







 - - 概述 - - 聚类分析最简单、最基本的版本是划分,它把对象组织成多个互斥的组或簇。为了使得问题说明简洁,我们假定簇的个数作为背景知识给定。这个参数是划分方法的起点。 形式地,给定 n 个数据对象的数据集 D,以及要生成的簇个数 k,划分方法把数据对象组织成 k ( k <= n )个分区,其中每个分区代表一个簇。这些簇的形成旨在优化一个客观划分准则,如基于距离的相异性函数
- - 概述 - - 聚类分析最简单、最基本的版本是划分,它把对象组织成多个互斥的组或簇。为了使得问题说明简洁,我们假定簇的个数作为背景知识给定。这个参数是划分方法的起点。 形式地,给定 n 个数据对象的数据集 D,以及要生成的簇个数 k,划分方法把数据对象组织成 k ( k <= n )个分区,其中每个分区代表一个簇。这些簇的形成旨在优化一个客观划分准则,如基于距离的相异性函数
- - 概述 - -
聚类分析最简单、最基本的版本是划分,它把对象组织成多个互斥的组或簇。为了使得问题说明简洁,我们假定簇的个数作为背景知识给定。这个参数是划分方法的起点。
形式地,给定 n 个数据对象的数据集 D,以及要生成的簇个数 k,划分方法把数据对象组织成 k ( k <= n )个分区,其中每个分区代表一个簇。这些簇的形成旨在优化一个客观划分准则,如基于距离的相异性函数,使得根据数据集的属性,在同一个簇中的对象是“相似的”,而不同的簇中的对象是“相异的”。
1、k-均值:一种基于形心的技术
1.1、k-均值算法简介
假设数据集 D 包含 n 个欧式空间中的对象。划分方法把 D 中的对象分配到 k 个簇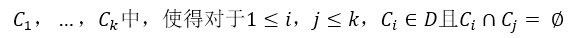
基于形心的划分技术使用簇Ci的形心代表该簇。从概念上讲,簇的形心是它的中心点。形心可以用多种方法定义,例如用分配给该簇的对象(或点)的均值或中心点定义。对象p∈Ci 与该簇的代表ci之差用dist(p, ci)度量,其中dist(x, y)是两个点 x 和 y 之间的欧式距离。簇 Ci 的质量可以用簇内变差度量,它是 Ci 中所有对象和形心ci之间的误差的平方和,定义为:
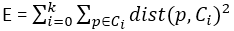
其中,E是数据集中所有对象的误差的平方和;p是空间中的点,表示给定的对象;ci是簇Ci的形心(p和ci都是多维的)。换言之,对于每个簇中的每个对象,求对象到簇中心距离的平方,然后求和。这个目标函数试图使生成的结果簇尽可能紧凑和独立。
优化簇内变差是一项具有挑战性的计算任务。在最坏情况下,我们必须枚举大量可能的划分(是簇数的指数),并检查簇内变差值。业已证明,在一般的欧式空间中,即便对于两个簇(即 k= 2),该问题也是NP-hard(注释1)的。此外,即便在二位欧式空间中,对于一般的簇个数k,该问题也是NP-hard的。如果簇个数k和空间维度d固定,则该问题可以在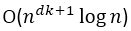
1.2、k-均值算法
k-均值算法把簇的形心定义为簇内点的均值。它的处理流程如下。首先,在D中随机地选择k个对象,每个对象代表一个簇的初始均值或中心。对剩下的每个对象,根据其与各个簇中心的欧式距离,将它分配到最相似的簇。然后,k-均值算法迭代地改善簇内变差。对于每个簇,它使用上次迭代分配到该簇的对象,计算心的均值。然后,使用更新后的均值作为新的簇的中心,重新分配所有的对象。迭代继续,指导分配稳定,即本轮形成的簇与前一轮形成的簇相同。k-均值算法过程概括如下:

1.3、k-均值算法分析
不能保证k-均值算法收敛于全局最优解,并且它常常终止于一个局部最优解。结果可能依赖于初始簇中心的随机选择。实践中,为了得到好的结果,通常以不同的初始簇中心,多次运行k-均值算法。
k-均值算法的复杂度是O(ktmn),其中n是对象总数,k是簇数,t是迭代次数,m是维数。通常,k远小于n并且t远小于n。空间复杂度:O((m+K)n),其中,K为簇的数目,n为记录数,m为维数。因此,对于处理大数据集,该算法是相对可伸缩的和有效的。
k-均值算法有一些变种。他们可能在初始k个均值的选择、相异度的计算、簇均值的计算策略上有所不同。仅当簇的均值有定义时才能使用k-均值算法。在某些应用中,当涉及具有标称属性的数据时,均值可能无定义。k-众数(k-modes)算法是k-均值算法的一个变体,它扩展了k-均值算法,用簇对象的众数取代簇对象的均值。它采用新的相异性度量来处理标称对象,采用基于频率的方法来更新簇的众数。可以混合k-均值和k-众数算法,对混合了数值和标称值得数据进行聚类。
要求用户事先给出簇数k是k-均值算法的一个缺点。然而,针对如何克服这一缺点已经有一些研究,如提供k值的近似范围,然后使用分析技术,通过比较由不同k得到的聚类结果,确定最佳的k值。k-均值算法不适合于发现非凸形状的簇,或大小差别很大的簇。此外,它对噪声和离群点敏感,因为少量的这类数据能够对均值产生极大的影响。
如何提高k-均值算法的可伸缩性:一种是k-均值算法在大型数据集上更有效的方法是在聚类时使用合适规模的样本。另一种是使用过滤方法,使用空间层次数据索引节省计算均值的开销。第三种方法是利用微聚类的思想,首先把邻近的对象划分到一些”微簇”(microcluster)中,然后对这些微簇使用k-均值方法进行聚类。
1.4 k-means算法的实现
使用的Python是2.6.6版本的。附加的库有Numpy和Matplotlib。
文件:kmeans.py
#-*- coding: UTF-8 -*-
#################################################
# filename:kmeans.py
# kmeans: k-means 聚类算法实现
# 该段代码来自博客:机器学习算法与Python实践之(五)k均值聚类(k-means)
# 博客地址:http://blog.csdn.net/zouxy09/article/details/17589329
#################################################
from numpy import *
import matplotlib.pyplot as plt
# calculate Euclidean distance
def euclDistance(vector1, vector2):
return sqrt(sum(power(vector2 - vector1, 2)))
# init centroids with random samples
def initCentroids(dataSet, k):
numSamples, dim = dataSet.shape
centroids = zeros((k, dim))
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1071
1071











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









