






Defending Against Model Stealing Attacks with Adaptive Misinformation阅读
核心:
本文提出了一种适应性错误信息的方式来防御模型窃取的攻击。核心思想是对良好用户(模型的训练数据)返回正常模型预测,对恶意用户(输入是OOD,训练数据分布外的数据)时返回错误预测,以此来保障目标模型可用性即准确率和安全之间的平衡。
①适应性的错误输出保障了模型的准确率和安全性之间的平衡
②错误函数的错误输出完全破话了真缺预测和错误预测之间隐藏的相关性(即top1不变的扰动还是会泄露掉真确和错误之间的相关性,隐私泄露)
③降低的产生错误预测的计算开销
1、直觉观察现象:
ID的 Maximum Softmax Probability (MSP)值高,而OOD(Out-Of-Distribution)的MSP值低,以此来检测是正常用户的查询还是敌手查询。
常规的模型窃取流程:
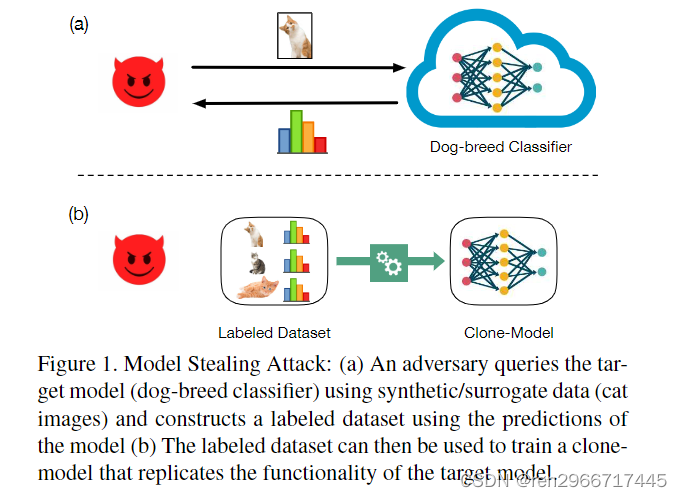
2、主流的模型窃取方法:
①合成数据的窃取(Synthetic Data),即在样本量少时,利用如雅可比矩阵的方式来合成数据去查询目标模型。
②代理数据集的窃取(Surrogate Data),利用影子数据集查询目标模型
3、主流的模型窃取防御方法:
① Stateful Detection Defenses:检测是否正常用户
② Perturbation-Based Defenses:与预测结果进行扰动,按防御者的需求有分为两种方法:
1,Accuracy Preserving Defenses,即只对top1的预测不变,对其余部分扰动。保障目标模型的精度
2,Accuracy-Constrained Defenses,对预测的整体扰动,比如 Prediction Poisoning (PP),在目标模型限定准确率的基础上保障模型的安全性。
本文属于Accuracy-Constrained Defenses一类
本文的防御流程:
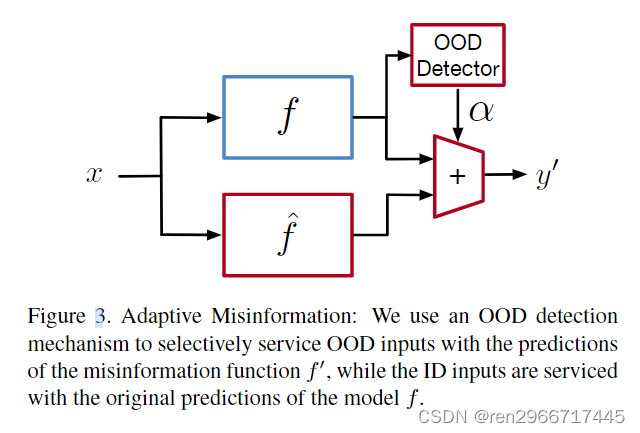
由三个模块组成: (1) An OOD detector (2) A misinformation function (f0) (3) A mechanism to gradually switch between the predictions of f and f0 depending on the input.
(1)An OOD detector:最大类的盖度概率大于阈值者为良好用户,否者为敌手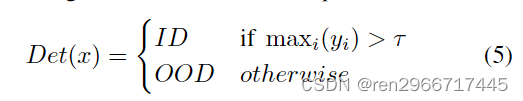
(2)A misinformation function (f0):训练最小化正确分类的概率。与目标模型的训练目标相反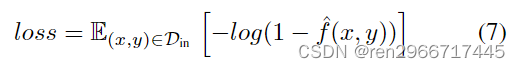
(3)A mechanism to gradually switch between the predictions of f and f0 depending on the input.:输出交替转换机制,若ymax大于阈值即阿尔法接近0,则输出正常模型预测;若小于阈值,即阿尔法接近1,则输出错误的预测结果。

问题:
1,这种方式虽保障了模型的安全,按常理来说部署模型后公开付费API给用户,这些用户应该更多的是OOD的数据,这样用户只会收到错误的结果。
2,在OOD detector阈值检测器中,大于阈值的为正常用户否则为恶意。这不是与成员推理类似。难道非成员就是恶意用户的数据,太过绝对。














 88
88











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









