







1,前言
AFM(Attentional Factorization Machines):FM模型的增强变体,这个其实算是NFM的一个延伸,在NFM模型的特征交叉层与池化层中间加了一个注意力网络,对于低阶交互特征,根据其对预测结果的影响程度不同加上了注意力权重,以更加符合实际的推荐场景。
DIN(Deep Interest Network):阿里的知名推荐模型,这个模型是基于业务观察的模型的改进,相较于学术派的深度模型,这个模型更加有业务气息。
大纲如下:
- AFM模型
- 模型解决了什么问题?
- 模型的创新点在哪里?
- 模型是如何如何实现的?(模型结构,数学原理,代码实现)
- DIN模型
- 模型解决了什么问题?
- 模型的创新点在哪里?
- AFM模型是如何如何实现的?(模型结构,数学原理,代码实现)
2,AFM模型
AFM模型是2017年由浙江大学和新加坡国立大学研究员提出的一个模型。
2.1,模型解决了什么问题?
NFM中,不同特征域的特征embedding向量经过特征交叉池化层的交叉,将各个交叉特征向量进行“加和”,然后后面跟一个DNN网络。这里的加和池化,相当于“一视同仁”的对待所有交叉特征,没有考虑不同特征对结果的影响程度,作者认为,由于不是所有的交互特征都能对最后的预测起作用,因此这种一视同仁的加和池化,可能会影响最后的预测效果。
AFM模型是为了解决这个问题而提出来的。
2.2,模型的创新点在哪里?
AFM模型与NFM模型结构非常相似,但是在NFM的基础上,引入了注意力机制,来学习不同交叉特征对最终结果的不同影响程度。从而使得模型更加符合真实的业务场景。
2.3,AFM模型是如何如何实现的?(模型结构,数学原理,代码实现)
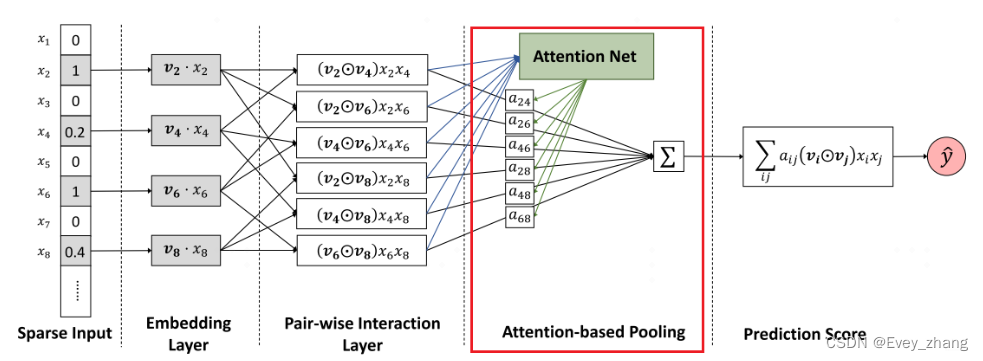
AFM模型是通过在特征交叉层和最终的输出层之间加入注意力网络来引入注意力机制。
2.3.1 Input 和 embedding 层
这里与NFM模型一样,上图中为了简单,把连续型的特征给省去了,输入的是稀疏特征。并且只画了非0的稀疏特征值进入embedding层,得到相应稀疏特征的embedding向量。实际中,每一个稀疏特征值,都会有一个对应的embedding向量的,只不过为0的稀疏特征值,对应的embedding向量也是0罢了。如果一共有n个稀疏特征向量,embeding层应该有n个embeding向量,下面的pair-wise interaction Layer应该有n*(n-1)个交叉特征对。
2.3.2 pair-wise interaction Layer
这里与NFM一样,每对embedding 向量进行各个元素对应相乘(element-wise product),公式如下:
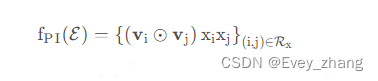
KaTeX parse error: Unexpected end of input in a macro argument, expected '}' at end of input: \dot表示对应元素相乘。 R x = { ( i , j ) } i ∈ X , j ∈ X , j > i R_{x} = \left \{ (i,j) \right \}_{i\in X,j\in X,j>i} Rx={
(i,j)}i∈X,j∈X,j>i,这里的 X X X是非零特征经过embedding层之后得到的embedding集合。若有m个特征向量的话,会有m*(m-1)/2 个交叉向量。也就是pair-wise interaction Layer会产生m*(m-1)/2个交叉向量,每个交叉向量,都是两个特征的embeding向量对应元素相乘得到的向量值,维度是K,K代表每个向量经过embedng后的维度。
注意:
NFM中,两两特征的embeding交叉完毕之后,会直接进行求和的操作,根据之前FM的化简公式,NFM中可以借鉴FM的化简公式,只需要一个公式就能搞定交叉和求和的操作,所以时间复杂度是o(m),m是embedding向量的个数。但是在AFM中,两两特征的embeding交叉完毕之后,不能直接求和,需要加注意力。也就是AFM中,需要先求出两两交叉后的特征向量(维度是k*1),一共有m(m-1)/2 个特征向量,给这些特征向量分别加上注意力权重,然后再进行求和。因此AFM不能像FM或者NFM那样进行公式化简,所以AFM的时间复杂度是o(m^2)。这样就损失了FM的效率。
2.3.3 Attention based Pooling layer
如果不加Attention based Pooling layer 这一层,则上一层产生的m*(m-1)/2个交叉向量直接进行一个sum pooling(对应元素相加),得到一个K维的输出,将这个输出再经过一个全连接层,得到最后的预测结果。

但加入Attention based Pooling layer这一层的想法是,对于每一个特征交叉向量 ( v i ⊙ v j ) x i x j (v_{i} \odot v_{j})x_{i}x_{j} (vi⊙vj)xi<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8209
8209











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









