










《数学之美 ⋅ 第二版》第四章
现在中文分词是一个已经解决的问题,提升的空间微乎其微。不值得再去花很大的精力去做研究
1、中文分词方法的演变
(a.)北航的梁南元教授提出的查字典类似的方法,但是对于稍微复杂的句子就无能为力;额;
(b.)20世纪80年代哈工大的王晓龙博士将查字典的方法理论化,发展成最少词数的分词理论,但是没有解决词语的二义性问题;
(c.)1990年前后,清华大学的郭进博士运用统计语言模型成功解决了分词的二义性问题。
(d.)清华大学孙茂松教授解决了在没有词典时的分词问题;
(e.)香港科技大学吴德凯教授是较早将中文分词用于英文词组的分隔,并且将英文词组和中文词组在机器翻译时对应起来。
2、基于统计语言模型的分词方法
假定一个句子
S
可以有几种分词方法,为了简单起见,假定有以下三种:
B1,B2,B3,...,Bm
C1,C2,C3,...,Cn
其中,
A1,A2,...,B1,B2,...,C1,C2,...
等都是汉语的词,上述各种分词结果可能产生数量不同的词串,因此用了
k,m,n
三个不同的下标表示这个句子采用不同分词结果时词的数目。那么最好的分词方法应该保证分词后这个句子出现的概率最大。也就是说,如果
A1,A2,A3,...,Ak
是最好的的分词方法,那么其概率满足:
P(A1,A2,A3,...,Ak)>P(B1,B2,B3,...,Bm)
并且
P(A1,A2,A3,...,Ak)>P(C1,C2,C3,...,Cn)
因此,只要利用统计语言模型计算出每种分词后句子出现的概率,并找出其中概率最大的,就能找到最好的分词方法。
当然,这里面有一个实现的技巧。如果,穷举所有可能的分词方法并计算出每种可能性下的句子的概率,那么计算量是相当大的。因此,可以把它看成一个动态规划(Dynamic Programming)的问题,并利用 维特比(Viterbi) 算法
[1]
快速地找出最佳分词。上述过程可以用下图来描述:
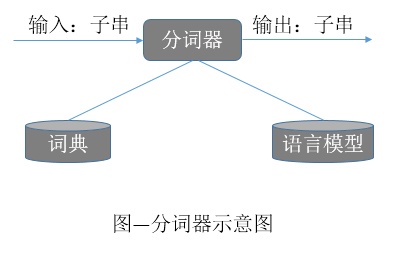
注释:
[1]维特比算法
暂缺!稍后补上!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









