







契机
对于当前预测的item,用户行为列表中每一个item对最终结果的影响程度不同,引入attention来求出用户行为列表中每个item的权重,并将这些item对应的embedding加权求和得到最终的用户行为embedding向量。
模型核心内容
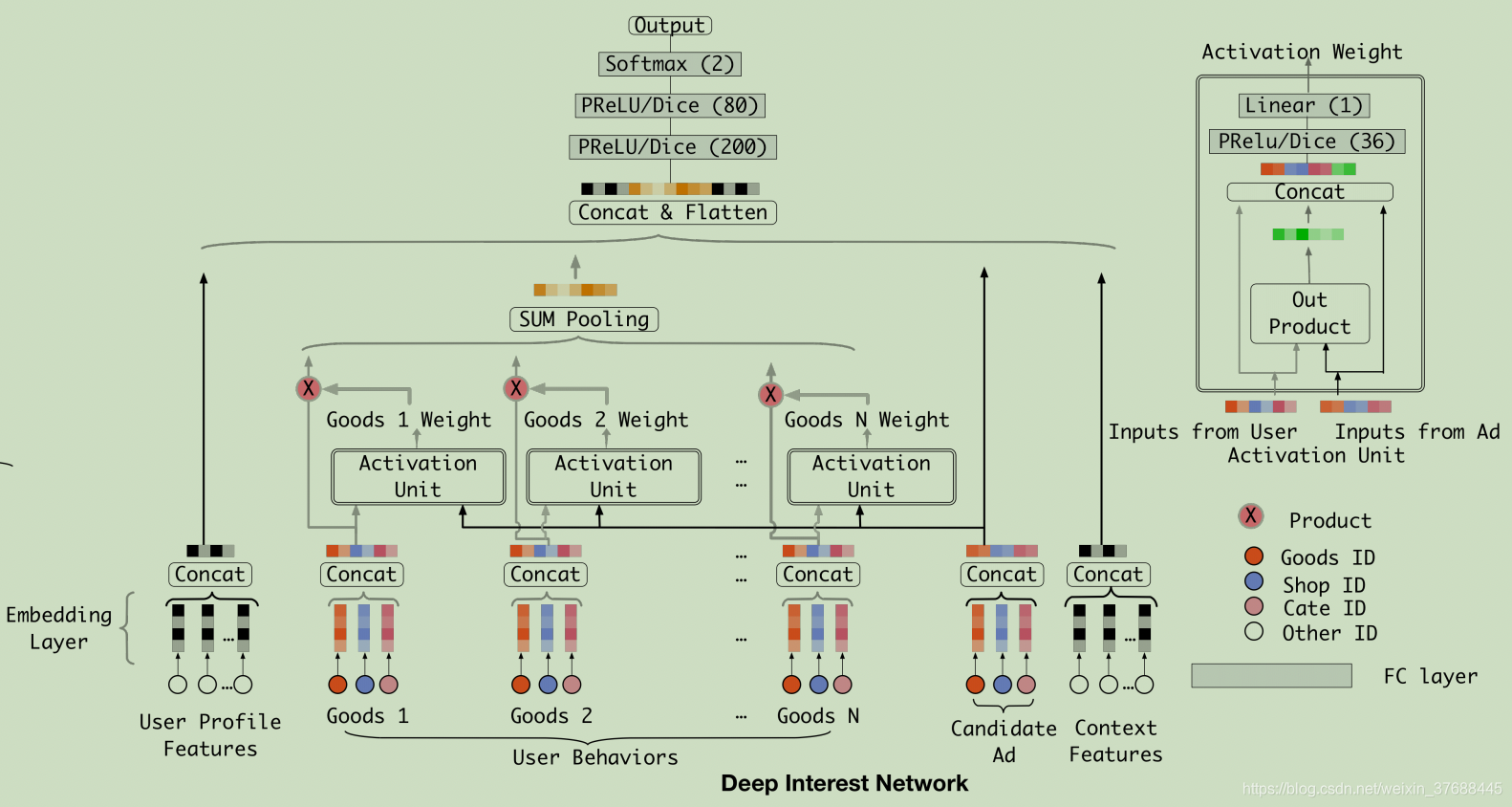
对于用户行为历史中的每个
i
t
e
m
i
item_i
itemi,都与当前预测
i
t
e
m
p
r
e
d
i
c
t
item_{predict}
itempredict进行一次attention交互得到
i
t
e
m
i
item_i
itemi的权重
w
i
w_i
wi。上图中attention的过程是将
i
t
e
m
i
item_i
itemi对应的embedding
e
m
b
i
emb_i
embi和
i
t
e
m
p
r
e
d
i
c
t
item_{predict}
itempredict对应的embedding
e
m
b
p
r
e
d
i
c
t
emb_{predict}
embpredict进行如下计算:
c
o
n
c
a
t
(
e
m
b
i
,
e
m
b
i
∗
e
m
b
p
r
e
d
i
c
t
,
e
m
b
p
r
e
d
i
c
t
)
concat(emb_i, emb_i * emb_{predict}, emb_{predict})
concat(embi,embi∗embpredict,embpredict)
实际使用过程要比上述操作丰富一些:
c o n c a t ( e m b i , e m b i ∗ e m b p r e d i c t , e m b p r e d i c t , e m b p r e d i c t − e m b i ) concat(emb_i, emb_i * emb_{predict}, emb_{predict}, emb_{predict}-emb_i) concat(embi,embi∗embpredict,embpredict,embpredict−embi)
之后经过激活函数以及sigmoid得到 i t e m i item_i itemi的权重 w i w_i wi。最终将加权求和后的embedding向量 ∑ i w i ∗ e m b i \sum_i w_i*emb_i ∑iwi∗embi作为用户行为的最终embedding向量表示。
论文中attention和传统attention不同点在于:传统attention是先算每个key与query的交互得分score,之后送入softmax得到权重,且所有的权值和为1,因而其加权后的embedding更类似于用户兴趣表示;而论文中的attention没有softmax的过程,因而其加权后的embedding更类似于用户行为历史中哪些item和当前item更相关。
attention代码实现
import tensorflow as tf
from tensorflow.keras import layers
