






源自:系统仿真学报
作者:龚雪, 彭鹏菲, 荣里等
注:若出现无法显示完全的情况,可 V 搜索“人工智能技术与咨询”查看完整文章
人工智能、大数据、多模态大模型、计算机视觉、自然语言处理、数字孪生、深度强化学习······ 课程也可加V“人工智能技术与咨询”报名参加学习
引言
目前,国内外学者对任务分析方法[1]的研究主要是从3个角度出发:①传统的任务解析模型[2-4];②数学模型解析方法[5-6];③智能分析方法[7-11]。在传统任务分析算法研究中,文献[12]从任务的细粒度出发,为降低对紧急任务的响应效率、减少等待时间和任务完成时间,在面向多机器人环境中,从动态异构任务的细粒度出发,研究了动态任务分配与调度方法。文献[13]引入任务与体系的关联映射规则,提出了一种基于网络信息体系“两维四网”模型构建及特性分析方法,并以空中突击作战为例,结合任务执行精度等资源冗余度指标,研究了面向任务的网络信息体系方法。文献[14]提出了一种基于深度强化学习(deep reinforcement learning, DRL)的非线性动力学系统自适应轨迹规划方法,在高保真模拟环境中的无人机上进行训练和评估,结果体现了基于DRL的自适应方案的学习曲线、样本复杂度和稳定性。
战术弹道导弹[15-17](tactical ballistic missile, TBM)的特性是跨度大、精度高、高空高速,为了实现对TBM的拦截,要求在极短的窗口时间内进行分析并规划拦截。然而实际情况中,反TBM规划方案变化大、影响因素复杂,且反TBM在预警探测、目标截获、跟踪识别、火力拦截、杀伤效果评估等作战任务环节中。每一个环节都环环相扣,任意一个环节都不能单独进行,给反TBM的任务分析带来巨大挑战。任务分析是任务规划的关键步骤,因此,对反TBM的耦合任务分析和分解是十分必要的。
现有研究成果从任务细粒度出发,并通过任务协同关系的定量分析得出任务执行序列。上述算法在一定程度上能解决任务分析问题,但仍存在许多缺陷,如针对数学解析模型,该模型由于难以考虑多方面的任务交互信息,因而局部最优[18-19];智能分析方法[20]存在依赖于初始解、参数复杂、迭代时间长、底层存储机能和收敛过早等问题;强化学习算法[21-22]虽可有效解决参数复杂及初始解依赖问题,但算法处理连续性问题的能力较弱,存在实时性较差、时间延迟等问题。
