
bgszm.append('{}{}'.format('%02d'%a,'%02d'%b))
print(bgszm)
# 3宫格排列底3侧2共6套,底边格子数11
# 3宫格排列底3侧2共6套,侧边格子数7
# ['0000', '0004', '0008', '0400', '0404', '0408']
# 转为元祖
start_coordinates = [(int(s[0:2]), int(s[2:4])) for s in bgszm]
cell_coordinates = []
# 推算每个起始格子后面的单元格数字
for start_coord in start_coordinates:
i, j = start_coord
subgrid_coordinates = []
for x in range(hs):
for y in range(hs):
subgrid_coordinates.append((i + x, j + y))
cell_coordinates.append(subgrid_coordinates)
# 打印结果(元祖样式)
bg=[]
for coordinates in cell_coordinates:
# print(coordinates) # [(4, 8), (4, 9), (4, 10), (5, 8), (5, 9), (5, 10), (6, 8), (6, 9), (6, 10)]
for c in coordinates:
print(c) # 元组 (1, 2) 样式
s = ''.join(str(num).zfill(2) for num in c) # zfill将元组 (1, 2) 转换为字符串 '0102' 特别是(5,10)这种必须转成2个数字0510
print(str(s)) # '12'
bg.append(s) # '0102'
print(bg)
# 生成PDf
P=[]
for z in range(num):
P.clear()
# 制作4份数据
for j in range(db*cb): # 3宫格,4*3=12套
# ————————————————
# 版权声明:本文为CSDN博主「Vaeeeeeee」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
# 原文链接:https://blog.csdn.net/m0_46366547/article/details/131334720
def generate_sudoku_board():
# 创建一个9x9的二维列表,表示数独棋盘
board = [[0] * hs for _ in range(hs)]
# 递归函数,用于填充数独棋盘的每个单元格
def filling_board(row, col):
# 检查是否填充完成整个数独棋盘
if row == hs:
return True
# 计算下一个单元格的行和列索引
next_row = row if col < hs-1 else row + 1
next_col = (col + 1) % hs
import math
r = int(math.sqrt(hs))
print(r)
# 获取当前单元格在小九宫格中的索引
box_row = row // r
box_col = col // r
# 随机生成1到9的数字
numbers = random.sample(range(1, hs+1), hs)
for num in numbers:
# 检查行、列、小九宫格是否已经存在相同的数字
if num not in board[row] and all(board[i][col] != num for i in range(hs)) and all(num != board[i][j] for i in range(box_row*r, box_row*r+r) for j in range(box_col*r, box_col*r+r)):
board[row][col] = num
# 递归填充下一个单元格
if filling_board(next_row, next_col):
return True
# 回溯,将当前单元格重置为0
board[row][col] = 0
return False
# 填充数独棋盘
filling_board(0, 0)
return board
# 这一块是按照等级随机产生空格,数量不稳定,
# def create_board(level): # level数字越大代表游戏难度越大,空白格子越多
# """
# 生成一个随机的数独棋盘,空白格少
# """
# board = generate_sudoku_board()
# board1 = copy.deepcopy(board)
# for i in range(hs*hs):
# row = i // hs
# col = i % hs
# if random.randint(0, hs) < level: # 随机数量
# board1[row][col] = 0 # 格子填充为0
# return (board,board1)
# if hs==9:
# v = create_board(5)[1]
# print(v)
# if hs==4:
# v = create_board(3)[1]
# print(v)
# 定量出现空白格子
def create_board(): # level数字越大代表游戏难度越大
"""
生成一个随机的数独棋盘,空白格少
"""
board = generate_sudoku_board()
board1 = copy.deepcopy(board)
ggg=int(g[kk])
blanks = random.sample(range(hs*hs), int(float(hs*hs*ggg)/100)) # 16*97/100=15.52是浮点数,然后再转成整数
for i in blanks:
row = i // hs
col = i % hs
board[row][col] = 0
# if random.randint(0, hs) < level:
# board1[row][col] = 0
return board
v = create_board()
# 数字越小,空格少
# 数字大,空格多
# 这里无法控制空格的数量
# 提取每个元素
for a1 in v: # 第一次读取,[a,b][c,d][e,f]的内容-列表
for a2 in a1: # 第二次读取,[a,b,c,d,e,f]的内容-元素
if a2==0: # 如果某个元素==0,就替换成空
P.append('')
else: # 如果某个元素非0,就写入本身的数字
P.append(a2)
print(P)
print(len(P))
Q=P
doc = Document(path+r'\动物数独(四宫格横板).docx')
# 获取第一个表格,写难度用的
table = doc.tables[0]
for b1 in range(0,2):
# 在'00'单元格中插入文本
cell_00 = table.cell(0, b1)
cell_00_paragraph = cell_00.paragraphs[0]
cell_00_paragraph.text =f"第 {kk+1} 关"
cell_00_paragraph.style.font.bold = True
cell_00_paragraph.style.font.size = Pt(24)
cell_00_paragraph.style.font.name = "黑体"
cell_00_paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
#
table = doc.tables[1] # 表0,表2 写标题用的
# 标题写入3、5单元格
for t in range(0,len(bg)): # 0-5是最下面一行,用来写卡片数字
pp=int(bg[t][0:2]) #
qq=int(bg[t][2:4])
k=str(Q[t]) # 提取list图案列表里面每个图形 t=索引数字
print(pp,qq,k)
# 图案符号的字体、大小参数
run=table.cell(pp,qq).paragraphs[0].add_run(k) # 在单元格0,0(第1行第1列)输入第0个图图案
run.font.name = '黑体'#输入时默认华文彩云字体
# run.font.size = Pt(46) #输入字体大小默认30号 换行(一页一份大卡片
run.font.size = Pt(size) #是否加粗