from layers.Dice import Dice, dice
class attention(tf.keras.layers.Layer):
def __init__(self, keys_dim):
super(attention, self).__init__()
self.keys_dim = keys_dim
self.fc = tf.keras.Sequential()
self.fc.add(layers.BatchNormalization())
self.fc.add(layers.Dense(36, activation="sigmoid"))
self.fc.add(dice(36))
self.fc.add(layers.Dense(1, activation=None))
# queries代表的是预测item对应的embedding
# keys代表的是user行为历史列表
def call(self, queries, keys, keys_length):
# attention
## 先复制多份queries,使得其能通过矩阵运算一并得出attention权重
queries = tf.tile(tf.expand_dims(queries, 1), [1, tf.shape(keys)[1], 1])
din_all = tf.concat([queries, keys, queries-keys, queries*keys], axis=-1)
outputs = tf.transpose(self.fc(din_all), [0,2,1])
# padding
key_masks = tf.sequence_mask(keys_length, max(keys_length), dtype=tf.bool)
key_masks = tf.expand_dims(key_masks, 1)
paddings = tf.ones_like(outputs) * (-2 ** 32 + 1)
outputs = tf.where(key_masks, outputs, paddings)
# normalization
outputs = outputs / (self.keys_dim ** 0.5)
# sigmoid
outputs = tf.keras.activations.sigmoid(outputs)
# sum Pooling
# outputs为权重列表(1 * keys个数), keys为(keys个数 * emb_dim)
# 两者相乘得到加权后的outputs
outputs = tf.squeeze(tf.matmul(outputs, keys))
print("outputs:" + str(outputs.numpy().shape))
return outputs














 7681
7681











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









