







如有疑问可关注公众号: 【寻沂】欢迎交流
文章目录
在这篇文章中主要介绍了一下Alibaba的论文《Deep Interest Network for Click-Through Rate Prediction》
文章中心思想的部分内容主要包括三个部分:
-
Attention在CTR预估任务中的使用
-
自适应的正则化方法
-
Dice激活函数
在这篇文章中,我们主要从以下几个方面综合的概括一下《Deep Interest Network for Click-Through Rate Prediction》
这篇论文的中心思想以及这篇论文的启发。
在论文的第一小节中,我们主要介绍了Deep Interest Network引入Attention的动机和基本思想,
以及引入Attention之后神经网络的基本结构。
在第二节中,总结了自适应正则化和Dice激活函数在神经网络模型训练上的优化。
在第三节中,简要的介绍了一下Alibaba在DIN上的实验。
最后我们分析了一下阿里公开的Deep Interest Network的实现代码。
1. DIN的基本思想
1.1 模型结构
在了解Deep Interest Network的基本思想之前,我们首先需要明确Deep Interest Network
需要处理的问题是排序问题,以及排序系统在推荐系统中所处的阶段。
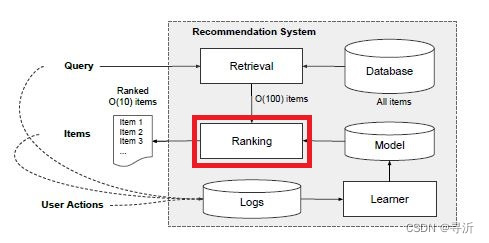
在图1中给出了一个搜索系统的架构和搜索类似的,推荐过程和搜索过程的区别
在于推荐系统的召回阶段和排序阶段的输入是用户画像和场景信息,搜索系统输入
的是用户自主输入的Query信息。
在推荐系统中召回和排序阶段分别完成不同的工作:
Matching/Retrieval: 召回阶段根据对应的行为输入从大规模(百万甚至前往量级)的候选集中挑选出成百上千个
用户可能感兴趣的物品,然后送入到排序阶段。
Ranking: 排序阶段的输入是用户行为信息和召回阶段的结果,然后给召回阶段的结果准确的排序得分。
Deep Interest Network所需要解决的问题在图1中红框标识的Ranking阶段。
不同阶段的数据情况和目的(所要解决的问题)决定了我们能够使用什么样的方法。
排序阶段面临的候选集个数比较小,需要对candidate有准确的区分并且尽可能兼顾排序结果的多样性,但是
对于同一个用户而言,能够对于同类目的物品具有相近的排序得分的可能性较大,因为相近的物品具有相同的特征。
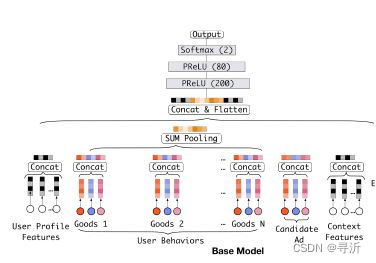
以Base Model的Embedding & MLP的网络结构为例,模型输入通过将用户特征和物品特征concat & flatten输入到
MLP的模型结构中。同一用户具有相同的用户向量的输入,那么模型对同类型的物品的得分可能具有相近的得分。
可是在实际情况当中用户可能具备多个兴趣并且需要模型能够捕获用户的多样兴趣,对多种不同品类的物品都能
给出较为合适的排序得分。
在Deep Interest Network中,举了一个年轻妈妈的例子:
例如一个年轻的妈妈最近购买了羊毛大衣、T恤、耳环、手提包、皮革手提包 以及儿童外套。
这些数据隐含了用户的行为兴趣。如果当这个年轻的妈妈访问推荐系统的时候,可能会给她
推荐一个新的手提包。可是这个推荐结果只是契合了这个年轻母亲的一部分兴趣。
为了使得模型能够捕获用户多样的兴趣,在模型结构中引入了Attention机制。
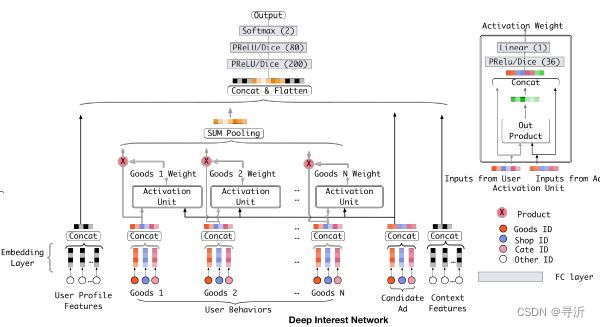
在DIN中为了捕获用户的不同兴趣,对Embedding & MLP的结构进行了一些修改。在embedding层
生成用户向量的时候,针对每一个candidate采用局部激活函数生成用户不同行为的权重,然后采用sum
pooling生成用户的行为向量。