本文针对任务分析中任务信息交互因素复杂和任务间耦合度高的问题,运用深度强化学习算法思路[23-27],提出基于序列解耦与深度强化学习的任务分析方法:先引入激活函数,动态设计深度强化学习中贪婪激活因子,并结合任务间信息交互的特征改进SumTree算法;通过SumTree算法评估的任务优先级,不断更换智能体执行的初始任务,开展深度网络的训练,并将学习经验存放至经验池中;通过经验回放策略对任务序列进行重构。
1 基于序列解耦的任务环境设计
本文针对任务分析中任务信息交互因素复杂的问题,提出可处理实际应用场景的基于深度强化学习[28]的序列解耦任务分析环境设计方法。任务环境是指针对任务间的信息交互,设计agent的可达路径,即agent可执行的任务序列。为解决任务间耦合度过高以及任务信息交互因素复杂的问题,设计agent的序列解耦运行环境,以期降低任务耦合度及任务可执行的困难程度。基于深度强化学习多目标任务分析算法在DQN(deep Q-Learning)算法[29]的基础上引入了任务序列池来更新经验池中的数据,使得DQN算法[29-31]在任务分析领域得到应用。本文算法流程如图1所示。
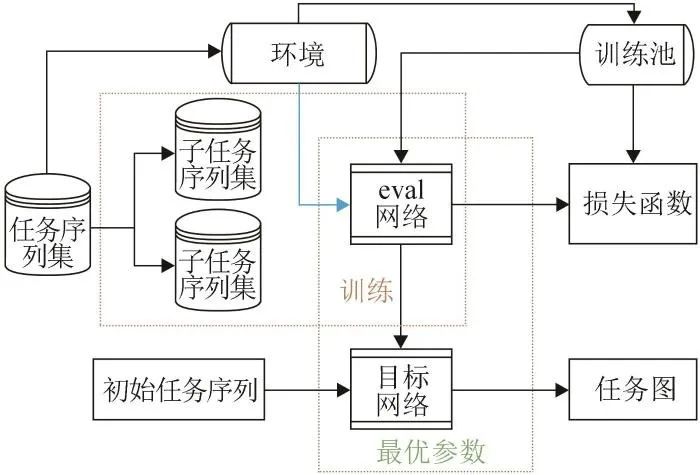
图1 基于深度强化学习多目标任务分析算法流程图
1.1 状态‒动作空间定义
本文将一个任务视为一个状态,一个任务向另一个任务进行转接时,需要将转接的下一个任务视为当前任务的动作。因此根据任务信息矩阵,在知晓目标的前提下,寻找最优的任务执行序列图即为该智能体的目标。通过设计状态‒动作矩阵,让智能体的进行策略性的选择,适当对智能体进行奖励和惩罚,以激励智能体不断和任务环境交互,从而在探索出的任务图中寻得最优。
(1) 状态‒动作矩阵设计
状态‒动作矩阵中每一行表示智能体的每一个状态,每一列表示智能体的每一个动作,则(状态,动作)值表示任务与任务直接的信息交互程度,例如,状态动作矩阵 I (1,2)=0.7表示该智能体在第一个任务,且智能体的状态是1的时候采取的动作2也即智能体将要执行任务2的时候,任务1和任务2的关联程度为0.7。
(2) 状态的选择
智能体通过深度强化学习进行动作选择,执行状态转移函数,状态转移函数关联任务信息矩阵和状态‒动作矩阵,进行实时变换状态。
(3) 任务信息交互矩阵
