







全局与局部一致的图像补全
摘要:我们提出了一种新颖的图像完成方法,该方法生成的图像在局部和全局上都是一致的。通过使用全卷积神经网络(全卷积神经网络(Fully Convolutional Neural Network,FCNN)是一种特殊类型的神经网络,它主要用于处理图像数据。与传统的卷积神经网络(CNN)不同,全卷积神经网络在网络的所有层中都使用卷积层,而不是在末端使用全连接层。这样的设计使得全卷积神经网络能够接受任意尺寸的输入图像,并产生相应尺寸的输出,这对于图像分割、图像补全等任务特别有用。),我们能够完成任意分辨率图像的缺失区域填补,无论这些区域的形状如何。为了训练这个图像完成网络以保持一致性,我们使用全局和局部上下文鉴别器,这些鉴别器被训练用来区分真实图像与完成图像。全局鉴别器查看整个图像,以评估它作为一个整体是否连贯,而局部鉴别器只查看以完成区域为中心的小区域,以确保生成的贴片在局部上的一致性。然后训练图像完成网络欺骗这两个上下文鉴别器网络,这要求它生成的图像在整体连贯性以及细节上与真实图像无法区分。我们展示了我们的方法可以用来完成各种场景的图像。此外,与基于贴片的方法(如PatchMatch)相比,我们的方法可以生成图像中其他位置没有出现的片段,这使我们能够自然地完成具有熟悉且高度特定结构的对象的图像,如面孔。
关键词:图像补全,卷积神经网络。
1 引言
图像补全是一项技术,允许用替代内容填充目标区域。这使得移除不想要的对象或为基于图像的3D重建生成被遮挡的区域成为可能。虽然已经提出了许多图像补全方法,例如基于补丁的图像合成[Barnes等人,2009; Darabi等人,2012; Huang等人,2014; Simakov等人,2008; Wexler等人,2007],但这仍然是一个挑战性的问题,因为它经常需要对场景进行高层次的识别。不仅需要完成纹理图案的补全,还重要的是要理解正在补全的场景和对象的结构。基于这一观察,在这项工作中,我们考虑了场景的局部连续性和全局构成,在单一框架下进行图像补全。
我们的工作基于最近提出的Context Encoder(CE)方法[Pathak等人,2016],该方法采用了一个卷积神经网络(CNN),通过对抗性损失[Goodfellow等人,2014]进行训练。CE方法的动机是特征学习,并没有完全描述如何处理任意的修补遮罩,以及如何将该方法应用于高分辨率图像。我们提出的方法解决了这两个问题,并进一步提高了结果的视觉质量,正如我们将看到的。
我们利用全卷积网络作为我们方法的基础,并提出了一种新颖的架构,使得图像补全在局部和全局上都保持一致。我们的架构由三个网络组成:一个补全网络,一个全局上下文判别器,和一个局部上下文判别器。补全网络是全卷积的,用于完成图像补全,而全局和局部上下文判别器则是仅用于训练的辅助网络。这些判别器用于判断一个图像是否被一致地补全了。全局判别器采用整个图像作为输入,以识别场景的全局一致性,而局部判别器只查看完成区域周围的小区域,以判断更详细外观的质量。在每次训练迭代中,先更新判别器,使其正确区分真实和补全的训练图像。之后,更新补全网络,使其足够好地填补缺失区域,以欺骗上下文判别器网络。如图1所示,使用局部和全局上下文判别器对于获得逼真的图像补全至关重要。
我们评估并比较了我们的方法与现有方法在多种场景上的效果。我们还展示了在更具挑战性的特定任务上的结果,例如面部补全,我们的方法可以生成如眼睛、鼻子或嘴巴等对象的图像片段,以逼真地完成面部。我们通过用户研究评估了这种具有挑战性的面部补全的自然性,在这项研究中,我们的结果与真实面部之间的区别77%的时间内是无法辨识的。

图1. 我们方法的图像补全结果。遮罩区域以白色显示。我们的方法可以生成图像中不存在的新片段,例如完成面部所需的片段;这是基于补丁的方法无法实现的。图片致谢:Michael D Beckwith (CC0),Mon Mer (公共领域),davidgsteadman (公共领域),以及 Owen Lucas (公共领域)。
总结来说,在本文中我们提出了:
- 一种高性能的网络模型,能够完成任意缺失区域的补全,
- 一种用于图像补全的全局和局部一致的对抗性训练方法,
- 应用我们的方法于特定数据集以完成更具挑战性的图像补全的结果。
2 相关工作
