







 本文介绍了如何使用FPGA设计一个Sobel边缘检测加速器,详细阐述了算法原理、硬件实现、功能仿真和时序仿真过程,并通过与软件实现的对比,展示了硬件加速的优势。
本文介绍了如何使用FPGA设计一个Sobel边缘检测加速器,详细阐述了算法原理、硬件实现、功能仿真和时序仿真过程,并通过与软件实现的对比,展示了硬件加速的优势。
引言
图像视频处理等多媒体领域是FPGA应用的最主要的方面之一,边缘检测是图像处理和计算机视觉中的基本问题,所以也是最常用的,随着数据量的不断增加以及对实时性的要求,一般软件已经不能满足实际需要,这时,就需要专门的硬件来实现加速。本小节就实现一个简单的sobel边缘检测加速器,为了便于对比,我们还编写对应的软件算法。
1,基本思想与算法
Sobel检测法通过一个叫做卷积的过程来估计每个像素点每个方向上的导数值。把中心像素点和离它最近的八个像素点每个乘以一个系数后相加。该系数通常用一个 的卷积表(convolution mask)来表示。分别用于计算x和y方向导数值的Sobel卷积表 Gx和 Gy 如下图所示。
Gx:


我们把每个像素值分别乘以卷积表中对应的系数,再把相乘得到的九个数相加就得到了x方向和y方向的偏导数值 Dx和 Dy。然后,利用这两个偏导数值计算中心像素
点的导数。计算公式如下:
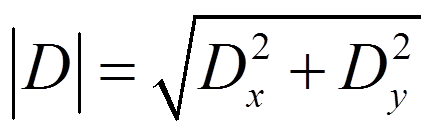
由于我们只想找到导数幅值的最大值和最小值,对上式作如下简化:
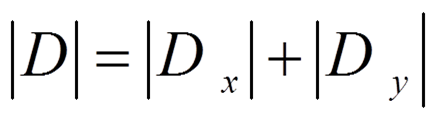
这样近似能够满足计算要求,因为开平方和平方函数都是单调的,实际计算幅度的最大值、最小值与近似以后计算的最大值、最小值发生在图像的同一个地方。并且,与计算平方和开平方相比,计算绝对值所用的硬件资源少得多。
我们需要重复地计算图像中每个像素位置的导数幅值。但是,注意到环绕图像边缘的像素点并没有一个完整的相邻像素组来计算偏导数和导数,所以我们需要对这些像素进行单独处理。最简单的方法就是把图像中边缘像素点的导数值值 |D|设置为0。这可以通过软件来完成。
我们用伪代码来表示该算法。令O[row][col] 表示原始图像的像素点,D[row][col]表示导数图像的像素点,row的范围从0到hight,col的范围从0到width。同时令Gx[i][j] 和 Gy[i][j] 表示卷积表,其中i 和 j 的范围从 -1 到 1.
for( row=1; row<=hight; row=row+1 )
{
for(col=1; col<=width; col=col+1)
{
sumx=0; sumy=0;
for( i = -1; i <= +1; i = i+1)
{
for (j = -1; j<= +1; j = j+1)
{
sumx = sumx + O[row+i][col+j] * Gx[i][j];
sumy = sumy + O[row+i][col+j] * Gx[i][j];
}
}
D[row][col] = abs(sumx) + abs(sumy)
}
}关于算法的具体细节,我已将PPT上传:
http://download.csdn.net/detail/rill_zhen/6371787
2,硬件实现
一旦明白了sobel的实现算法,我们就可以根据算法来划分模块了,本例中将sobel分成了:addr_gen,compute,machine,sobel_salve四个不同的子模块和sobel一个顶层模块。
需要说明的是,sobel加速器最终要挂载SoC的总线上,所以需要一个统一的接口总线,本例中采用wishbone总线,关于wishbone总线的内容,请参考:http://blog.csdn.net/rill_zhen/article/details/8659788
此外,由于sobel加速器只加速核心的数据处理部分,但是,对于一张完整的图片(例如bmp)还有其文件头,所以bmp的文件头的数据需要事先去掉,当sobel处理完后也需要再加上文件头之后才能用图片阅读器打开。所以我们需要编写相应的软件程序。
下面只给出verilog代码清单:
sobel.v
`timescale 10ns/10ns
module sobel (
//master slave share i/f
clk_i,
rst_i,
dat_i,
dat_o,
//master i/f
cyc_o,
stb_o,
we_o,
adr_o,
ack_i,
//slave i/f
cyc_i,
stb_i,
we_i,
adr_i,
ack_o,
//debug i/f
prev_row_load,
curr_row_load,
next_row_load,
current_state,
int_req//interrupt
);
input clk_i;
input rst_i;
input[31:0] dat_i;
output[31:0] dat_o;
output cyc_o;
output stb_o;
output we_o;
output[21:0] adr_o;
input ack_i;
input cyc_i;
input stb_i;
input we_i;
input[21:0] adr_i;
output ack_o;
output prev_row_load;
output curr_row_load;
output next_row_load;
output[4:0] current_state;
output int_req;
wire start;
wire ack_i;
wire cyc_o;
wire stb_o;
wire we_o;
wire O_base_ce;
wire D_base_ce;
wire done_set;
wire shift_en;
wire prev_row_load;
wire curr_row_load;
wire next_row_load;
wire O_offset_cnt_en;
wire D_offset_cnt_en;
wire offset_reset;
wire[31:0] result_row;
wire[31:0] dat_i;
wire[21:0] adr_o;
wire ack_o;
wire[31:0] dat_o ;
wire[4:0] current_state;
//module sentence
compute compute(
.rst_i(rst_i),
.clk_i(clk_i),
.dat_i(dat_i),
.shift_en(shift_en),
.prev_row_load(prev_row_load),
.curr_row_load(curr_row_load),
.next_row_load(next_row_load),
.result_row(result_row)
);
addr_gen addr_gen(
.clk_i(clk_i),
.dat_i(dat_i),
.O_base_ce(O_base_ce),
.D_base_ce(D_base_ce),
.O_offset_cnt_en(O_offset_cnt_en),
.D_offset_cnt_en(D_offset_cnt_en),
.offset_reset(offset_reset),
.prev_row_load(prev_row_load),
.curr_row_load(curr_row_load),
.next_row_load(next_row_load),
.adr_o(adr_o)
);
machine machine(
.clk_i(clk_i),
.rst_i(rst_i),
.ack_i(ack_i),
.start(start),
.offset_reset(offset_reset),
.O_offset_cnt_en(O_offset_cnt_en),
.D_offset_cnt_en(D_offset_cnt_en),
.prev_row_load(prev_row_load),
.curr_row_load(curr_row_load),
.next_row_load(next_row_load),
.shift_en(shift_en),
.cyc_o(cyc_o),
.we_o(we_o),
.stb_o(stb_o),
.current_state(current_state),
.done_set(done_set)
);
sobel_slave sobel_slave(
.clk_i(clk_i),
.rst_i(rst_i),
.dat_i(dat_i),
.dat_o(dat_o),
.cyc_i(cyc_i),
.stb_i(stb_i),
.we_i(we_i),
.adr_i(adr_i),
.ack_o(ack_o),
.start(start),
.O_base_ce(O_base_ce),
.D_base_ce(D_base_ce),
.int_req(int_req),
.done_set(done_set),
.result_row(result_row)
);
endmodule
addr_gen.v
`timescale 10ns/10ns
module addr_gen(
//input
clk_i,
dat_i,
O_base_ce,
D_base_ce,
O_offset_cnt_en,
D_offset_cnt_en,
offset_reset,
prev_row_load,
curr 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 281
281

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