任务信息矩阵表示任务间的无效时间耗用关系,若是任务间有耦合性则无效时间耗用就长,反之则短。该矩阵是一个动态变化的矩阵,在智能体不断进行参数更新的过程,随着奖励矩阵的更新,信息交互矩阵也随之更新,可以说,信息交互矩阵为奖励矩阵的扩展。
1.2 动作选择策略
针对ε-greedy算法中贪婪因子ε设计,提出了一种基于tanh函数机制的自适应动态调整策略:最初时,将ε设置较低值,随着迭代次数的增加,智能体对任务环境的认知能力变大,此时,对ε数值进行逐步增加,最终得到贪婪激活因子的取值。
贪婪激活因子ε的定义为
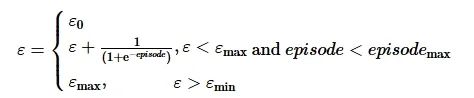
(1)
式中:εmax 为贪婪激活因子ε 的最大值,0<εmax <1;ε0 为贪婪激活因子ε 初始值,0<ε0<εmax ;eqisode为整数,代指算法当前迭代次数,[0,episodemax] 。设置 εmax=0.99,ε0=0.1,eqisodemax=30 000 000。
1.3 网络结构设计
如图1所示,每隔一定时间将eval网络的参数传递给目标网络,最终通过训练得到最优的参数值。设置eval网络的损失函数为
![]()
(2)
式中:Q(s',a'λ) 为目标网络;w为网络的权值;s为当前状态;s' 为下一个状态;a为状态s下的动作;a' 为状态s' 的动作值;γ为网络折损率;r为智能体与环境交互获得的奖励。
1.4 序列解耦环境设计
在设计深度强化学习的算法运行环境时,假设agent需要对n个任务进行处理,且最终的多个目标任务已知。在初始化时,agent对任务tk 进行判别,若任务tk 与任务tk+1 有信息交互,则记tk 为智能体可达,此时,智能体可由任务tk 到达任务tk+1或由任务tk+1到达任务tk,即针对任务间的信息交互,智能体能采用策略选择机制寻得最优的任务序列图。若任务tk 与任务tk+1间没有信息交互,则记为智能体无法从任务tk 到达任务tk+1。另外,设计环境奖励矩阵的依据为通过专家评价,若任务tk+1完全依赖于任务tk 的信息输出,则记r(s,a)=1;若任务tk+1不完全依赖于任务tk 的信息输出,则记r(s,a)处于(0,1)的区间;若任务tk+1完全不依赖于任务tk 的信息输出,则记r(s,a)为-1;若是以某个任务为目标,则记r(s,a)处于(100,150)的区间,这个阶段是强化学习初期生成智能体执行序列元组的关键阶段。
