







简介
2018年ECCV,和BAM为同一团队打造。论文连接:CBAM
Convolutional Block Attention Module.
CBAM是轻量级注意力机制模块,不仅参数量和计算量小,而且能即插即用。
目的
对中间特征图从空间、通道两个维度上进行特征重构,无缝衔接到CNN中,实现端到端的训练。
算法流程图
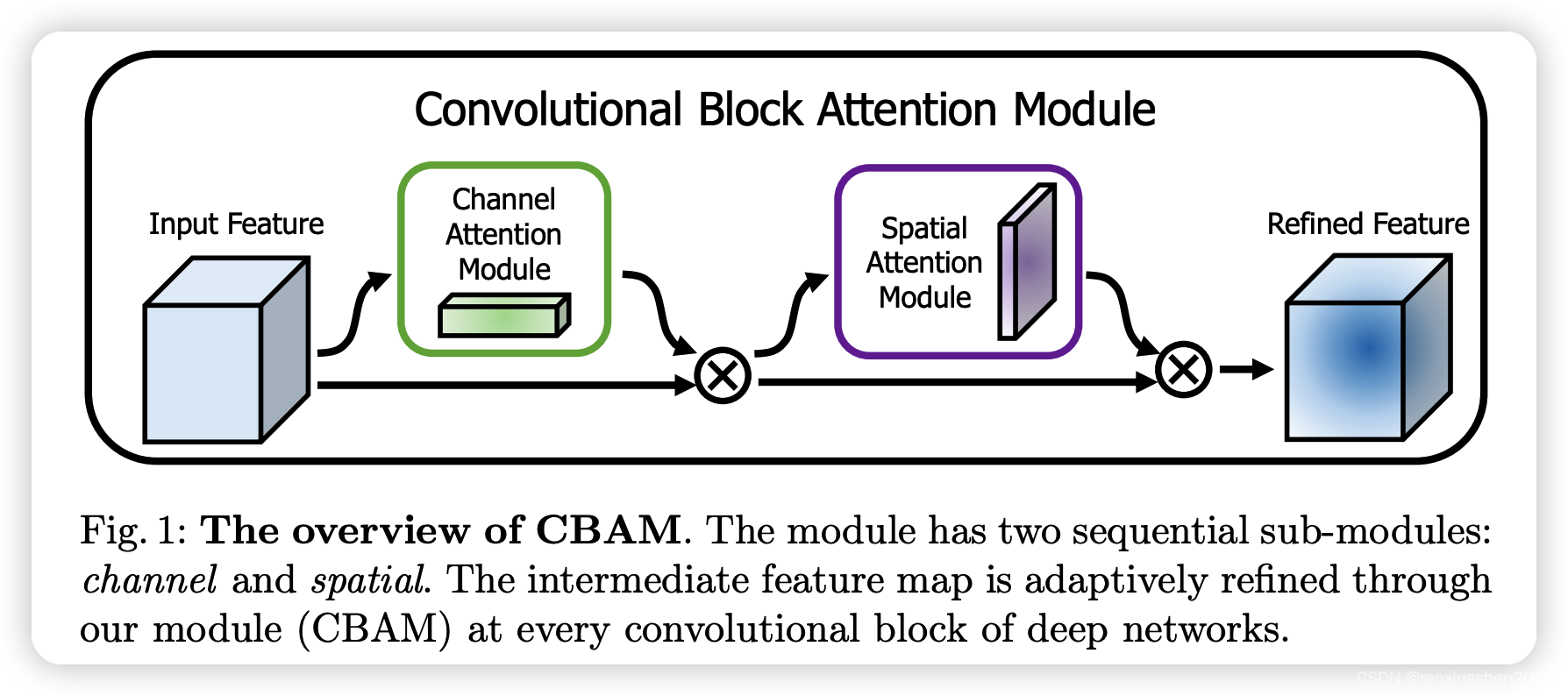
首先,利用通道注意力机制对输入特征图进行特征重构,然后利用空间注意力机制对重构后的特征图在进行重构,等到最后的特征图。
step1:CBAM通道注意力操作:
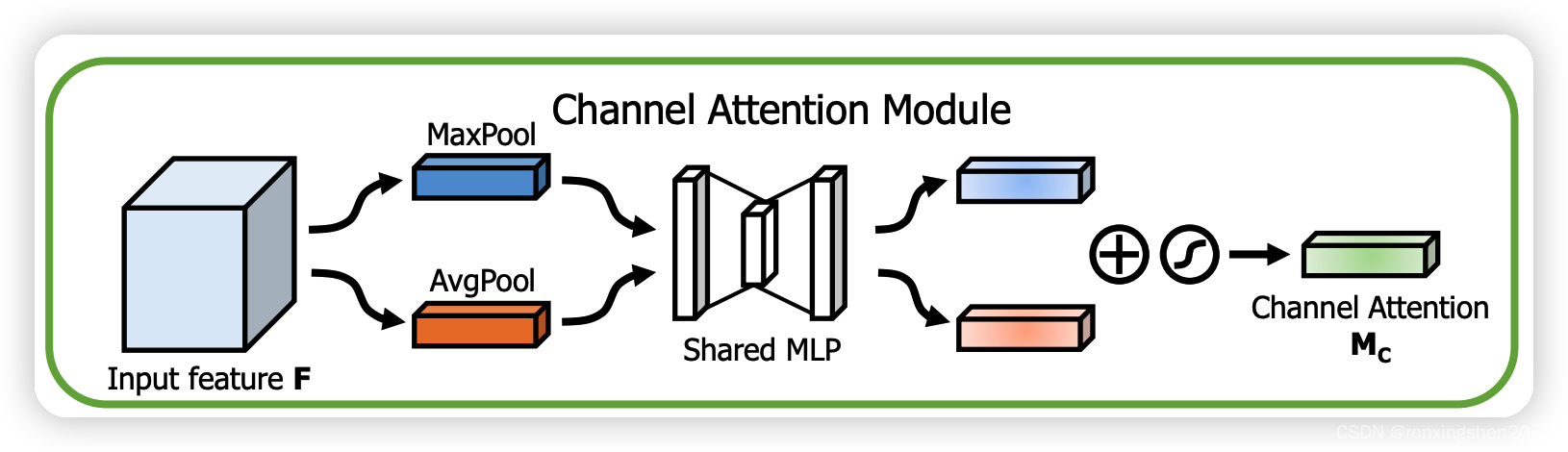
输入特征图
F
F
F经过全局平均池化和全局最大池化,分别得到一维特征向量;两个特征向量经过一个权值共享的MLP,然后再进行权值相加,最后记过sigmoid激活函数得到通道注意力机制
M
c
M_c
Mc。
