






1.特征编码
数值特征不适合表示类别,因此一般使用独热编码;
在独热编码中,每个离散变量的可能取值被映射到一个高维空间中的一个点,在这个点上,对应于该取值的维度值为1,而其他维度的值为0。例如,如果有三个离散状态(如红色、绿色和黄色),则可以使用独热编码将它们表示为三个向量:(001)、(010)和(100)。这种编码方式适用于机器学习和深度学习中的分类变量,因为它将分类变量转换为适合算法处理的多维向量形式。独热编码的优点包括适用于大多数算法、避免特征之间的大小关系干扰模型训练,以及能够很好地处理分类变量。然而,它的缺点是在类别数量较多时可能导致稀疏矩阵问题,并且在某些应用中可能不是最优选择。
对于文本数据:1.将文本切分为字符序列;2.将文本切分为单词序列。
文本预处理的步骤包括:1.将文本作为字符串加载到内存中; 2.将字符串切分为词元(如单词和字符);3.建立一个字典,将拆分的词元映射到数字索引; 4.将文本转换为数字索引序列,方便模型操作。
2.循环神经网络(RNN)
对隐状态使用循环计算的神经网络称为循环神经网络。
当前时间步隐藏变量计算公式如下:
输出层的输出计算公式如下:
注意,即使在不同的时间步,循环神经网络也总是使用这些模型参数。 因此,循环神经网络的参数开销不会随着时间步的增加而增加。
RNN的模型如下:
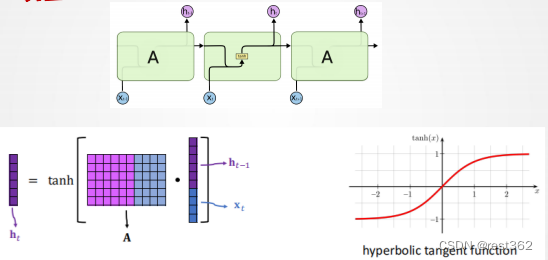
RNN代码实现:
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
# 构建具有256个隐藏单元的单隐藏层RNN
num_hiddens = 256
rnn_layer = nn.RNN(len(vocab), num_hiddens)
class RNNModel(nn.Module):
"""循环神经网络模型"""
def __init__(self, rnn_layer, vocab_size, **kwargs):
super(RNNModel, self).__init__(**kwargs)
self.rnn = rnn_layer
self.vocab_size = vocab_size
self.num_hiddens = self.rnn.hidden_size
# 如果RNN是双向的(之后将介绍),num_directions应该是2,否则应该是1
if not self.rnn.bidirectional:
self.num_directions = 1
self.linear = nn.Linear(self.num_hiddens, self.vocab_size)
else:
self.num_directions = 2
self.linear = nn.Linear(self.num_hiddens * 2, self.vocab_size)
def forward(self, inputs, state):
X = F.one_hot(inputs.T.long(), self.vocab_size)
X = X.to(torch.float32)
Y, state = self.rnn(X, state)
# 全连接层首先将Y的形状改为(时间步数*批量大小,隐藏单元数)
# 它的输出形状是(时间步数*批量大小,词表大小)。
output = self.linear(Y.reshape((-1, Y.shape[-1])))
return output, state
def begin_state(self, device, batch_size=1):
if not isinstance(self.rnn, nn.LSTM):
# nn.GRU以张量作为隐状态
return torch.zeros((self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens),
device=device)
else:
# nn.LSTM以元组作为隐状态
return (torch.zeros((