图像补全领域已经提出了多种不同的方法。其中一个较为传统的方法是基于扩散的图像合成技术。这种技术通过传播目标孔洞周围的局部图像外观来填补它们。例如,传播可以基于等照线方向场[Ballester et al. 2001; Bertalmio et al. 2000],或基于局部特征直方图的全局图像统计[Levin et al. 2003]进行。然而,通常来说,基于扩散的方法只能填补小的或狭窄的孔洞,例如老照片中常见的划痕。
与基于扩散的技术相比,基于补丁的方法能够执行更复杂的图像补全,可以填补自然图像中的大孔洞。基于补丁的图像补全最初是为纹理合成提出的[Efros and Leung 1999; Efros and Freeman 2001],在该方法中,从源图像中采样纹理补丁,然后粘贴到目标图像中。这后来通过图像拼接[Kwatra et al. 2003]、基于能量优化的图像生成[Kwatra et al. 2005]等方法得到扩展。对于图像补全,提出了几种修改方法,如最优补丁搜索[Bertalmio et al. 2003; Criminisi et al. 2004; Drori et al. 2003]。特别是Wexler et al. [2007]和Simakov et al. [2008]提出了一种基于全局优化的方法,可以获得更一致的填充。这些技术后来通过一个名为PatchMatch的随机补丁搜索算法[Barnes et al. 2009, 2010]得到加速,该算法允许实时高级图像编辑。Darabi et al. [2012]通过将图像梯度整合到补丁间的距离度量中,展示了改进的图像补全方法。然而,这些方法依赖于低级特征,如补丁像素值的平方差之和,这对于填补复杂结构的孔洞并不有效。此外,它们无法生成源图像中未出现的新对象,与我们的方法不同。
为了解决生成结构化场景中大面积缺失区域的问题,一些方法采用了结构引导,这些结构通常是手动指定的,以保留重要的底层结构。这可以通过指定兴趣点[Drori et al. 2003]、线条或曲线[Barnes et al. 2009; Sun et al. 2005],以及透视扭曲[Pavić et al. 2006]来完成。也提出了自动估计场景结构的方法:利用张量投票算法在孔洞间平滑连接曲线[Jia and Tang 2003];利用基于结构的优先级进行补丁排序[Criminisi et al. 2004],基于瓦片的搜索空间限制[Kopf et al. 2012],补丁偏移的统计[He and Sun 2012],以及透视平面表面的规律性[Huang et al. 2014]。这些方法通过保留重要结构来提高图像补全的质量。然而,这样的引导基于特定场景类型的启发式约束,因此仅限于特定的结构。
大多数现有基于补丁的方法的明显限制是合成的纹理仅来自输入图像。当一个令人信服的补全需要在输入图像中未找到的纹理时,这就成了一个问题。Hays和Efros[2007]提出了一种使用大型图像数据库的图像补全方法。他们首先在数据库中搜索与输入最相似的图像,然后通过从匹配的图像中剪切相应区域并粘贴到孔洞中来完成图像。然而,这假设数据库中包含与输入图像相似的图像,这可能不是实际情况。这也被扩展到特定情况,即图像数据库中包含完全相同场景的图像[Whyte et al. 2009]。然而,假设数据库中包含完全相同的场景大大限制了与一般方法相比的适用性。
面部补全作为修复的一个特定应用也受到关注。Mohammed等[2009]使用面部数据集构建补丁库,并提出了一个全局和局部参数模型用于面部补全。Deng等[2011]使用基于光谱图的算法进行面部图像修复。然而,这些方法需要对齐的图像来学习补丁,并且不能推广到任意修复问题。
卷积神经网络(CNNs)也被用于图像补全。最初,基于CNN的图像修复方法仅限于非常小且薄的遮罩[Köhler et al. 2014; Ren et al. 2015; Xie et al. 2012]。类似的方法也被应用于MRI和PET图像,用于补全缺失数据[Li et al. 2014]。更近期的,与本工作同时,Yang et al. [2017]也提出了一种基于CNN的优化方法用于修复。然而,与我们的方法不同,这种方法由于需要对每张图像进行优化,因此计算时间增加。