在上述构建的环境中,因本文智能体执行的动作表示下一个任务,又因智能体当前的状态表示的是当前任务,故图2中As 为智能体在状态s下所执行的动作。通过任务信息交互矩阵可知两个任务的实际耦合程度。通过设计耦合阈值过滤耦合任务集,根据智能体奖励机制,将智能体执行每一个任务的打分和任务信息交互矩阵进行比对、处理并存入经验池,将经验池的数据标准化后,更新任务信息交互矩阵。
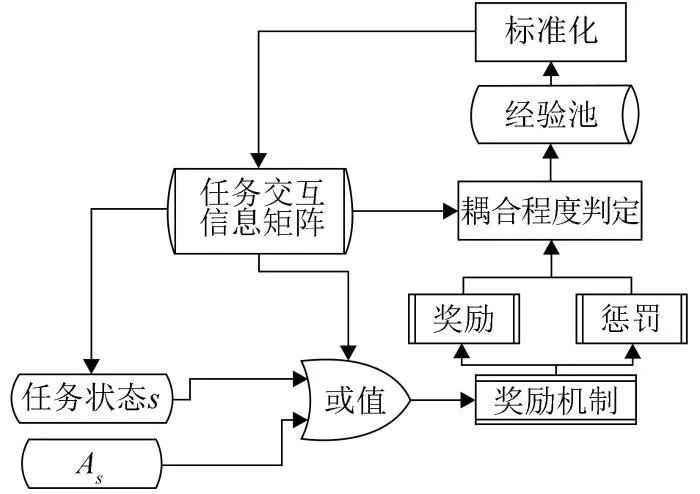
图2 解耦环境设计
在没有完成任务的情况下,做出如下界定:从最近的任务开始,尽量减少与目标之间的距离,并与最近的任务互动获得相应的行动奖励C。具体表达式为

(3)
式中:
![]()
为上一个任务的奖励累积;α为扰动系数,取值为[0,1]。
2 基于深度强化学习的任务分析方法
2.1 深度强化学习的任务分析方法设计
本文针对强化学习中的经验折损策略,引入激活函数机制,使经验折损率随着训练回合的增加而增加,而非单一的折损系数。经验折损率的动态设置能提升深度神经网络寻优的性能。通过动态设置贪婪因子,使网络搜寻的范围更加宽广,促使智能体的动作选择策略精度得到提升,基于改进高斯变异SumTree算法,动态评估任务优先级,并将任务优先级与网络参数结合,从而得到一个参数训练良好的目标网络。本文的任务分析方法步骤如下。
-
step 1:获取智能体正在执行的任务序号。
-
step 2:根据动作效用函数的计算方法,除当前任务外,计算其他任务的可能Q值。
-
step 3:利用贪婪策略挑选下一个可执行的任务。
-
step 4:智能体执行该任务。
-
step 5:将智能体执行的任务序列进行记忆存储。
-
step 6:进行样本批量训练。
-
step 7:将训练好的网络参数进行应用,通过经验回放,得到可执行任务序列图。
2.2 基于高斯变异的任务优先级的SumTree算法构建
高斯变异的SumTree算法的结构如图3所示,图中所示为二叉树结构,二叉树算法结构能提升子任务序列的重复利用率。在该算法中,任务序列样本代表叶子节点,且通过高斯变异处理叶子节点样本以增加抽取的随机性,叶子节点的优先级一般通过TD-error[32]确定。本文基于指数函数放大机制,将Q_target网络和Q_eval网络的Q值之差替代TD-error,以此确定叶子节点的优先级。Q_target网络和Q_eval网络的Q值相关性越不明显,则模型的预测精度越差,则被训练的价值就越大,因此节点优先级越高。高斯变异的SumTree算法优先级表示为