# run.font.color.rgb = RGBColor(150,150,150) #数字小,颜色深0-255
run.font.color.rgb = RGBColor(50,50,50) #数字小,颜色深0-255
run.bold=True
# paragraph.paragraph_format.line_spacing = Pt(180) #数字段间距
r = run._element
r.rPr.rFonts.set(qn('w:eastAsia'), '黑体')#将输入语句中的中文部分字体变为华文行楷
table.cell(pp,qq).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER#居中
doc.save(imagePath+r'\{}.docx'.format('%02d'%(z+1)))#保存为XX学号的电话号码word
time.sleep(1)
from docx import Document
from docx.shared import Cm
# 读取四张卡通动物的文件名
animal_path = path+r'\02动物图片' # 替换为实际的文件夹路径
# 获取文件夹中所有文件的完整路径
file_paths = [os.path.join(animal_path, file_name) for file_name in os.listdir(animal_path)]
print(file_paths)
# 把数字1替换成01图片
# 打开Word文档
doc = Document(imagePath+r'\{}.docx'.format('%02d'%(z+1)))
# 获取所有表格
tables = doc.tables
# 遍历每个表格
for table in tables:
# 遍历表格的行
for i, row in enumerate(table.rows):
# 遍历行的单元格
for j, cell in enumerate(row.cells):
# 读取单元格的文本值
cell_text = cell.text
for x in range(0,4):
# 判断单元格的值是否为1
if cell_text == f'{x+1}':
# 删除原来的文本
cell.text = ''
# 插入图片
run = cell.paragraphs[0].add_run()
run.add_picture(file_paths[x], width=Cm(3), height=Cm(3))
# 设置图片对齐方式为居中
run.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
# 设置单元格的水平和垂直对齐方式为居中
cell.vertical_alignment = WD_ALIGN_PARAGRAPH.CENTER
cell.paragraphs[0].alignment = WD_ALIGN_PARAGRAPH.CENTER
# 保存修改后的文档
doc.save(imagePath+r'\{}.docx'.format('%02d'%(z+1)))
time.sleep(2)
# # 关闭Word文档
# doc.close()
time.sleep(2)
from docx2pdf import convert
# docx 文件另存为PDF文件
inputFile = imagePath+"\{}.docx".format('%02d'%(z+1))# 要转换的文件:已存在
outputFile = imagePath+"\{}.pdf".format('%02d'%(z+1)) # 要生成的文件:不存在
# 先创建 不存在的 文件
f1 = open(outputFile, 'w')
f1.close()
# 再转换往PDF中写入内容
convert(inputFile, outputFile)
print('----------第4步:把都有PDF合并为一个打印用PDF------------')
# 多个PDF合并(CSDN博主「红色小小螃蟹」,https://blog.csdn.net/yangcunbiao/article/details/125248205)
import os
from PyPDF2 import PdfMerger
target_path = imagePath
pdf_lst = [f for f in os.listdir(target_path) if f.endswith('.pdf')]
pdf_lst = [os.path.join(target_path, filename) for filename in pdf_lst]
pdf_lst.sort()
file_merger = PdfMerger()
for pdf in pdf_lst:
print(pdf)
file_merger.append(pdf)
# vv=w[kk]
file_merger.write(imagePath2+fr"\(打印合集) 动物拼图{hs}宫格 难度{kk+1:02d} 空{int(w[kk]):03d}格({db}乘{cb}等于{num}份{db*cb}张).pdf")
file_merger.close()
# doc.Close()
# # print('----------第5步:删除临时文件夹------------')
import shutil
shutil.rmtree(imagePath) #递归删除文件夹,即:删除非空文件夹
time.sleep(3) # 防止转换时报错,预留生成时间
# 最后把PDF合并
import os
from PyPDF2 import PdfMerger, PdfFileReader
# 创建一个PdfMerger对象
merger = PdfMerger()
# 遍历文件夹中的所有PDF文件
folder_path = imagePath2
for filename in os.listdir(folder_path):
if filename.endswith('.pdf'):
# 打开PDF文件
pdf_path = os.path.join(folder_path, filename)
pdf_file = open(pdf_path, 'rb')
pdf_reader = PdfFileReader(pdf_file)
# 将PDF文件添加到合并器中
merger.append(pdf_reader)
# 关闭当前打开的PDF文件
pdf_file.close()
# 保存合并后的PDF文件
output_path = imagePath3+fr"\动物数独{hs}宫格(空格1-{hs*hs-1}).pdf"
merger.write(output_path)
merger.close()
print("PDF文件合并完成!")
print('----------第8步:把关卡pdf和图卡pdf合并在一起------------')
# 最后把PDF合并
import os
from PyPDF2 import PdfMerger, PdfFileReader
# 创建一个PdfMerger对象
merger = PdfMerger()
# 遍历文件夹中的所有PDF文件
folder_path = path
for filename in os.listdir(imagePath3):
if filename.endswith('.pdf'):
# 打开PDF文件z
pdf_path = os.path.join(imagePath3, filename)
pdf_file = open(pdf_path, 'rb')
pdf_reader = PdfFileReader(pdf_file)
# 将PDF文件添加到合并器中
merger.append(pdf_reader)
# 关闭当前打开的PDF文件
pdf_file.close()
# 保存合并后的PDF文件
output_path = path+fr"\动物数独{hs}宫格(空格1-{len(w)}({len(w)}关卡图和{hs*hs}大图卡).pdf"
merger.write(output_path)
merger.close()
print("PDF文件合并完成!")
import shutil
shutil.rmtree(imagePath3) #递归删除文件夹,即:删除非空文件夹
import shutil
shutil.rmtree(imagePath2) #递归删除文件夹,即:删除非空文件夹
























 1200
1200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











