







 本文介绍如何安装ANTLR,并通过简单的'HelloWorld'语法实例开始学习。包括ANTLR的安装步骤、命令行使用方法以及如何运行ANTLR生成解析器和测试识别器。重点展示了如何创建、编译和测试简单的语法文件,提供了实用的命令行技巧和工具,如设置别名、使用TestRig等,以简化语法测试过程。
本文介绍如何安装ANTLR,并通过简单的'HelloWorld'语法实例开始学习。包括ANTLR的安装步骤、命令行使用方法以及如何运行ANTLR生成解析器和测试识别器。重点展示了如何创建、编译和测试简单的语法文件,提供了实用的命令行技巧和工具,如设置别名、使用TestRig等,以简化语法测试过程。
第一部分ANTLR和计算机语言
在第一部分中,我们会学习ANTLR安装,尝试通过一个简单的“HelloWorld”语法,并了解语言应用程序开发大纲。有了这些基础,我们将建立一个语法去识别和翻译大括号中的整数列表,如{1,2,3}。最后,我们将通过一些ANTLR功能简单的语法及应用去开启对antlr的学习之旅。
初识 ANTLR
我们在本书第一部分的目标是把ANTLR功能做简要的的概述并对语言应用体系结构进行探讨。一旦我们绘制出了总体的纲要,我们将在第二部分使用很多的实例来循序渐进地、系统地学习ANTLR。让我们安装ANTLR然后尝试一个简单的“Hello World”语法实例来开始吧。
1.1 ANTLR的安装
ANTLR是用Java编写的,所以在你开始之前需要先安装Java。即使你打算用ANTLR生成另一种语言的解析器,如C#或C++(我希望在不久的将来还有其他的语言),安装Java也是需要的。ANTLR需要Java 1.6 以上版本。
为什么这本书中使用的命令行shell
在这本书中,我们将使用命令行(shell)运行ANTLR和创建应用程序。因为程序员使用多种开发环境和操作系统,操作系统shell是我们常见的唯一“接口”。使用shell也使得在语言应用开发的每一步都构建的十分清楚。为了保持一致性,我将使用Mac OS X的shell,但命令是工作在UNIX的shell下的,在Windows上可能有些许不同。
ANTLR的安装本身是下载一个最新的jar包,如antlr-4.0-complete.jar,并将其存储在计算机适当的地方。Jar包包含了运行ANTLR工具的所有依赖文件和编译执行由ANTLR生成的识别器所需要的运行时库。简而言之,ANTLR工具是把文法转化成程序以便用来识别句文法描述中的句子。例如,给定一个文法JSON,ANTLR工具通过ANTLR运行库的支持类来生成一个程序,以便识别JSON的输入。
Jar包里还包含两个支持库:一个复杂的树布局库和StringTemplate(一个用于生成代码和其他结构化文本的模板引擎)。在版本4,ANTLR还是用ANTLR V3写的,因此完整的jar包是含有ANTLR以前的版本的。
StringTemplate引擎
StringTemplate是一个基于Java的模板引擎库(已移植到C#、Python、Ruby和Scala),可以用于生成源代码、Web页面、电子邮件或任何其他格式的文本输出。不同于其他类似的模板引擎的显著特点是严格执行模型视图分离,尤其擅长多目标代码生成、多种网站风格管理以及网站多语言版本生成等。它已经应用到许多大型网站中,多年来一直致力于开发jguru.com。查看更多信息请访问网站页面
http://www.stringtemplate.org/about.html
你可以使用Web浏览器从ANTLR网站手动下载ANTLR,或者你可以使用命令行工具curl去获取:
$cd /usr/local/lib
$curl -Ohttp://www.antlr.org/download/antlr-4.0-complete.jar
在UNIX,/usr/local/lib是适合存放像ANTLR的jar包的路径。在Windows环境下,似乎没有一个标准的目录,那么你可以简单地把它储放在你的项目目录。大多数的开发环境,要你把jar包放置在你的语言应用项目的依赖项列表中。没有配置脚本或配置文件来改变,你只需要确保Java知道如何找到jar包,如设置环境变量。
因为这本书使用命令行,你需要经历设置类路径中典型的繁琐的过程环境变量。随着classpath的设置,Java可以找到ANTLR工具和运行时库。在UNIX系统,您可以执行以下的shell或将其添加到shell启动脚本(.bash_profile):
$ exportCLASSPATH=".:/usr/local/lib/antlr-4.0-complete.jar:$CLASSPATH"
在路径中特别注意那个”.”号,代表当前目录。如果没有的话,Java编译器和虚拟机就不能在当前目录中看到class文件。在这本书里你会经常看到从当前目录进行编译和测试工作。
现在你可以通过运行不带参数的ANTLR命令来检查下ANTLR是否安装正确。当然你也可以直接使用Java – jar 来操作或直接调用org.antlr.v4.tool类。
$java -jar /usr/local/lib/antlr-4.0-complete.jar# launchorg.antlr.v4.Tool
ANTLR Parser Generator Version4.0
-o ___ specify outputdirectory where all output is generated
-lib ___ specify location of.tokens files
...
$java org.antlr.v4.Tool # launch org.antlr.v4.Tool
ANTLR Parser Generator Version4.0
-o ___ specify outputdirectory where all output is generated
-lib ___ specify location of.tokens files
...
徒手敲出Java的命令通常比较痛苦,所以最好是起个别名或写成shell脚本。在本书中,我会为antlr4设置别名,您可以在UNIX定义:
$alias antlr4='java -jar/usr/local/lib/antlr-4.0-complete.jar'
或者,你可以把下面的脚本放到/usr/local/bin下(浏览电子书的读者可以单击“install/ antlr4”主题栏获取到文件):
install/antlr4
#!/bin/sh
java -cp "/usr/local/lib/antlr4-complete.jar:$CLASSPATH"org.antlr.v4.Tool $*
在Windows系统上你可以这样做(假定你把jar包放到C:\libraries目录下)
install/antlr4.bat
java -cpC:\libraries\antlr-4.0-complete.jar;%CLASSPATH% org.antlr.v4.Tool %*
无论哪种方式,你都可以这样使用 antlr4
$antlr4