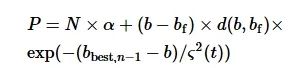
(4)
式中:n为当前叶子节点的序号;N为所有叶子节点之和;bf为b的父节点;d(b,bf)为叶子节点到父节点的欧式距离;bbest,n-1为上次训练最优的叶子节点;α为多样性指标,需根据求解模型自行设置;ϛ2(n)为高斯变异幅度,
![]()
。
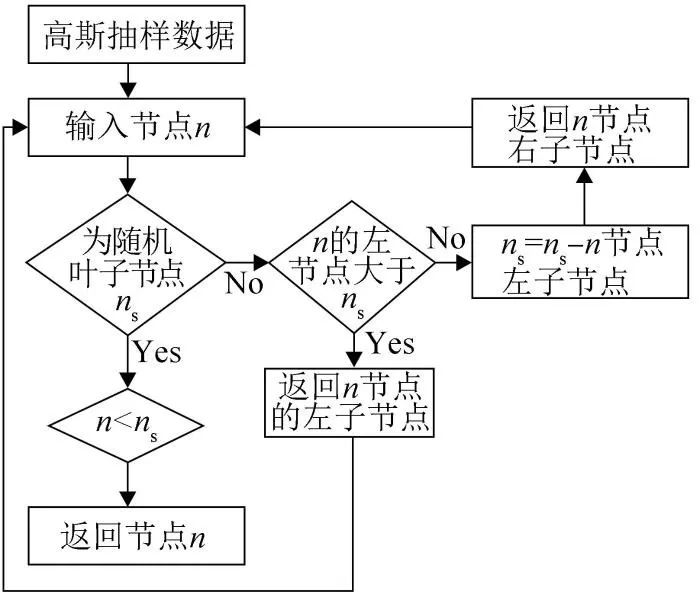
图3 高斯变异SumTree算法流程
3 基于序列解耦与深度强化学习的任务分析方法
在训练过程中,目标网络的参数通过batch训练不断地更新优化,并通过固定时间节点给目标网络赋参。本文目标任务状态设置为多个,目标网络根据下一个状态的输入给出下一个状态的Q值(Q_next),再将Q_next代入策略函数得到Q_target,将得到的目标任务状态和设置的目标任务状态群进行异化操作,若有一个目标状态与该Q_target吻合,则给予agent奖励,并且计算loss(Q_value,Q_target),将损失反向传播并优化网络参数,即可得到更好的神经网络。经过反复的训练优化后,智能体能基本掌握各种任务状态下的动作决策,训练的主要流程如图4所示。
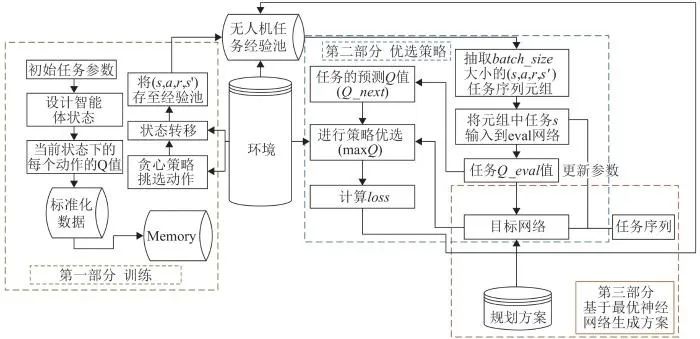
图4 基于改进强化学习的多目标任务分析训练流程
基于序列解耦与深度强化学习的任务分析方法步骤如下:
(1) 收集元组
-
step 1:获取随机任务状态。
-
step 2:根据eval网络,计算除当前任务外,计算其他任务的可能Q值。
-
step 3:基于高斯变异的任务优先级的SumTree算法计算当前任务优先级。
-
step 4:在和环境进行交互的同时,利用贪婪策略挑选下一个可执行的任务。
-
step 5:对当前任务的优先级进行记忆。
-
step 6:获得下一个需执行的任务即智能体的动作。
-
step 7:将任务当前状态的元组进行记忆存储。
(2) 训练网络
-
step 1:从经验池中抽取任务状态元组样本。
-
step 2:计算eval网络参数,并判断是否已经有一个周期T,若是则执行step 3,否则执行step 4。