详细计算公式如下:
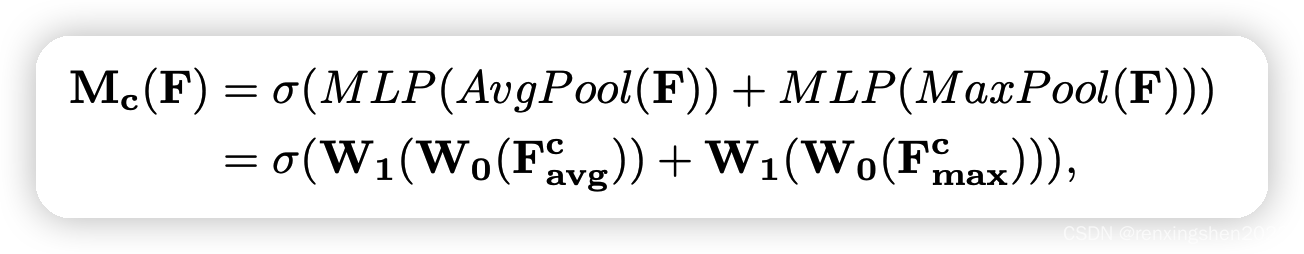
step2:CBAM空间注意力操作:
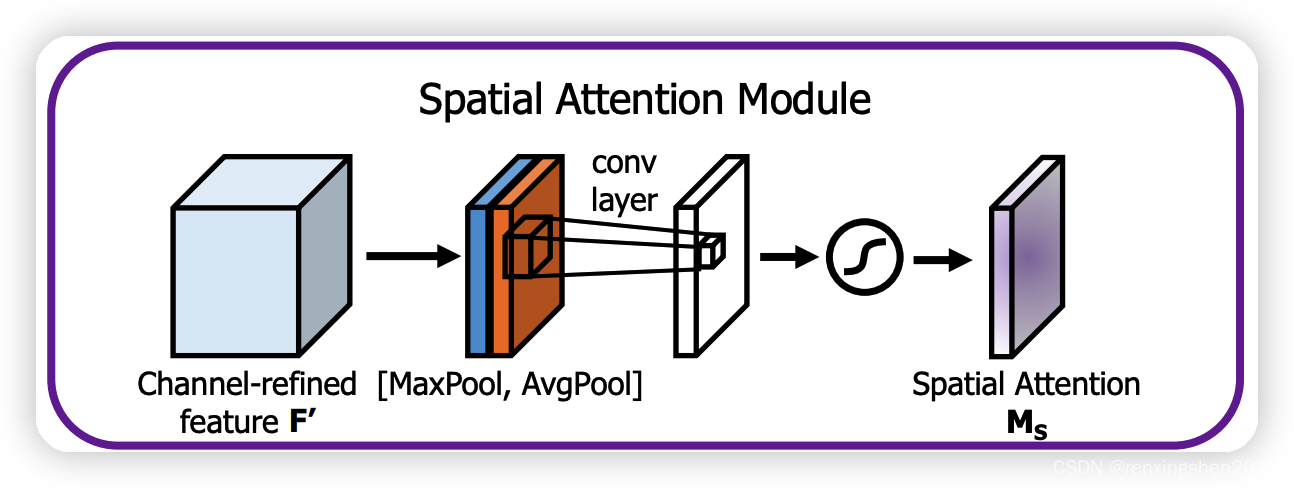
输入特征图
F
′
F'
F′在通道维度上经过全局平均池化和全局最大池化,分别得到size与
F
′
F'
F′相同,通道数为1的两个特征图;然后将两个特征图进行concat,再利用一个7*7的卷积核进行卷积操作,最后经过sigmoid激活函数得到空间注意力向量
M
s
M_s
Ms。
详细计算公式如下:
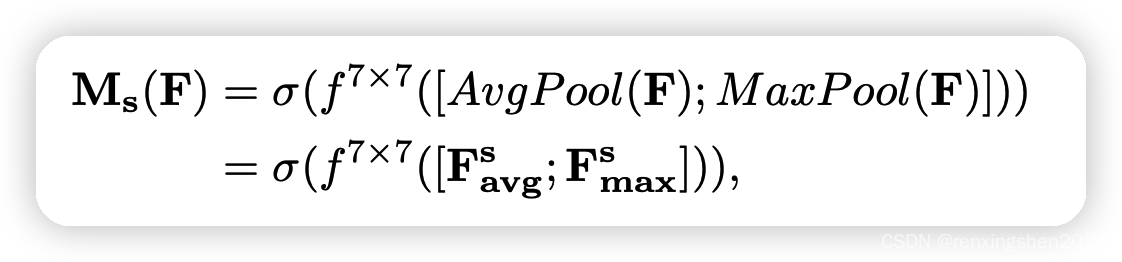
最后将
F
′
F'
F′与注意力向量
M
s
M_s
Ms相乘,得到最后的Refine Feature。
代码
代码粘贴自github。CBAM
地址:https://github.com/luuuyi/CBAM.PyTorch/blob/master/model/resnet_cbam.py