1.2 特征输入
在Alibaba的Deep Interest Network中输入的特征如表1所示。在排序模型中主要的输入为分组或者分类
信息包括: 用户画像特征(User Profile Features),用户行为特征(User Behavior Features), 广告特征(Ad Features)
以及场景特征(Context Features)。
这些不同特征通过one-hot或者multi-hot的方式的编码方式编码成为二进制的向量,作为模型的输入,如图4所示。
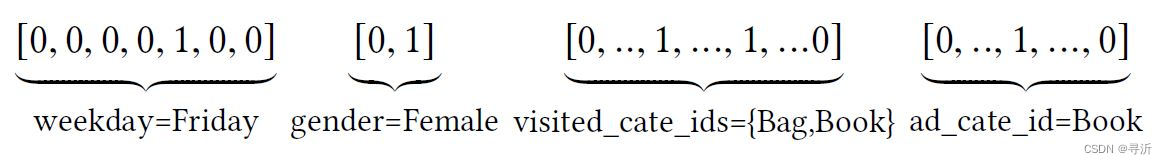
1.3 局部激活单元
Deep Interest Network本质上是在Base Model上的优化。Base Model是一个常见的DNN模型,主要分为4个部分:
Embedding层: 对高维的二进制输入向量,embedding层将这些向量转成低维的稠密向量表示。
Pooling & Concat层: 因为不同的用户具有不同的行为,所以在multi-hot的向量里面值为1的位置数目是不同的。例如
一个用户有3次购买行为和5次购买行为的multi-hot为1的索引位置分别为3个和5个。这个时候不同的用户输入经过
embedding层得到的特征向量维度是不同的。Pooling & Concat层的目的就是为了对物品和用户得到固定长度的向量表示。
在Pooling操作中,常用的操作是sum pooling(对应维度求和)和average pooling(对应维度求均值)
MLP层: MLP层是对Pooling & Concat层给出的向量通过全连接层来捕获特征之间的交叉。
LOSS: 在Base Model中采用负对数似然函数作为损失函数,对损失的计算如下:
L = − 1 N ∑ ( x , y ) ∈ S ( y l o g p ( x ) + ( 1 − y ) l o g ( 1 − p ( x ) ) ) \begin{equation} L = - \frac{1}{N} \sum_{(x,y) \in S} (y\;log\;p(x) + (1-y)\;log\;(1-p(x))) \tag{1.1} \end{equation} L=−N1(x,y)∈S∑(ylogp(x)+(1−y)log(1−p(x)))(1.1)
在Deep Interest Network的动机中认为Pooling & Concat通过简单的pooling操作和concat操作生成
固定长度的向量没有办法有效地捕获到多样的用户兴趣。DIN引入Attention机制做局部激活在对行为
特征进行sum pooling的时候不同行为设置了不同的权重。
假设个定一个用户 A A A那么这个用户的向量表示如公式(1.2)
V U ( A ) = f ( V A , e 1 , e 2 , . . . , e H ) = ∑ j = 1 H a ( e j , V A ) e j = ∑ j = 1 H w j e j \begin{equation} V_U(A) = f(V_A, e_1, e_2,...,e_H) = \sum_{j=1}^H a(e_j, V_A)e_j = \sum_{j=1}^H w_j e_j \tag{1.2} \end{equation} VU(A)=f(VA,e1,e2,...,eH)=j=1∑Ha(ej,VA)ej=j=1∑Hwjej(1.2)
其中:
e 1 , e 2 , . . . , e H {e_1, e_2,...,e_H} e1,e2,...,eH 是用户 U U U 的行为embedding向量列表,用户行为向量维度的大小为 H H H。
V A V_A VA 是候选广告A的向量, V U ( A ) V_U(A) VU(A) 是随着不同的候选广告变化的。
图2中的
a
(
⋅