-
step 3:更新目标网络参数。
-
step 4:更新Q_eval值。
-
step 5:预测Q值。
-
step 6:和环境进行交互,策略优选Q值。
-
step 7:计算loss。
(3) 基于最优神经网络生成任务图
-
step 1:输入任务序列。
-
step 2:最优的网络参数进行应用,将任务序列输入目标网络。
-
step 3:可执行任务序列图。
基于开关的机制,本文设计了2个策略函数更新的方式:①智能体在奖励映射很小时的动作空间的选择,②反馈奖励极大时智能体的状态空间的设置。其策略公式为
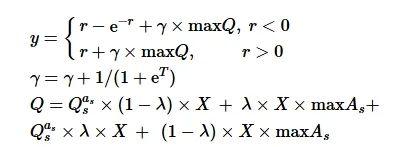
(5)
式中:
![]()
为当前任务状态下执行动作as 的Q网络的值;X为二进制函数,若当前总的奖励值小于0时取0,反之取1;λ=0.98为折损值;maxAs 为当前状态下所有动作的概率值中取最大;y为策略函数;T为回合数;γ为每次训练后的折损值,γ随着回合数的增加而不断降低;r为每个回合智能体所得的奖励值。
4 实验分析
TBM具有跨度大、高空高速、RCS小的特点,所以TBM被探测和拦截的时间窗口很短。因此,要求拦截速度快,且拦截成功率高,针对多批次,多方向和多角度的临近饱和攻击的TBM,本文以60枚TBM来袭任务事件模拟开展实验分析,将反TBM作战任务抽象为60个任务[19],采用基于改进深度强化学习的任务分析算法完成任务序列重组及任务图重构。
4.1 改进深度强化学习的任务分析参数设置
基于深度强化学习的任务分析改进算法的模型参数,具体如表1所示。
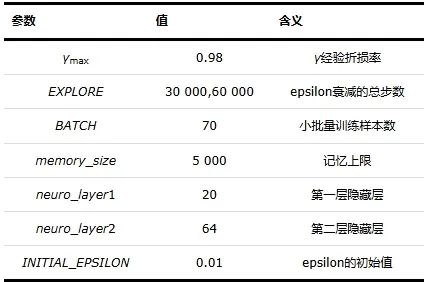
表1 仿真实验模型参数表
4.2 改进深度强化学习的任务仿真实验分析
(1) 算法有效性分析
图5展示了改进深度强化学习算法和标准深度强化学习算法在不同任务量下的Q值分析曲线。可以看出:随着迭代次数增加,任务数量为15和30时,改进算法在12 000多步时达到收敛效果,且在20 000步时,Q_eval已经没有很明显的变化,表示智能体成功跳出了局部最优并达到了全局最优,此时网络的训练参数已达最优,说明智能体在环境中已经寻得最优任务执行方案。当任务数量为60和90时,随着任务数量的增加,任务执行的环境随机性增加,则改进算法收敛速度变慢,都在50 000步左右开始震荡减小,并逐渐达到收敛,说明此时智能体已经掌握了环境的变化。