ANTLR Parser Generator Version4.0
-o ___ specify outputdirectory where all output is generated
-lib ___ specify location of.tokens files
...
如果你看到这了,那你就准备快去试一试吧!
1.2 执行 ANTLR和测试识别器
这是一个简单的语法,识别helloparrt和HelloWorld这样的短语:
install/Hello.g4
grammarHello; // Define a grammar called Hello
r :'hello' ID ;// match keyword hello followed by an identifier
ID : [a-z]+ ;// match lower-case identifiers
WS : [ \t\r\n]+ -> skip ;// skip spaces, tabs, newlines, \r(Windows)
保持目录的整洁,让我们把语法文件hello.g4放置于自己的目录,例如/tmp/test。然后我们可以用ANTLR运行他并编译结果。
$cd /tmp/test
$# copy-n-pasteHello.g4 or download the file into /tmp/test
$antlr4 Hello.g4 # Generate parser and lexer using antlr4alias from before
$ls
Hello.g4 HelloLexer.javaHelloParser.java
Hello.tokens HelloLexer.tokens
HelloBaseListener.javaHelloListener.java
$ javac *.java # Compile ANTLR-generated code
运行hello.g4生成了在一个可执行的嵌入在helloParser.java和 helloLexer.java中的识别器,但我们没有一个主程序去触发语言识别。(我们将在第二章学习的词法解析器和语法分析器的概念。)这是一个项目的典型开始。在构建实际的应用之前你需要接触一些不同的语法。这将有利于你避免为每一个新语法的测试都要去创建一个主程序。
ANTLR在运行时库里提供灵活的测试工具称为TestRig。它可以显示大量信息,例如如何从文件或标准输入中识别匹配输入。TestRig用Java反射去调用编译的识别器。像以前一样,创造一个方便的别名或批处理文件,这是一个好主意。我要在书中称呼它为grun(当然你可以根据你的意愿给它取其他的名字)。
$ alias grun='javaorg.antlr.v4.runtime.misc.TestRig'
TestRig就像main方法一样,后跟语法的名字,和各种各样的选择,决定我们想要的输出。如果我们需要打印识别过程中创建的Tokens(Tokens是像关键词hello和标识符parrt那样词汇标记),那么需按如下启动grun:
➾$ grun Hello r -tokens # start the TestRig on grammar Hello at rule r
➾hello part # inputfor the recognizer that you type
➾EOF # type ctrl-D on Unix or Ctrl+Z on Windows
[@0,0:4='hello',<1>,1:0] # these three lines are output fromgrun
[@1,6:10='parrt',<2>,1:6]
[@2,12:11='<EOF>',<-1>,2:0]
当你在grun命令打一个换行符之后,电脑会耐心地等待你输入完hello part并敲上一个换行符。之后,您必须键入文件字符代表输入的结束;否则,程序会永远盯着你。一旦识别器都读完输入,TestRig就会打印出grun上面的每次使用的-tokens选项的标记列表。
每行输出代表一个单独的标记和显示我们关于token知道的一切。例如,[“1,6:10 = ‘parrt’,<2>,1:6]表明第二个token(索引从0开始),从字符位置6到10(从0开始),有文本parrt,是第二个标记(ID),位置是在第一行(行数从1开始),在第6个字符处(位置是从零开始计算,tabs也算作一个独立的字符)。
我们也可以一样容易用LISP样式文本表单(父子节点)打印解析树
➾$ grun Hello r -tree
➾hello parrt
➾EOF
(r hello parrt)
最简单的方式来看看一个语法识别输入的,不过,是的在解析树的可视化。运行带选项-gui的测试台程序,grunHello r -gui,产生下面的对话框:
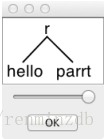
不带任何选项的命令行会打印一则帮助消息。
$grun
javaorg.antlr.v4.runtime.misc.TestRigGrammarNamestartRuleName
[-tokens][-tree][-gui][-psfile.ps][-encodingencodingname]
[-trace][-diagnostics][-SLL]
[input-filename(s)]
UsestartRuleName='tokens'ifGrammarNameisalexergrammar.
Omittinginput-filenamemakesrigreadfromstdin.
当我们在看这本书,我们将使用这些选项;这里把各个选项的概要描述下:
-tokens 打印出token流
-tree 用LISP表单打印出解析树
-gui 在对话框中可视化地展示解析树
-psfile.psgenerates视觉representation of the点树在后记and它在file.ps百叶窗。The点figures in this chapter是生成树与PS。
-encodingencodingnamespecifies 该试验台的输入文件编码,如果电流现场将不正确地读取输入。例如,我们需要此选项解析12.4节日本一个编码的XML文件,解析和词法分析XML,224页。
-trace 打印规则名和规则入口与出口的当前token
-diagnostics 在分析过程中的诊断消息转。这会产生消息只不寻常的情况下如模糊输入短语。-SLL 使用一个更快速但略弱解析能力的解析策略
现在我们安装了ANTLR并在一个简单的语法上尝尝鲜了,让我们退一步看看大纲,在下一章中学习一些重要的的术语。之后,我们会尝试一个简单的项目,识别并转换如{ 1,2,3}的整数列表。然后,我们会在第4章中看到一些有趣的例子,展示ANTLR的功能并说明一些应用的领域。

















 1380
1380

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









