







一、研究背景:人工智能和深度学习算法正在高速发展,这些新兴技术在音视频识别、自然语言处理等领域已经 得到了广泛应用。然而,近年来研究者发现,当前主流的人工智能模型中存在着诸多安全隐患,并且这些隐患会限制人工智能技术的进一步发展。
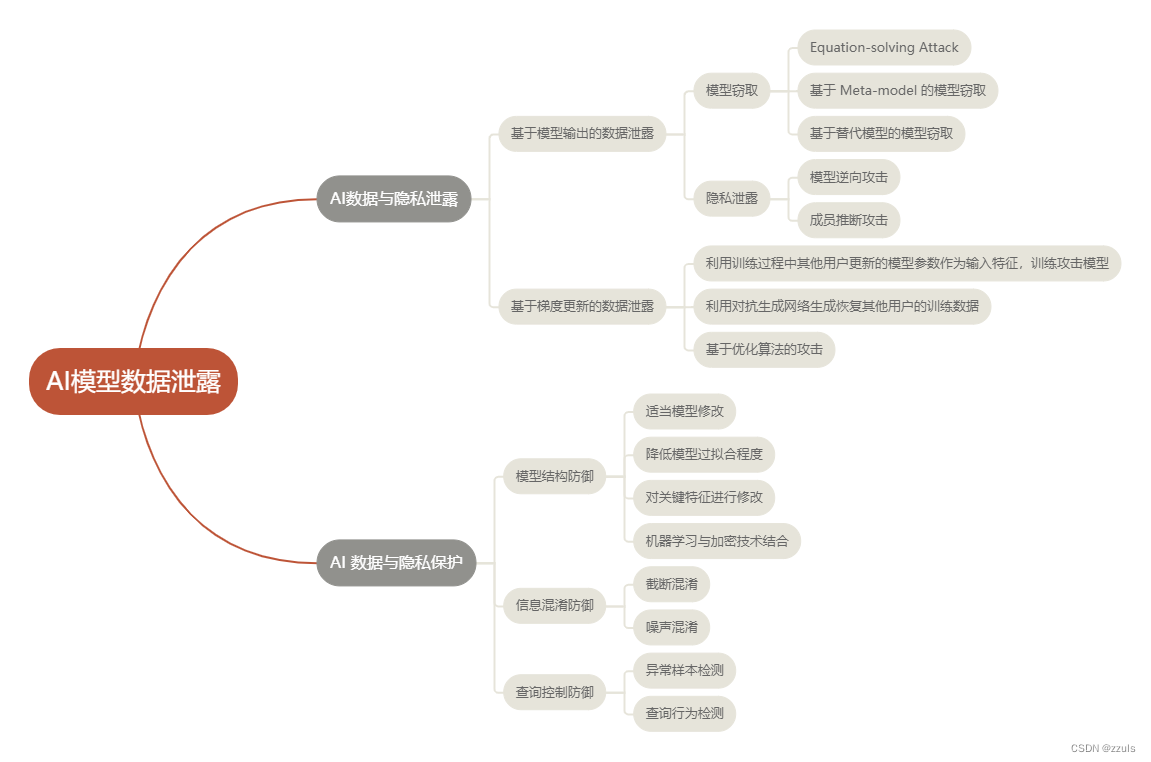
二、论文研究的问题:主要研究了基于模型输出的数据泄露问题和基于模型更新的数据泄露问题。在基于模型输出的数据泄露问题中,主要探讨了模型窃取攻击、模型逆向攻击、成员推断攻击的原理和研究现状;在基于模型更新的数据泄露问题中,探讨了在分布式训练过程中,攻击者如何窃取隐私数据的相关研究。对于数据与隐私保护问题,主要研究了常用的 3 类防御方法,即模型结构防御,信息混淆防御,查询控制防御。
三、论文创新点:综述型论文,主要是对已有的工作总结
四、思维导图
五、主要技术点
AI数据与隐私泄露:
1.基于模型输出的数据泄露:模型输出结果隐含一定的数据信息。攻击者可以利用模型输出在一定程度上窃取相关数据
(1)模型窃取:通过向黑盒模型进行查询获取相应结果,获取相近的功能,伪造模型。
Equation-solving Attack:主要针对支持向量机(SVM)等传统的机器学习方法的模型窃取攻击。攻击者可以先获取模型的算法、结构等相关信息,然后构建公式方程来根据 query 的返回的结果求解模型参数(通过获得参数来重构模型,不适合参数众多的神经网络)
基于 Meta-model 的模型窃取:跟Equation-solving Attack类似,需要找一些与目标模型类似的模型,然后主要是要构建一个训练集出来,训练集的输入是目标模型的输出,输出是预测目标模型的相关属性,如激活函数,网络层数等。(需要较多的计算资源)
基于替代模型的模型窃取:向目标模型查询样本,得到目标模型的预测结果,并以这些预测结果对查询数据进行标注构建训练数据集,在本地训练一个与目标模型任务相同的替代模型。
(2)隐私泄露:目标模型的输出向量中可能包含了输入信息,可能导致训练集中的敏感信息泄露。
模型逆向攻击:将模型逆向攻击问题转变为一个优化问题,优化目标为使逆向数据的输出向量与目标数据的输出向量差异尽可能地小,可以通过梯度下降的方法来优化。
成员推断攻击:攻击者将试图推断某个待测样本是否存在于目标模型的训练数据集中,从而获得待测样本的成员关系信息。可以通过更新前后的模型对同一个数据集给出的预测向量的差异,来完成对目标模型更新集中特定数据的存在性推断。
2.基于梯度更新的数据泄露:梯度更新是指模型每一次对模型参数进行优化时,参数会根据计算产生的梯度来进行更新,而在训练过程中不断产生的梯度同样隐含着某些隐私信息。
(1)利用训练过程中其他用户更新的模型参数作为输入特征,训练攻击模型
(2)利用对抗生成网络生成恢复其他用户的训练数据:在多方协作训练过程中,使用公共模型作为基本的判别器,将模型参数更新作为输入训练生成器,最终获取受害者特定类别的训练数据。
(3)基于优化算法的攻击
AI数据与隐私保护
1.模型结构防御:对模型结构做适当的调整,以此来减少模型泄露的信息,或者减少模型的过拟合程度。