)
a(\cdot)
a(⋅) 是一个前馈神经网络,DIN将这个神经网络的输出作为用户行为向量激活的权重。
在
a
(
⋅
)
a(\cdot)
a(⋅) 除了将两个向量作为输入之外,模型还将这两个向量计算的结果输入到后续的相关性建模当中,
来引入隐含的额外信息来进行相关性建模。
2. 深度模型的训练技巧
在DIN中介绍了两种模型训练的技巧分别为:Mini-batch Aware Regularization和Data Adaptive Activation Function。
我这里翻译为小批量感知正则化和局部自适应激活,在2.1小节和2.2小节中分别介绍一下这两种方法。
2.1 小批量感知正则化
在DIN中因为类似于物品id这样细粒度特征的引入很容易出现深度模型的过拟合,并且在文中
给出了图像证明,模型在经过一轮迭代训练后,训练集上的loss明显下降,测试集上loss和auc开始明显提升。
在传统的机器学习模型训练当中解决过拟合问题常用的方法是正则化。可是在深度模型中,
具有大规模的权重矩阵如果使用传统的正则化方式例如L1正则和L2正则会使得模型训练阶段的计算量大大增加。
以L2正则为例,在深度模型的训练中如果采用随机梯度下降作为优化器,
参数更新的时候只需要更新每一个mini-batch中稀疏特征非0值所对应的参数。
可是如果我们需要在模型训练过程中添加L2正则,
那么对每一个mini-batch的参数需要在全局参数上计算L2的模。
这样的计算量级在生产环境是没有办法被接受的。
在DIN的模型训练中引入了mini-batch感知正则的概念,只需要计算每个mini-batch稀疏特征L2
的模型,来减小计算量。
在深度网络的参数中实际上Embedding生成的特征向量占据了大部分参数。在一下描述中,我们使用
W
∈
R
D
×
K
W \in \mathbb{R}^{D \times K}
W∈RD×K表示特征嵌入矩阵,其中D是嵌入后特征向量的维度,
K表示输入到神经网络中特征的维度。这种情况下如果我们只是在样本上计算L2正则,那么计算公式如公式2.1
L 2 ( W ) = ∣ ∣ W ∣ ∣ 2 2 = ∑ j = 1 K ∣ ∣ w j ∣ ∣ 2 2 = ∑ ( x , y ) ∈ S ∑ j = 1 K I ( x j ≠ 0 ) n j ∣ ∣ w j ∣ ∣ 2 2 \begin{equation} L_2(W) = ||W||^2_2 = \sum_{j=1}^K ||w_j||^2_2 = \sum_{(x,y)\in S} \sum_{j=1}^K \frac{I(x_j\ne0)}{n_j}||w_j||^2_2 \tag{2.1} \end{equation} L2(W)=∣∣W∣∣22=j=1∑K∣∣wj∣∣22=(x,y)∈S∑j=1∑KnjI(xj=0)∣∣wj∣∣22(2.1)
其中
w
j
∈
R
D
w_j\in \mathbb{R}^D
wj∈RD 是特征嵌入矩阵中的第j条向量,
I
(
x
j
≠
0
)
I(x_j\ne0)
I(xj=0)表示如果样本
x
x
x是否有特征
j
j
j,
其中
n
j
n_j
nj表示特征
j
j
j 在所有的样本中出现的次数。上面的这个方程可以转化为下面的这种形式:
L 2 ( W ) = ∑ K j = 1 ∑ B m = 1 ∑ ( x , y ) ∈ B m I ( x j ≠ 0 ) n j ∣ ∣ w j ∣ ∣ 2 2 \begin{equation} L_2(W) = \sum_{K}^{j=1}\sum_{B}^{m=1} \sum_{(x,y)\in \mathcal{B_{\mathbb{m}}}} \frac{I(x_j \ne 0)}{n_j} ||w_j||^2_2 \tag{2.2} \end{equation} L2(W)=K∑j=1B∑m=1(x,y)∈Bm∑njI(xj=0)∣∣wj∣∣22(2.2)