而图5中,随着迭代和任务数量的增加,标准算法没能得到收敛,说明该算法下的智能体还未掌握环境的变化,还在适应环境,并对任务方案进行探索。因此证明在本文设计的解耦环境中,本文改进深度强化学习算法效率更高,实时性更强,解耦能力更高,且在影响因素繁多的情况下,本文改进深度强化学习算法收敛速度更快,智能体适应环境的速度更好,并最终寻得最优的任务执行方案。
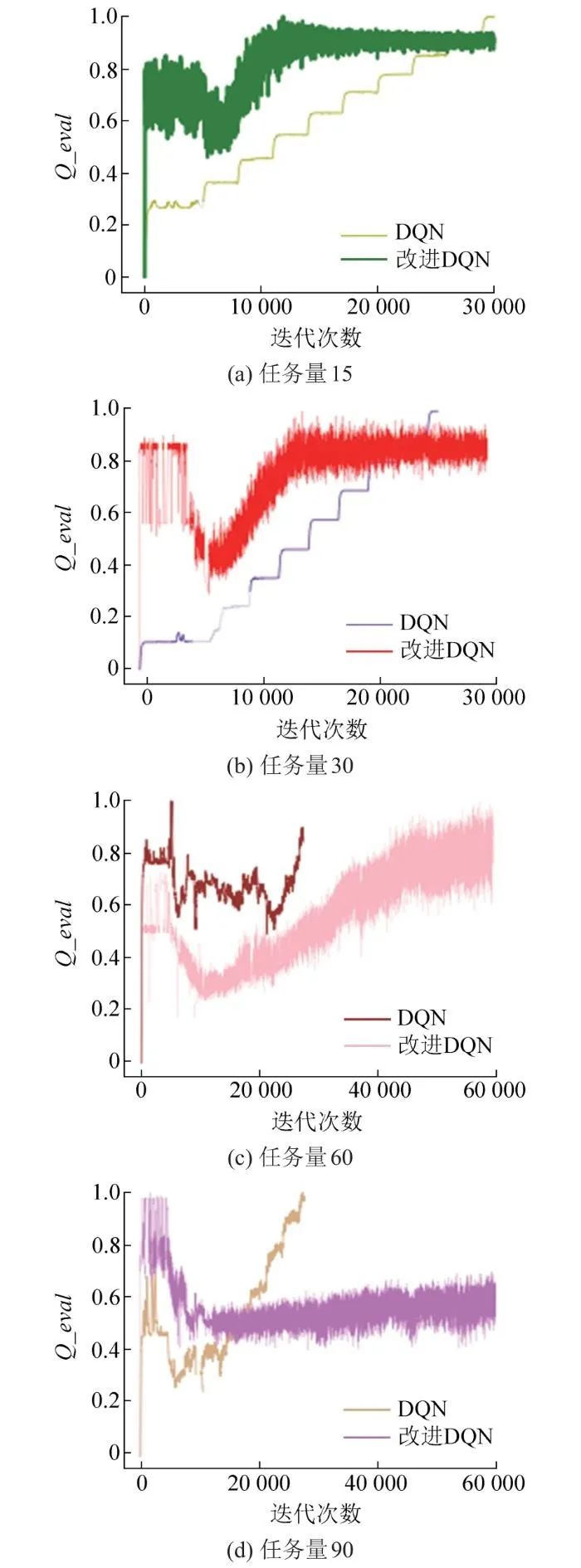
图5 两种算法的最终Q值分析曲线
图6展示了基于改进深度强化学习在超参数不同情况下的观测值和真实值之间的距离变化。从图中可以看出,当训练样本为90、经验折损率初始值为0.85、任务数量为15和30时,其收敛速度更快,平稳度更高,震荡值较小,收敛效果更优;当任务数量为60和90时,其平稳性相对较高,但任务数量为60时Q_eval值几乎重叠,但任务数量为90时,其Q_eval值明显变小收敛效果明显更优。因此认为当训练样本为90,经验折损率初始值为0.85时,其效果更优,其loss变化值如图7所示,随着任务数量的增加,loss的收敛效果越来越小,相比样本数为70、经验折损率为0.9时更小,因此从loss的收敛效果来看,当训练样本为90,经验折损率初始值为0.85时,其效果更优。因此,本文选择的样本规模为90。
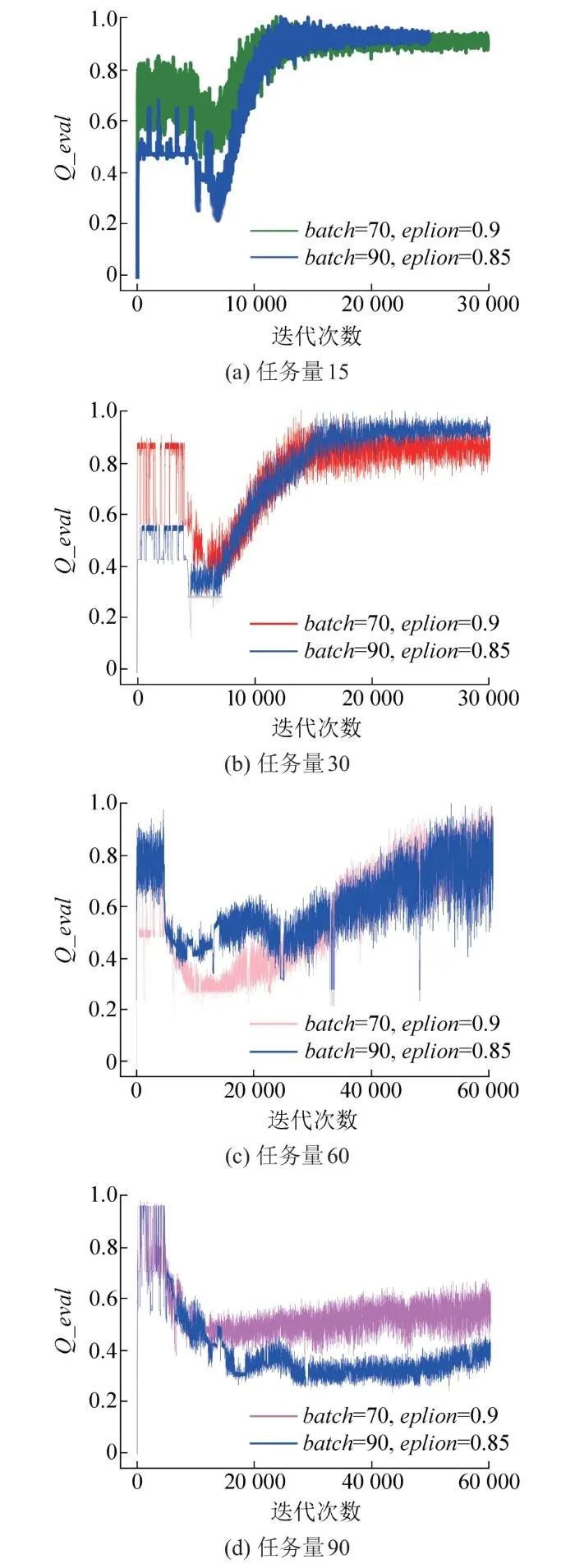
图6 不同超参数的Q值对比
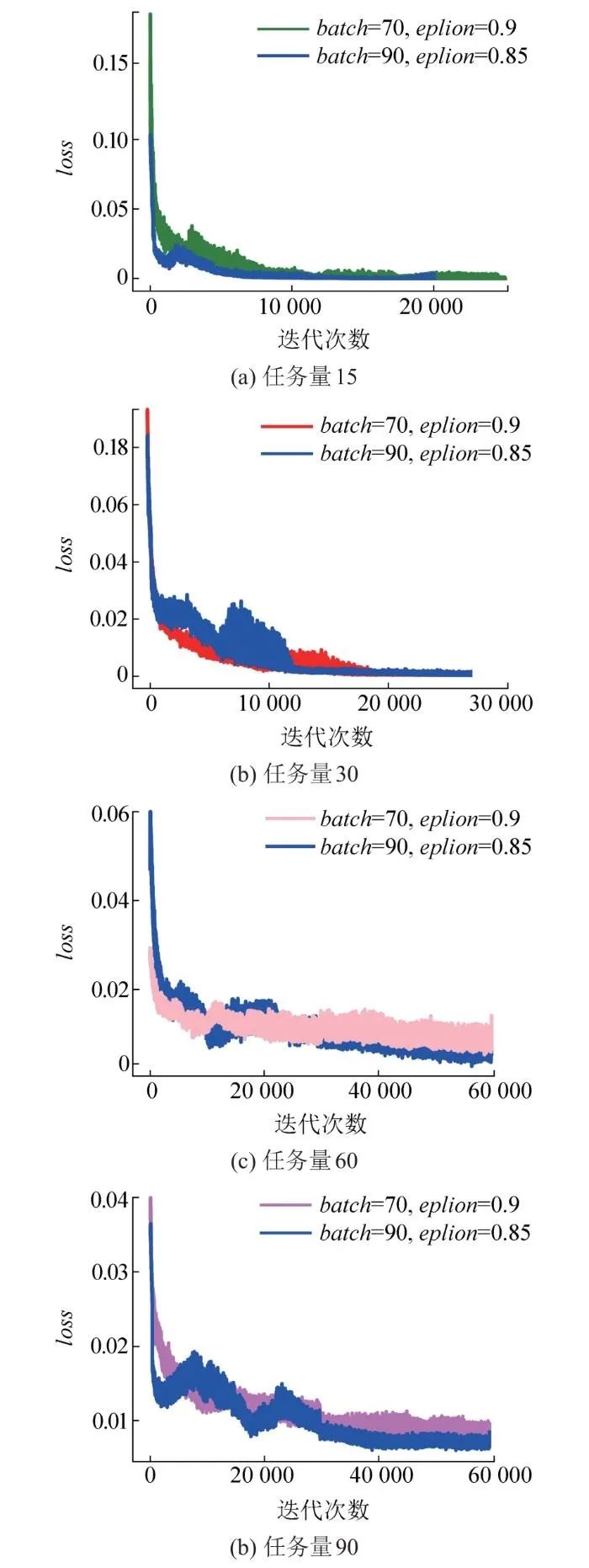
图7 不同超参数的loss值对比
图8展示了改进深度强化学习和标准深度强化学习算法的loss函数随迭代次数的变化。本研究设置的衰减值为30 000步,由图8可知,改进深度强化学习任务分析算法在10 000步时已有收敛趋势,而标准深度强化学习算法在20 000步以后才稍显收敛趋势,因而标准深度强化学习算法在进行任务分析时的计算效率较低。分析原因可知,改进深度强化学习任务分析算法能考虑多样化输入,故其收敛速度更快,运行效果更佳。
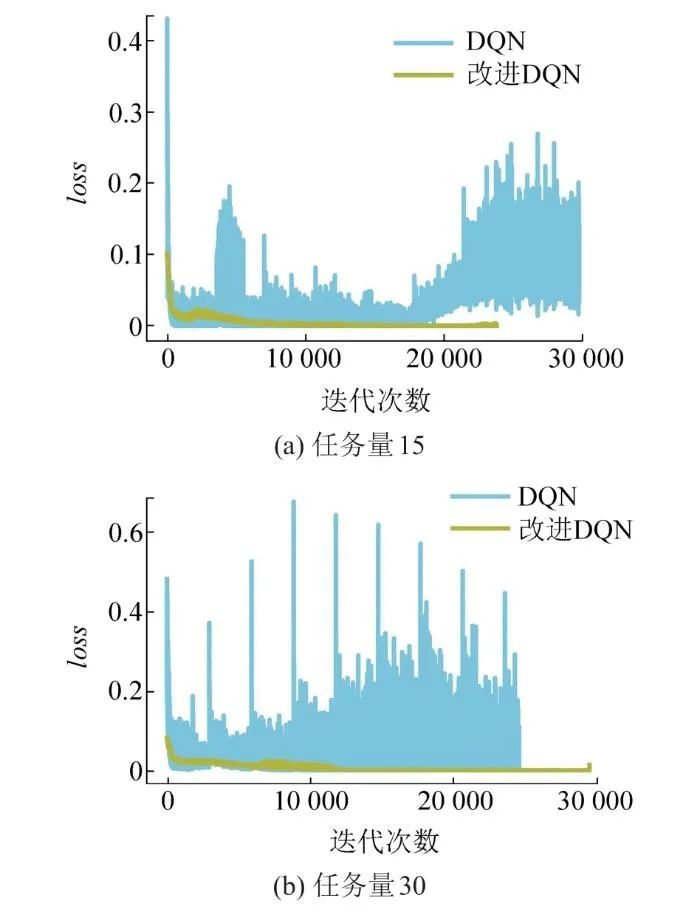
图8 两种算法的loss迭代曲线
