






协同过滤算法的Limitations
第一个限制就是冷启动问题(对新用户知之甚少,推荐效果不理想):很少用户评分的项目怎么rank,怎么对新用户进行合理地推荐
第二个限制就是协同过滤并没有给我们关于项目或用户的额外信息
所有我们会获得的小提示可以surprisingly与用户的偏好相关联,比如用户在手机端还是电脑端使用;比如用户使用的是Firefox与Chrome,Safari与Edge,使用浏览器的不同也会给我们提供用户可能喜欢什么样的数据

即使协同过滤中多个用户对多个项目进行评分,具有很强大的性能,但仍然存在一些限制,由此我们提出了基于内容过滤算法。
基于内容的过滤算法Content-based Filtering

相比于协同过滤算法推荐项目是基于那些跟用户做出相同评分的其他用户,而基于内容的过滤算法推荐项目是基于用户或者项目的特征去找到用户和项目之间的一种好的匹配match,以下是对于项目和用户特征的定义和一些实例,此外对于项目和用户特征,其向量size可以不同
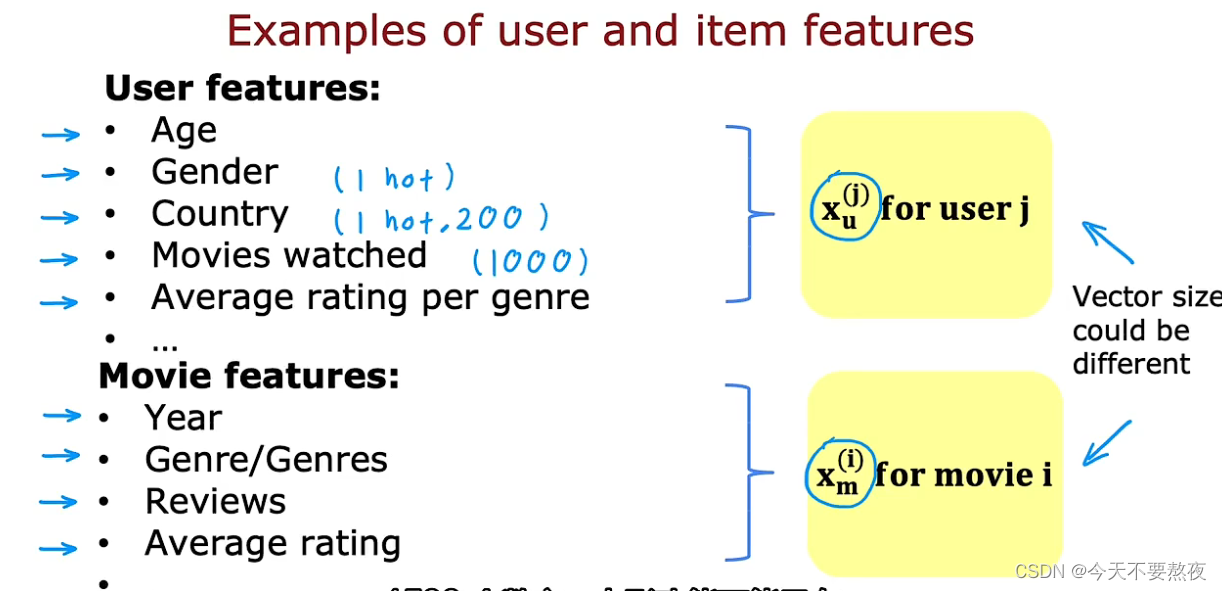
由此通过项目和用户的特征去建立基于内容的过滤算法:
利用用户向量和电影向量之间的点积
这里我们仍然以推荐电影为背景,要预测用户j对电影i的评分(这里我们不考虑b,因为事实证明b不会影响基于内容的过滤算法)将w(j) * x(i)替换为vu(j) * vm(i),这两者分别来自于xu(j)和xm(i),vu是一个用户向量,捕获了用户的偏好preferences,比如得到了如图的向量,其中第一个数字4.9反映了how much 这个用户 likes romance movie,第二个数字0.1反映了how much 这个用户 likes action movie,vm是一个电影向量,表征的是电影的features,比如得到了如图的向量,其中第一个数字4.5反映了电影的romance程度,第二个数字0.2反映了电影的action程度

虽然xu和xm的size可以不同,但是vu和vm的size必须相同,因为要进行乘积运算

用户网络和电影网络可以假设有不同数量的隐藏层和隐藏层中不同数量的单元,只需要保证在最后的输出层具有相同的尺寸相同的维度(此处的32),预测结果为用户j的Vu和电影i的Vm的点积
如果标签为二进制的话,对点积再进行一个sigmod函数的激活
将用户网络和电影网络合在一起,得到最终的神经网络架构,利用成本函数J去训练得到整个网络的各个参数,如果我们愿意的话还可以加入正则化使得参数不至于过拟合,有了成本函数之后就可以通过梯度下降或者其他的优化方法(Adam)去学习参数

同样地,我们仍然可以实现协同过滤算法中推荐相似项目的功能,这也类似于x(k)-x(i)

可以被提前计算出来,这个的意思是说我们可以前一天晚上浏览所有的电影,找到与之相似的电影,以便第二天如果用户访问并浏览特定的电影时,可以推荐出相似的电影
但在实际的应用中,算法的一个限制就是我们需要对feed进网络的特征features进行精心的设计,所以对于具有很多不同电影的大型目录的推荐系统,可以效果不会很好。
均值归一化——加快算法并且使得预测更加合理

在未归一化之前,如果新来的一个用户Eve,暂且并未对于电影进行评分(即对应的列均为问号),体现在cost function中就是对于cost而言起作用的只有wk和xk这两个正则化项,为了使得cost最小那么wk就应该尽可能小,也即为0,且b初始化为0
根据w * x + b那么对应的评分就也为0,这样是不合理的,所以提出均值归一化:
第一项2.5 = (5+5+0+0)/ 4
第二项2.5 = (5+0)/ 2

首先将评分的这些项写入矩阵,计算出每一行的平均值得到向量μ,然后矩阵中的每一项减去μ得到新的矩阵,这个新的矩阵也就是后面我们将会用到的y(i,j)
对于用户j对电影i的预测,由于我们使用的y(i,j)是原来的矩阵项减去平均值μ,所以在这里我们把他加上从而得到评分,所以对于新用户Eve对movie 1 的评分为 w(5) * x(1) + b(5) + μ1 = 2.5,这样的话对于新用户而言,其评分为2.5对于评分为0也更加合理
这里我们采用的是对每一行均值化为0(如第一行 2.5 + 2.5 +(-2.5)+(-2.5)= 0),另外我们还可以采用一种方式就是对每一列均值化为0,对于这两种方法的使用,如果新用户(新加一列)需要对电影进行评分,那么采用每一行均值化为0,如果是新电影(加一行)那么采用每一列均值化为0
寻找相关特征(其应用场景就是当你看到一部电影之后会给你推荐相关的电影)
当我们看到一个项目时,会为我们推荐其他类似或者相关的项目

如果计算的结果不止有一个x(k)使得这两者特征最小,比如找到5个或者10个与项目x(i)相似的项目,this idea of finding related items will be a building blocks that 我们将会使用它去构建一个功能更加强大的推荐系统















 1796
1796











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