其中
B
B
B 表示mini-batch的大小,
B
m
\mathcal{B_{\mathrm{m}}}
Bm 表示第
m
m
m 个mini-batch。在上面的公式中,我们让
α
m
j
=
m
a
x
(
x
,
y
)
∈
B
m
I
(
x
j
≠
0
)
\alpha_{mj} = max_{(x,y)\in \mathcal{B_{\mathbb{m}}}}I(x_j\ne0)
αmj=max(x,y)∈BmI(xj=0) 表示在mini-batch
B
m
\mathcal{B_{\mathrm{m}}}
Bm中
是否存在特征
j
j
j。那么上面的方程可以大致简化为如下所示:
L 2 ( W ) ≈ ∑ j = 1 K ∑ m = 1 B α m j n j ∣ ∣ w j ∣ ∣ 2 2 \begin{equation} L_2(W) \approx \sum_{j=1}^K \sum_{m=1}^B \frac{\alpha_{mj}}{n_j}||w_j||^2_2 \tag{2.3} \end{equation} L2(W)≈j=1∑Km=1∑Bnjαmj∣∣wj∣∣22(2.3)
在这种情况下,我们推导出一个小批量感知的L2正则。这个时候对于第 m m m个mini-batch,对特征 j j j的权重更新公式如下。
w j ← w j − η [ 1 ∣ B m ∣ ∑ ( x , y ) ∈ B m ∂ L ( p ( x ) , y ) ∂ w j + λ α m j n j w j ] \begin{equation} w_j \leftarrow w_j - \eta[\frac{1}{|\mathcal{B_\mathbb{m}}|} \sum_{(x,y)\in \mathcal{B_{\mathbb{m}}}}{\frac{\partial L(p(x),y)}{\partial w_j} + \lambda \frac{\alpha_{mj}}{n_j}w_j}] \tag{2.4} \end{equation} wj←wj−η[∣Bm∣1(x,y)∈Bm∑∂wj∂L(p(x),y)+λnjαmjwj](2.4)
在计算公式2.4中只要对第 m m m个mini-batch中出现的特征参数进行正则化。
2.2 局部自适应激活
在alibaba的DIN模型中,基于PReLU对激活函数做了一些改进。
首先,我们来看一下PReLU作为激活函数的描述形式
f ( s ) = { s i f s > 0 α s i f s ≤ 0. = p ( s ) ⋅ s + ( 1 − p ( s ) ) ⋅ α s \begin{equation} f(s)=\left\{ \begin{aligned} s & \,\,\,\,\,\,\,\,\mathbb{if} \,\,\,\,s > 0 \\ \alpha s & \,\,\,\,\,\,\,\,\mathbb{if} \,\,\,\, s\le 0. \end{aligned} = p(s) \cdot s + (1-p(s)) \cdot \alpha s \right. \tag{2.5} \end{equation} f(s)={sαsifs>0ifs≤0.=p(s)⋅s+(1−p(s))⋅αs(2.5)
其中,
s
s
s 是激活函数的一维输入,
p
(
s
)
p(s)
p(s)是一个控制单元用来选择激活函数使用
f
(
s
)
=
s
f(s) = s
f(s)=s和
f
(
s
)
=
α
s
f(s) = \alpha s
f(s)=αs中的哪一个函数段。
在PReLU中 p ( s ) p(s) p(s)作为控制函数有一个硬转折点,在DIN中提出了一个新的激活函数Dice对控制单元 p ( s ) p(s) p(s)做了一下优化,使得激活函数能够自适应数据情况。Dice激活函数的具体描述如下:
f ( s ) = p ( s ) ⋅ s + ( 1 − p ( s ) ) ⋅ α s , p ( s ) = 1 1 + e s − E [ s ] V a r [ s ] + ϵ \begin{equation} f(s)=p(s)\cdot s + (1-p(s))\cdot \alpha s, \,\,\, p(s)=\frac{1}{1+e^{\frac{s-E[s]}{\sqrt{Var[s] + \epsilon}}}} \tag{2.6} \end{equation} f(s)=p(s)⋅s+(1−p(s))⋅αs,p(s)=1+eVar[s]+ϵs−E[s]1(2.6)
这个时候 p ( s ) p(s) p(s)由图5中的左子图的形式变成右边子图的形式。

在Dice函数中的激活函数里面,训练阶段
E
[
s
]
E[s]
E[s]和
V
a
r
[
s
]
Var[s]
Var[s]分别是每个输入的mini-batch的均值和方差。在测试阶段,
E
[
s
]
E[s]
E[s]和
V
a
r
[
s
]
Var[s]
Var[s]通过计算整个数据集上的平均值得到。其中
ϵ
\epsilon
ϵ是一个非常小的常量,
在我们训练的过程中被设置为
1
0
−
8
10^{-8}
10−8
这里我们可以把Dice激活函数看成PReLU的一般形式。
当
E
[
s
]
=
0
E[s]=0
E[s]=0并且
V
a
r
[
s
]
=
0
Var[s]=0
Var[s]=0的时候,这个激活函数退化成为PReLU的形式。
3. DIN上的实验
Alibaba在DIN上进行了公开数据集和Alibaba抽取数据集两部分数据的离线实验,以及线上的AB实验。
接下来,我们细化地讲一下论文中涉及到的实验方法,评估指标,数据处理技巧。
3.1 数据集、参数设置和评估指标
- 数据集和参数设置
-
亚马逊Electronics子数据集: 这个数据集包含了19万的用户,
6万多的物品和801个类别以及168万个样本。
这个数据集具有丰富的行为,每个用户和物品都至少有5条评论。在实验阶段所有的模型都采用SGD作为优化器。优化器初始化的学习速率是1.0,
优化器的衰减速率是0.1。在训练过程中mini-batch的大小设置为32。 -
movieLens数据集: movieLens数据集应该是推荐领域里面非常著名的数据集了。
在这个数据集里面包含了13万的用户,2.7万部电影以及21个类别和2000万条样本数据。
由于movieLens是评分数据。在实验阶段把这个数据集分成二分类的任务。
在原始得分里面,4分和5分的数据标注为正样本,其他的数据标注为负样本。
在预测任务中超过3分的预测为正样本。 -
Alibaba数据集: 在Alibaba数据集抽取了线上系统两周的数据作为训练样本和测试数据。
其中训练数据为2亿条,测试数据为1400万条。
对于所有的深度模型,16组特征向量的维度设置为12维。
MLP网络采用 192 × 200 × 80 × 2 192\times200\times80\times2 192×200×80×2
的网络结构。由于数据量庞大我们将batch size设置为5000,
并且使用Adam作为优化器,起始学习率为0.001耍贱速率为0.9。
- 评估指标
在排序模型的评估中,AUC是常见的评估方式。在Alibaba对模型的评估中,
参考了《Optimized Cost per Click in Taobao Display Advertising》
需要考虑到针对不同的用户和广告展示位置区别进行对待,DIN评估的时候采用了一种基于用户加权的变种AUC,
例如一个从来没有点击过任何广告的用户会使得AUC降低。
基于这一点,提出了一种新的AUC评估矩阵称之为GAUC,具体的计算方式如下:
G A U C = ∑ ( u , p ) w ( u , p ) ∗ A U C ( u , p ) ∑ ( u , p ) w ( u , p ) \begin{equation} GAUC = \frac{\sum_{(u,p)}w_{(u,p)} * AUC(u,p)}{\sum_{(u,p)}w_{(u,p)}} \tag{3.1} \end{equation} GAUC=∑(u,p)w(u,p)∑(u,p)w(u,p)∗AUC(u,p)(3.1)
在公式3.1的计算中首先根据用户和广告位置对测试数据做一下聚合,
然后针对写一个分组(如果这个分组只有正样本或者负样本的话,
就将这个分组移除)计算AUC。最后将所有的auc加权求平均。权重
w
(
u
,
p
)
w(u,p)
w(u,p)和
这个分组中的点击次数或者是占用时间成正比。
在计算得到AUC的情况下,实验中通过RelaImpr计算绝对提升。
R e l a I m p r = ( A U C ( m e a s u r e d m o d e l ) − 0.5 A U C ( b a s e m o d e l ) − 0.5 − 1 ) × 100 % \begin{equation} RelaImpr = (\frac{AUC(measured model)-0.5}{AUC(base model)-0.5}-1) \times 100\% \tag{3.2} \end{equation} RelaImpr=(AUC(basemodel)−0.5AUC(measuredmodel)−0.5−1)×100%(3.2)
3.2 模型对比结果
在实验中分别对比了以下几个模型的效果:
-
LR: LR是传统机器学习模型的老大哥,实验中作为一个weak baseline。
-
BaseModel: BaseModel是DIN的模型的基本结构,是DIN模型的strong baseline。
-
Wide&Deep: Wide&Deep也是排序里面非常出名的模型,分为Wide(LR)和Deep(DNN)两部分。
其中Wide部分用来记忆模型的频次,Deep部分用来学习新的模式。 -
PNN: PNN是BaseModel的加强版本,用于捕获高阶特征。
-
DeepFM: DeepFM采用FM替换了LR中的,减少了人工的特征工程操作。
最后,不同模型在数据集上的对比结果如下图所示:
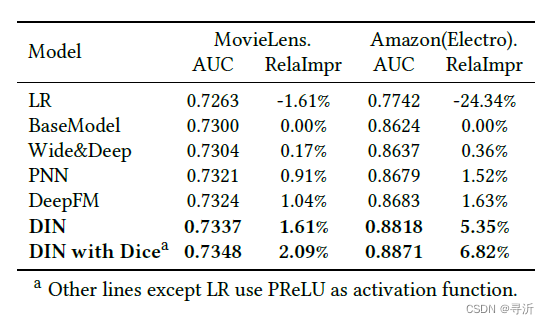
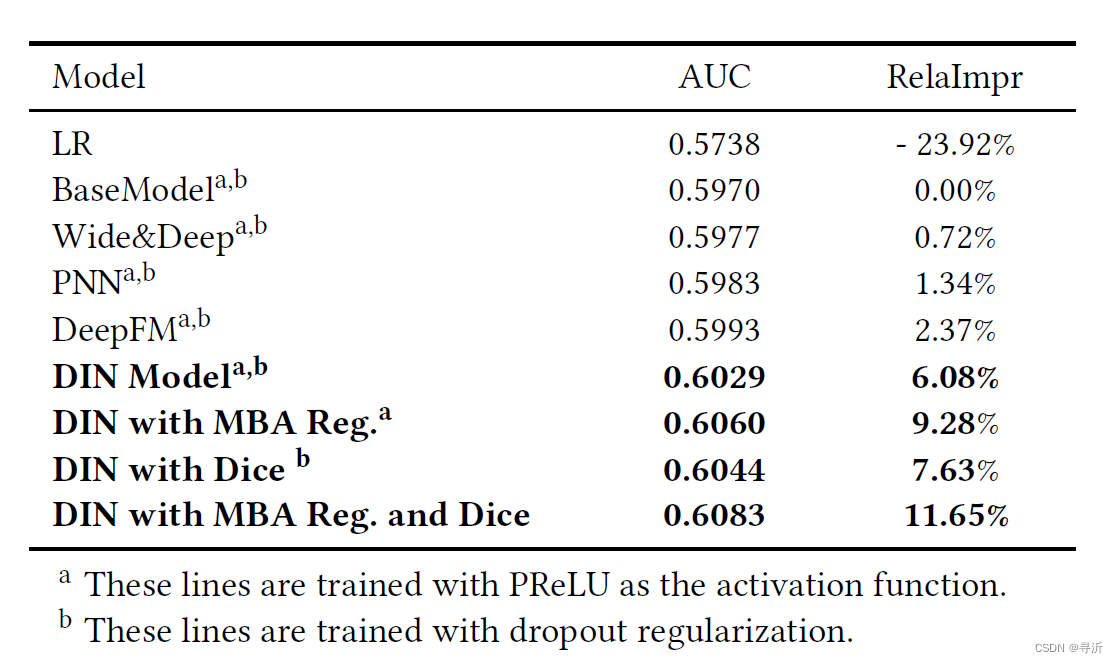
3.3 正则化的表现
在亚马逊和movieLens数据集上没有出现过拟合现象,所以没有使用正则化。
在Alibaba数据集上因为使用了大量的稀疏特征出现了过拟合现象,接下来分别对比了一下几种防止过拟合的方式带来的效果:
-
Dropout: 针对每一个样本随机地丢弃50%的特征id。
-
Filter: 通过视频出现的频次对样本中的物品id做过滤只留下高频出现的物品。在我们的设置中,选取出现频次最多的top 2000万的物品id。
-
Regularization in DiFacto: 大概是一种正则化方法,想要了解细节可以参考《DiFacto: Distributed
factorization machines.》 -
MBA: 就是上述提出的Mini-Batch Aware regularization方法。对于DiFacto和MBA使用的参数 λ \lambda λ都被设置为0.01。
实验中对比几种不同正则化策略的离线评估指标如图7所示。
4. DIN的代码实现
在了解完代码原理之后,我们来看一下DIN源码的实现。这里就看一下Attention
部分的代码。
def attention(queries, keys, keys_length):
'''