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc = nn.Sequential(nn.Conv2d(in_planes, in_planes // 16, 1, bias=False),
nn.ReLU(),
nn.Conv2d(in_planes // 16, in_planes, 1, bias=False))
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc(self.avg_pool(x))
max_out = self.fc(self.max_pool(x))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=kernel_size//2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
实验
作者进行了大量的实验进行验证:
通道注意力上消融实验:
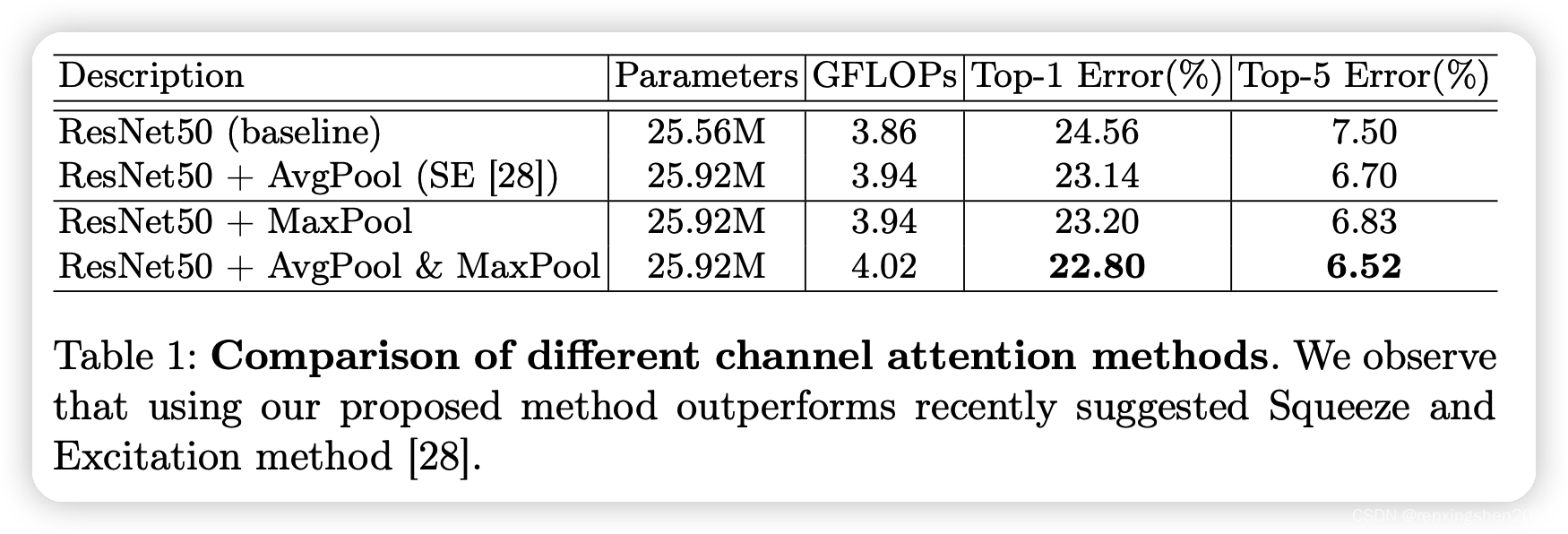
通过上述实验可以看出,通道注意力中同时使用平均池化金额最大池化,在参数量与浮点数运算量上无明显增加,但错误率更低。
空间注意力上消融实验:

通过上述实验可以看出,同时使用最大池化和平均池化,且卷积核尺寸为7*7时效果最好,且参数量与运算量差异性很小。
空间注意力、通道注意力组合方式实验:
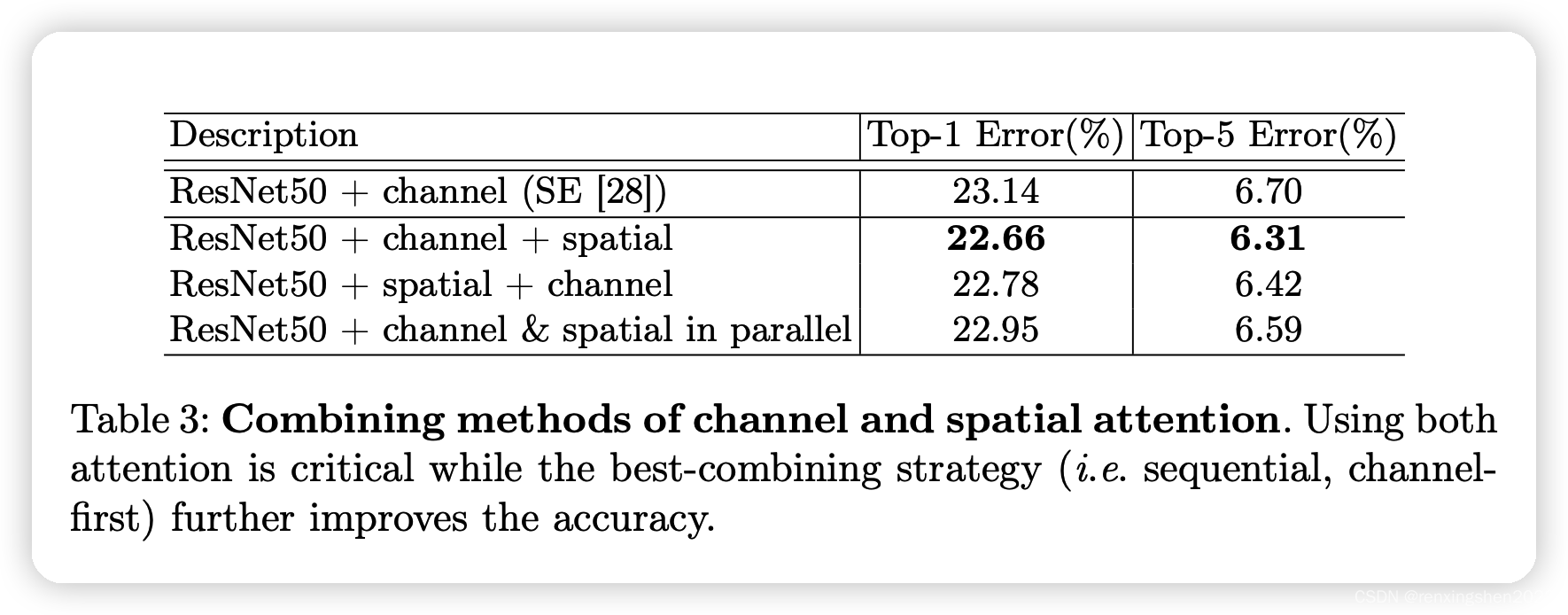
作者进行了多种不同的组合尝试,通过实验发现先通道再空间的串联方式是效果最好的。
此外
作者还进行了许多的对比实验,这里不过多阐述。
最后
简单进行记录,如有问题请大家指正。















 1677
1677











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