我们在最近提出的Context Encoder (CE) [Pathak et al. 2016]的基础上进行了构建,该方法将基于CNN的修复扩展到了大遮罩,并提出了一个上下文编码器来通过修复学习特征,基于生成对抗网络(GAN) [Goodfellow et al. 2014]。GAN的原始目的是使用卷积神经网络训练生成模型。这些生成网络通过使用一个辅助网络(称为判别器)进行训练,该网络用来区分图像是由网络生成的还是真实的。生成网络被训练来欺骗判别网络,而判别网络则并行更新。通过结合使用均方误差(MSE)损失和GAN损失,Pathak et al. [2016]能够训练一个修复网络,完成128×128像素图像中心的64×64像素区域,避免了仅使用MSE损失时常见的模糊。我们通过使用全卷积网络来扩展他们的工作,以处理任意分辨率,并通过同时使用全局和局部判别器显著提高了视觉质量。
GAN的主要问题之一是学习过程中的不稳定性,这导致了大量的相关研究[Radford et al. 2016; Salimans et al. 2016]。我们通过不仅仅训练生成模型并调整学习过程以优先考虑稳定性,避免了这个问题。此外,我们针对图像补全问题特别优化了架构和训练过程。特别是,我们不使用单一的判别器,而是使用两个:一个全局判别器网络和一个局部判别器网络。正如我们展示的,这在获得语义上和局部上一致的图像补全结果中至关重要。
我们的方法能够克服现有方法的限制,实现多样化场景的逼真补全。不同方法的高层次比较可以在表1中看到。一方面,基于补丁的方法[Barnes et al. 2009, 2010; Darabi et al. 2012; Huang et al. 2014; Wexler et al. 2007]能够为任意图像大小和遮罩提供高质量的重构;然而,它们无法提供图像中未出现的新图像片段,也无法理解图像的高层次语义:它们仅在局部补丁层面上寻找相似性。另一方面,基于上下文编码器的方法[Pathak et al. 2016]能够生成新对象,但仅限于固定的低分辨率图像。此外,该方法可能缺乏局部一致性,因为未考虑补全区域与周围区域的连续性。我们的方法能够处理任意图像大小和遮罩,同时与图像保持一致并能够生成新对象。

表1. 补全方法的比较。基于补丁的方法,如[Barnes et al. 2009],无法生成新的纹理或对象,仅考虑局部相似性,而不考虑场景的语义。上下文编码器[Pathak et al. 2016]仅处理小尺寸固定大小的图像,且未能保持与周围区域的局部一致性。相比之下,我们的方法可以补全任何大小的图像,根据场景的局部和全局结构生成新的纹理和对象。
3 方法
3.1 卷积神经网络
我们的方法基于深度卷积神经网络,专门为图像补全任务训练。一个单一的补全网络用于图像补全。另外两个网络,全局和局部上下文判别器网络,用于训练这个网络以实现逼真的图像补全。在训练过程中,判别器网络被训练以确定一幅图像是否已经被补全,而补全网络则被训练以欺骗它们。只有通过联合训练这三个网络,补全网络才能实现多样化图像的逼真补全。这种方法的概述可以在图2中看到。
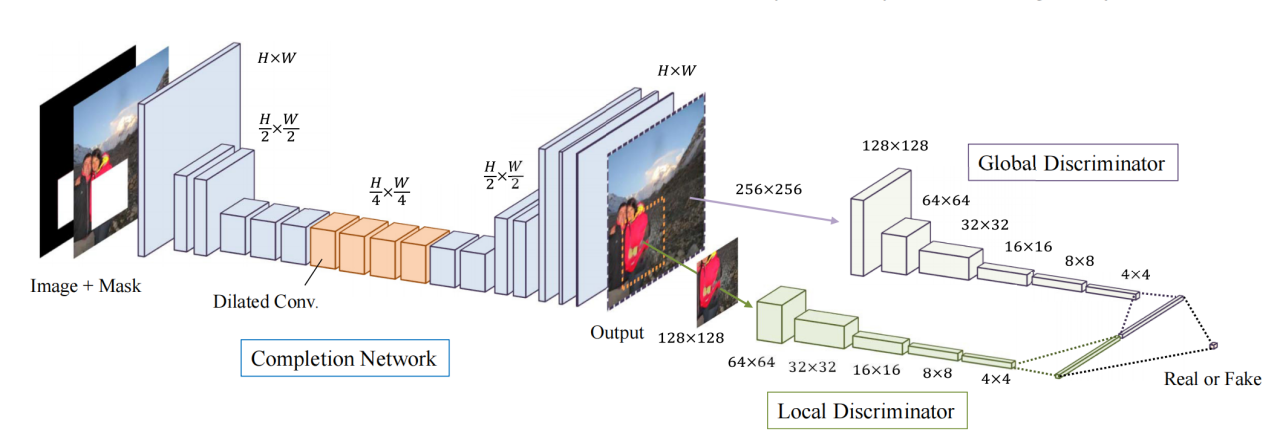
图2. 我们学习图像补全的架构概述。它包括一个补全网络和两个辅助的上下文判别器网络,这些判别器网络仅用于训练补全网络,在测试时不使用。全局判别器网络以整个图像作为输入,而局部判别器网络仅以补全区域周围的小区域作为输入。两个判别器网络都被训练以确定一个图像是真实的还是由补全网络完成的,同时补全网络则被训练以欺骗这两个判别器网络。
我们的方法基于卷积神经网络(Convolutional Neural Networks, CNNs)【Fukushima 1988; LeCun et al. 1989】。这些是一种特殊的神经网络变体,基于使用保持输入空间结构的卷积运算符,通常由图像组成。这些网络由多层组成,在这些层中,一组滤波器与输入图映射卷积,产生进一步用非线性激活函数处理的输出映射,最常用的是修正线性单元(ReLU),定义为σ(·)=max(·,0)【Nair和Hinton 2010】。
我们不仅使用标准的卷积层,还使用了一种称为扩张卷积层(扩张卷积(Dilated Convolution):与标准卷积不同,扩张卷积在遍历输入数据时引入了空间间隔。这通过在卷积核的应用中扩散(或“跳过”)一定数量的像素来实现。这种方法允许卷积核覆盖更广泛的区域,而不需要增加卷积核的大小或网络的参数数量。扩张卷积特别适合于捕捉更宽范围内的特征,同时保持网络深度和复杂度不变。)的变体【Yu和Koltu
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 232
232

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