queries: [B, H]
keys: [B, T, H]
keys_length: [B]
'''
queries_hidden_units = queries.get_shape().as_list()[-1]
queries = tf.tile(queries, [1, tf.shape(keys)[1]])
queries = tf.reshape(queries, [-1, tf.shape(keys)[1], queries_hidden_units])
din_all = tf.concat([queries, keys, queries-keys, queries*keys], axis=-1)
d_layer_1_all = tf.layers.dense(din_all, 80, activation=tf.nn.sigmoid, name='f1_att', reuse=tf.AUTO_REUSE)
d_layer_2_all = tf.layers.dense(d_layer_1_all, 40, activation=tf.nn.sigmoid, name='f2_att', reuse=tf.AUTO_REUSE)
d_layer_3_all = tf.layers.dense(d_layer_2_all, 1, activation=None, name='f3_att', reuse=tf.AUTO_REUSE)
d_layer_3_all = tf.reshape(d_layer_3_all, [-1, 1, tf.shape(keys)[1]])
outputs = d_layer_3_all
# Mask
key_masks = tf.sequence_mask(keys_length, tf.shape(keys)[1]) # [B, T]
key_masks = tf.expand_dims(key_masks, 1) # [B, 1, T]
paddings = tf.ones_like(outputs) * (-2 ** 32 + 1)
outputs = tf.where(key_masks, outputs, paddings) # [B, 1, T]
# Scale
outputs = outputs / (keys.get_shape().as_list()[-1] ** 0.5)
# Activation
outputs = tf.nn.softmax(outputs) # [B, 1, T]
# Weighted sum
outputs = tf.matmul(outputs, keys) # [B, 1, H]
return outputs
方法的入参为:
- queries:表示待查询的candidate ad
其中queries是一个[B,T]的矩阵。
其中,B表示batch size,T表示向量的维度。
- keys:表示用户的行为历史
keys是一个[B,T,H]的矩阵,T表示batch中最大的观影序列长度。
- keys_length:表示用户行为历史的长度,是一个长度为B的向量。
1. queries的转换
通过上面的代码,我们首先来看一下针对queries的操作:
queries_hidden_units = queries.get_shape().as_list()[-1]
queries = tf.tile(queries, [1, tf.shape(keys)[1]])
queries = tf.reshape(queries, [-1, tf.shape(keys)[1], queries_hidden_units])
din_all = tf.concat([queries, keys, queries-keys, queries*keys], axis=-1)