图9和10分别展示了基于序列解耦与改进深度强化学习算法所得的任务可执性系数图和任务分析图。任务可执行系数由模糊矩阵方法[33]的拓展应用可得,随机从60个任务中抽取30个任务进行计算,若任务可执行性系数大于0.5的数量总和超半数,则判定该任务集可执行。
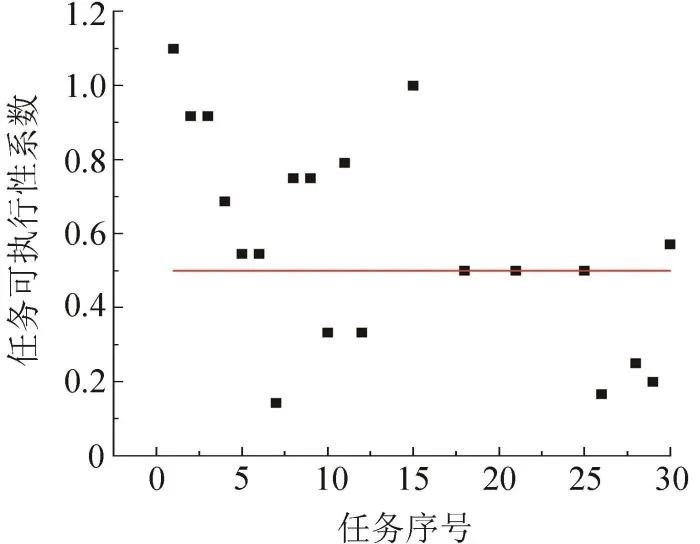
图9 基于序列解耦与改进深度强化学习算法的任务可执行性系数
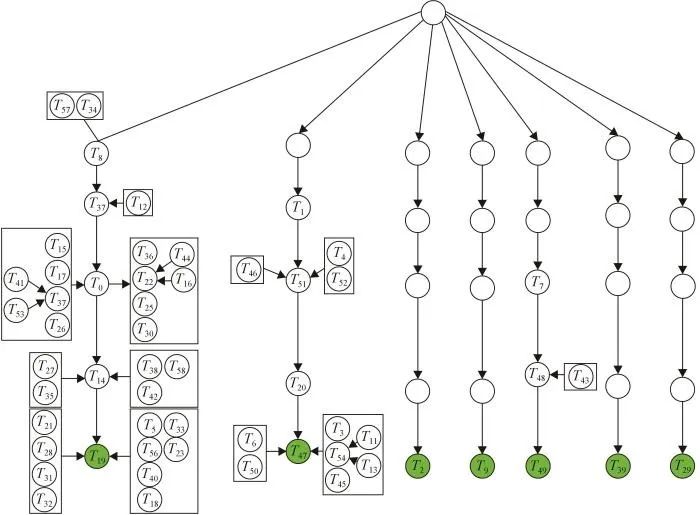
图10 基于序列解耦与改进深度强化学习算法序列图
从图10可以看出,本文设置的任务目标为绿色填充的圆圈,若将任务执行路径看作为大树,则主干部分是T8→T37→⋯→T19 和T1→T51→⋯→T47 等,则支流部分的执行路径为T21→T19 和T34→T8→⋯T19 等,因此经过解耦后的任务可从支流到主干再到任务目标,也可从支流直接到任务目标;也即从开始的一个任务目标,分解为多个任务目标,实现支流并行,从而达到解耦合的目的。
5 结论
本文提出基于改进深度强化学习任务分析算法,通过不断地网络调参将训练值存入经验池,而后由经验池再进行网络取值训练,产生针对各个回合的最优网络,最终实现基于改进SumTree深度强化学习的回合网络,得到符合不同情景的任务分析图。
仿真实验结果表明,该算法比标准深度强化学习算法更具操作性,且计算效率更高、实用性更强,能快速在一个相对较小的回合数实现网络收敛,产生较好的任务分析图,具备解决任务分析问题的人工智能算法基础。
将深度强化学习和改进SumTree算法结合,能一定程度上解决任务分析问题。但算法也存在缺点,如无法克服Q-learning的过高估计问题,因此,可考虑将深度强化学习算法和粒子群算法结合,开展进一步的任务规划问题研究。
声明:公众号转载的文章及图片出于非商业性的教育和科研目的供大家参考和探讨,并不意味着支持其观点或证实其内容的真实性。版权归原作者所有,如转载稿涉及版权等问题,请立即联系我们删除。
注:若出现显示不完全的情况,可 V 搜索“人工智能技术与咨询”查看完整文章
人工智能、大数据、多模态大模型、计算机视觉、自然语言处理、数字孪生、深度强化学习······ 课程也可加V“人工智能技术与咨询”报名参加学习















 2181
2181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









