






深度学习中的优化算法:从梯度下降到Adam
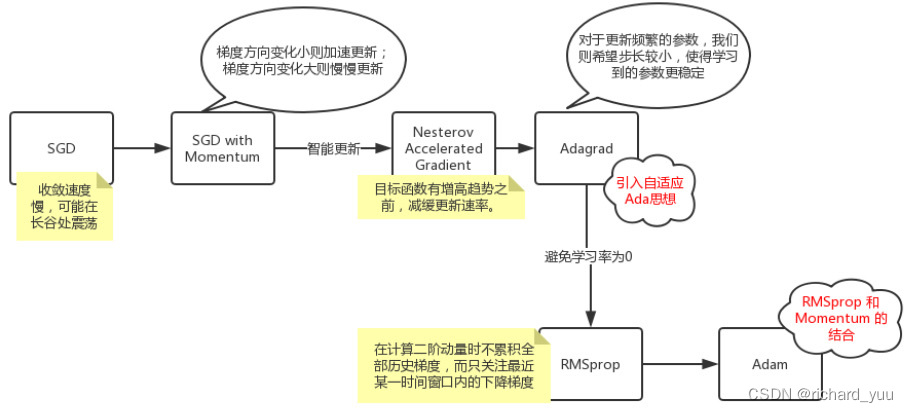
在深度学习的浪潮中,优化算法扮演着至关重要的角色。这些算法不仅决定了神经网络训练的速度,还直接影响了模型的最终性能。本文将带您领略优化算法的魅力,从基本的梯度下降法到高效的Adam算法,一探究竟。
一、优化算法概述
在深度学习中,优化算法的目标是最小化(或最大化)一个损失函数,该函数通常用于衡量模型预测与实际数据之间的差异。为了实现这一目标,我们需要调整神经网络的参数,使损失函数达到最小。这一过程的核心在于优化算法的选择。
优化算法大致可分为两类:一阶优化算法和二阶优化算法。一阶优化算法主要利用损失函数的一阶导数(梯度)来更新模型参数,而二阶优化算法则利用二阶导数(Hessian矩阵)来加速优化过程。由于二阶导数计算复杂且计算量大,因此在实际应用中,一阶优化算法更为常见。
二、一阶优化算法详解
梯度下降法(Gradient Descent)
梯度下降法是最基础的一阶优化算法。它通过计算损失函数关于参数的梯度,并沿着梯度的反方向更新参数,从而使损失函数不断减小。然而,梯度下降法有一个明显的缺点:每次更新都需要计算整个数据集的梯度,这在数据集较大时会导致计算量剧增。
下面是一个简单的梯度下降法的实现示例(使用C语言):
c
void gradient_descent(float *params, float *gradients, float learning_rate, int n) {
for (int i = 0; i < n; i++) {
params[i] -= learning_rate * gradients[i];
}
}
在这个示例中,params是模型参数,gradients是损失函数关于参数的梯度,learning_rate是学习率,n是参数的数量。通过循环遍历每个参数,我们将其减去学习率与对应梯度的乘积,从而实现参数的更新。
随机梯度下降法(Stochastic Gradient Descent)
为了克服梯度下降法的缺点,人们提出了随机梯度下降法。与梯度下降法不同,随机梯度下降法每次更新只使用一个样本的梯度。这样做可以大大加快训练速度,但也可能导致模型更新的不稳定。
随机梯度下降法的实现与梯度下降法类似,只不过在计算梯度时只使用一个样本。由于随机梯度下降法的随机性,模型的损失函数在训练过程中可能会出现较大的波动。然而,这种波动有时可以帮助模型找到更好的局部最优解。
三、动量法与自适应学习率算法
除了基本的梯度下降法和随机梯度下降法外,还有一些更高级的一阶优化算法,如动量法和自适应学习率算法。
动量法(Momentum)
动量法通过引入一个动量项来加速优化过程。在每次更新时,动量项会将前一次更新的方向考虑在内,从而加速模型在正确方向上的收敛速度。动量法可以有效地缓解随机梯度下降法中的波动问题。
自适应学习率算法(AdaGrad、RMSProp、Adam)
自适应学习率算法通过调整每个参数的学习率来加速优化过程。这些算法在训练过程中根据参数的历史梯度信息来动态调整学习率。其中,AdaGrad算法为每个参数分配一个不同的学习率,而RMSProp和Adam算法则进一步改进了AdaGrad算法的性能。
四、总结
优化算法是深度学习中的核心技术之一。从基本的梯度下降法到高效的Adam算法,这些算法为神经网络的训练提供了强大的支持。在实际应用中,我们可以根据问题的特点和需求选择合适的优化算法,以提高模型的训练速度和性能。随着深度学习技术的不断发展,相信未来会有更多优秀的优化算法涌现出来。















 6628
6628











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