(1)适当模型修改:对决策树可以使用CART剪枝,当敏感特征在在根节点和叶子结点时,对 model inversion 攻击能够达到较好的防御效果。也可以在目标模型中添加 Dropout层。
(个人感觉,如果只是要降低模型的过拟合,方法还是很多的)
(2)降低模型过拟合程度:如果一个模型的拟和程度比较高,那么攻击者容易找到模型的一些边界,从而容易实现成员函数攻击。
(3)对关键特征进行修改:可以对训练数据在目标模型的关键特征上进行特定的修改,从而使模型对成员数据和非成员数据的预测向量的分布难以区分,进而可以完成对成员推断攻击的防御。
(4)机器学习与加密技术结合:可以在每次模型梯度更新的同时,使用差分隐私技术对梯度做一定的修饰,从而保护训练数据集的隐私性。
2.信息混淆防御:面向数据的防御是指对模型的输入样本或预测结果做模糊操作。通过这些模糊操作,在保证AI 模型输出结果正确性的前提下,尽可能地干扰输出结果中包含的有效信息,从而减少隐私信息的泄露。
(1)截断混淆:就是对模型的输出向量进行截取,如只给出输出向量中概率值较高的类别的相应结果,或者降低输出向量中小数位的保留位数。
(2)噪声混淆:成员推断攻击对目标模型给出的预测向量的变化非常敏感,如果为这些预测向量添加一个精心设计的噪声,从而混淆成员数据和非成员数据的预测向量分布的差异,就可以生成一个对实际结果没有影响的“对抗样本”,就可以完成对成员推断攻击的防御。
3.查询控制防御:查询控制防御是指防御方可以根据用户的查询行为进行特征提取,进而完成对隐私泄露攻击的防御。
(1)异常样本检测:攻击者往往需要对在线模型进行大量的查询操作。为了提高窃取效率,攻击者会对正常的样本进行有目的地修改。而针对模型泄露攻击的特点,防御者主要通过检测对异常样本的查询,来识别模型窃取行为。PRADA它根据多个样本特征之间的距离分布来判断该用户是否正在施展模型窃取攻击。
(2)查询行为检测:攻击者其查询行为与正常行为会有较大不同。根据这种差异可以在一定程度上防御模型泄露和数据泄露攻击。攻击者实行成员推断攻击时有时需要查询大量目标模型,模型提供者可以根据用户的查询频率实现对查询次数的限制,从而提升攻击者部署成员推断攻击的成本。
- 总结与展望:
读完这篇论文,我觉得人工智能安全相关的隐私保护,还是有很多可以做的更好的地方的。本文提出的是:未来在攻击方面,第一类是优化攻击模型,增强其从输出向量中提取信息的能力;第二类是扩展攻击场景,将数据泄露攻击应用到更多的场景中,如迁移学习、强化学习等;第三是如何进行模型查询,不被发现。一是针对输出向量进行混淆,降低其所包含的信息;二是对隐私数据进行混淆,可以构建特定的噪声来修饰原使用数据,从而降低模型推断结果的信息;三是对模型本身的参数做混淆,如引入隐私保护机器学习的方法,对模型内部的参数、中间结果和输出向量进行加密处理,降低其泄露信息的可能性。

















 726
726

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