整个上述的代码通过tile操作,复制queries先转换成了一个[T, B, H]的矩阵。
然后对[T, B, H]通过reshape转换成一个[B,T,H]的矩阵。
在完成queries的转换后通过tf.concat()对queries, keys, queries-keys,
queries
×
\times
×key 进行拼接,
拼接后得到的矩阵大小为:[B,T, 4
×
\times
×H]。
这一部分应该就是原始论文里面说的除了使用了queries和keys向量之外,
还是用了out product。
2. 全连接层生成权重
在三个全连接层中,最后输出一个[B,T,1]的矩阵,重新reshape得到[B,1,T]
d_layer_1_all = tf.layers.dense(din_all, 80, activation=tf.nn.sigmoid, name='f1_att', reuse=tf.AUTO_REUSE)
d_layer_2_all = tf.layers.dense(d_layer_1_all, 40, activation=tf.nn.sigmoid, name='f2_att', reuse=tf.AUTO_REUSE)
d_layer_3_all = tf.layers.dense(d_layer_2_all, 1, activation=None, name='f3_att', reuse=tf.AUTO_REUSE)
d_layer_3_all = tf.reshape(d_layer_3_all, [-1, 1, tf.shape(keys)[1]])
outputs = d_layer_3_all
3. mask操作
在mask操作里面,对Attention的paddings做了一下处理。这里Mask做之后输出的值需要为负无穷,最后softmax出来的结果为0。
key_masks = tf.sequence_mask(keys_length, tf.shape(keys)[1]) # [B, T]
key_masks = tf.expand_dims(key_masks, 1) # [B, 1, T]
paddings = tf.ones_like(outputs) * (-2 ** 32 + 1)
outputs = tf.where(key_masks, outputs, paddings) # [B, 1, T]
4. 生成激活值并加权
在attention方法的最后结果,通过进行scale,然后对相应的权重做激活,激活后的权重对Key值做加权求平均。
# Scale
outputs = outputs / (keys.get_shape().as_list()[-1] ** 0.5)
# Activation
outputs = tf.nn.softmax(outputs) # [B, 1, T]
# Weighted sum
outputs = tf.matmul(outputs, keys) # [B, 1, H]
return outputs
5. 总结
合上论文想一下,整个论文最主要值得参考的点大概是Attention在排序中的使用。
除此之外的疑问和收获就是:
-
每个candidate ad生成一个user embedding然后和item
feature生成的embedding做一下concat,这种情况下模型计算的复杂度在随着candidate ads
个数的增大呈线性增长。例如在召回阶段如何使用Attention的方式来捕获多样兴趣? -
Filter和Dropout Feature看来也是用来解决细粒度特征带来的噪声数据常用的数据处理方式。















 971
971











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