self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens), device=device),
torch.zeros((
self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens), device=device))
device = d2l.try_gpu()
net = RNNModel(rnn_layer, vocab_size=len(vocab))
net = net.to(device)
num_epochs, lr = 500, 1
d2l.train_ch8(net, train_iter, vocab, lr, num_epochs, device)3.门控循环单元(GRU)
门控循环单元有专门的机制来确定应该何时更新隐状态, 以及应该何时重置隐状态。例如某一个词元的影响至关重要,加入GRU可以在不给该词元指定一个非常大的梯度的情况下存储重要的信息。或者,加入GRU还可以跳过某些词元。
GRU的结构如下:
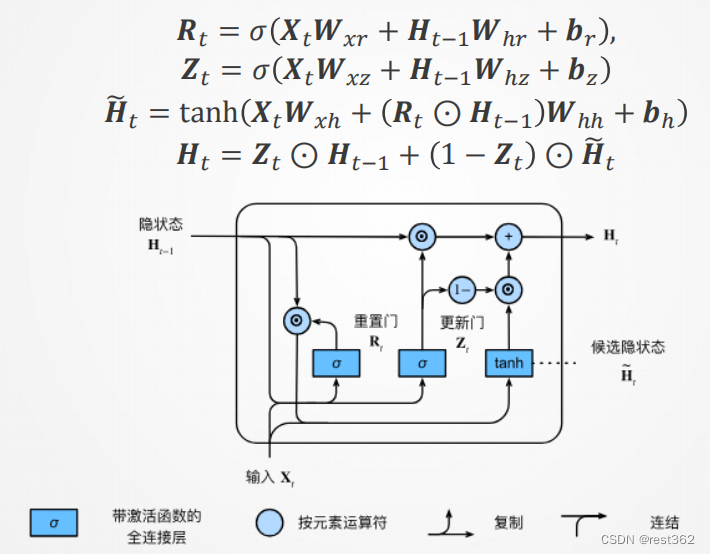
代码实现GRU模型:
gru_layer = nn.GRU(num_inputs, num_hiddens)4.长短期记忆网络(LSTM)
长短期记忆网络引入了记忆元。记忆元的目的是用于记录附加的信息。,为了控制记忆元,我们需要许多门。
相比较RNN,LSTM在训练上的表现更好。
LSTM的代码实现:
lstm_layer = nn.LSTM(num_inputs, num_hiddens)5.生成对抗网络(GAN)
生成对抗网络(GAN)的初始原理十分容易理解,即构造两个神经网络,一个生成器,一个鉴别器,二者互相竞争训练,最后达到一种平衡(纳什平衡)。
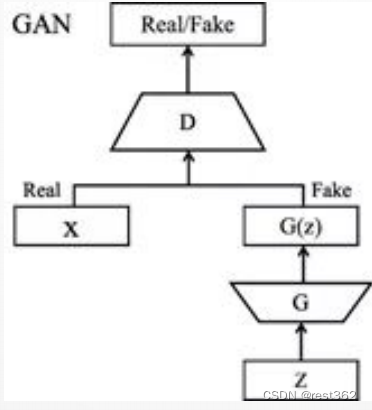
生成模型G捕捉样本数据的分布,用服从某一分布(均匀分布,高斯分布等)的噪声 z 生成一个类似真实训练数据的样本,追求效果是越像真实样本越好。
判别模型 D 是一个二分类器,估计一个样本来自于训练数据(而非生成数据)的概率,如果样本来自于真实的训练数据,D输出大概率,否则,D输出小概率。
6.NeRF
NeRF(Neural Radiance Fields)最早在2020年ECCV会议上发表,作为Best Paper,其将隐式表达推上了一个新的高度,仅用 2D 的 posed images 作为监督,即可表示复杂的三维场景。NeRF迅速发展起来,被应用到多个技术方向上,例如新视点合成、三维重建等等,并取得非常好的效果。
7.Transformer
Transformer是由编码器和解码器组成的。其整体架构图如下图所示。
从宏观角度来看,Transformer的编码器是由多个相同的层叠加而成的,每个层都有两个子层。第一个子层是多头自注意力(multi-head self-attention)汇聚;第二个子层是基于位置的前馈网络。具体来说,在计算编码器的自注意力时,查询、键和值都来自前一个编码器层的输出。
Transformer解码器也是由多个相同的层叠加而成的,并且层中使用了残差连接和层规范化。除了编码器中描述的两个子层之外,解码器还在这两个子层之间插入了第三个子层,称为编码器-解码器注意力(encoder-decoder attention)层。在编码器-解码器注意力中,查询来自前一个解码器层的输出,而键和值来自整个编码器的输出。在解码器自注意力中,查询、键和值都来自上一个解码器层的输出。但是,解码器中的每个位置只能考虑该位置之前的所有位置。这种掩蔽(masked)注意力保留了自回归(auto-regressive)属性,确保预测仅依赖于已生成的输出词元。
8.大语言模型
大语言模型(简写是LLM)是基于海量文本数据训练的深度学习模型。它不仅能够生成自然语言文本,还能深入理解文本含有,处理自然语言任务,如文本摘要、问答、翻译等。















 897
897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









