






index:.../System/Parallelization/optimize_aop.hdev
* This example program shows the difference of AOP (automatic
* operator parallelization) models that can be trained using
* optimize_aop. The speed-up of the sobel_amp operator for
* various image sizes is measured for different aop optimizations
* and the results are plotted. The example program is optimized
* for machines with more than 16 Processors.
*
dev_update_off ()
dev_close_window ()
*
WindowWidth := 500
WindowHeight := 500
dev_open_window (0, 0, WindowWidth, WindowHeight, 'black', WindowHandle1)
dev_set_line_width (2)
set_display_font (WindowHandle1, 14, 'mono', 'true', 'false')
*
* Initialization
get_system ('processor_num', NumCPUs)
read_image (Image, 'monkey')
*
ImageSize := [32,48,64,96,128,192,256,372,512]
这里搞了很多图像大小,以便后面直接zoom猴子照片来做运算
Threads := [1:NumCPUs]
Speedup := [1:max([2,NumCPUs / 2])]
*
Loops := 50
OperatorName := 'sobel_amp'
Method := 'sum_abs'
Mask := 3
Param := 'false'
InputControl := [Method,Mask]
*
Message := 'This program shows the effect of \'optimize_aop\''
Message[1] := 'using the example of \'sobel_amp\'.'
Message[2] := ' '
Message[3] := 'Therefore, \'optimize_aop\' is called'
Message[4] := 'with four different training modes:'
Message[5] := '- \'nil\' (no optimization)'
Message[6] := '- \'threshold\' (either use only one or all cores)'
Message[7] := '- \'linear\' (# cores proportional to image size)'
Message[8] := '- \'mlp\' (classifier-based).'
Message[9] := ' '
Message[10] := 'After that, the execution times of \'sobel_amp\''
Message[11] := 'are measured for different image sizes.'
disp_message (WindowHandle1, Message, 'window', 12, 12, 'white', 'false')
*
* Clear AOP information
disp_message (WindowHandle1, 'Measure \'nil\' ... ', 'window', 250, 12, 'yellow', 'false')
count_seconds (S1)
optimize_aop (OperatorName, 'byte', 'no_file', ['file_mode','system_mode'], ['nil','remove'])
help说是检测硬件做并行运算的潜能,总之它后面用的就是下面两个算子了
*
get_system ('parallelize_operators', Information)
get_aop_info (OperatorName, ['iconic_type','parameter:0'], ['byte',''], 'max_threads', Value)
得到了最大线程数的值max_threads
*
* Use no AOP model
measure_speedup_on_size (Image, InputControl, Loops, ImageSize, SpeedupNil, UsedThreadsNil)
这是一个自定义跳进去的函数,在里面对各种大小的图像做了运算并看运行效率
count_seconds (S2)
TimeNil := S2 - S1
disp_message (WindowHandle1, 'Measure \'nil\' ... done in ' + TimeNil$'.2' + ' s', 'window', 250, 12, 'green', 'false')
*
* Use threshold AOP model
disp_message (WindowHandle1, 'Measure \'threshold\' ...', 'window', 280, 12, 'yellow', 'false')
count_seconds (S1)
optimize_aop (OperatorName, 'byte', 'no_file', ['file_mode','model','parameters'], ['nil','threshold',Param])
measure_speedup_on_size (Image, InputControl, Loops, ImageSize, SpeedupThresh, UsedThreadsThresh)
count_seconds (S2)
TimeThresh := S2 - S1
disp_message (WindowHandle1, 'Measure \'threshold\' ... done in ' + TimeThresh$'.2' + ' s', 'window', 280, 12, 'green', 'false')
*
* Use linear AOP model
disp_message (WindowHandle1, 'Measure \'linear\' ...', 'window', 310, 12, 'yellow', 'false')
count_seconds (S1)
optimize_aop (OperatorName, 'byte', 'no_file', ['file_mode','model','parameters'], ['nil','linear',Param])
measure_speedup_on_size (Image, InputControl, Loops, ImageSize, SpeedupLinear, UsedThreadsLinear)
count_seconds (S2)
TimeLinear := S2 - S1
disp_message (WindowHandle1, 'Measure \'linear\' ... done in ' + TimeThresh$'.2' + ' s', 'window', 310, 12, 'green', 'false')
*
* Use MLP AOP model
disp_message (WindowHandle1, 'Measure \'mlp\' ...', 'window', 340, 12, 'yellow', 'false')
count_seconds (S1)
optimize_aop (OperatorName, 'byte', 'no_file', ['file_mode','model','parameters'], ['nil','mlp',Param])
measure_speedup_on_size (Image, InputControl, Loops, ImageSize, SpeedupMLP, UsedThreadsMLP)
count_seconds (S2)
TimeMLP := S2 - S1
disp_message (WindowHandle1, 'Measure \'mlp\' ... done in ' + TimeThresh$'.2' + ' s', 'window', 340, 12, 'green', 'false')
disp_continue_message (WindowHandle1, 'black', 'true')
stop ()
*
* Display results
dev_clear_window ()
dev_open_window (0, WindowWidth + 13, WindowWidth, WindowHeight, 'black', WindowHandle2)
dev_set_line_width (2)
set_display_font (WindowHandle2, 14, 'mono', 'true', 'false')
Legend := ['\'nil\'','\'threshold\'','\'linear\'','\'mlp\'']
Colors := ['red','orange','yellow','green']
*
* Plot results
这是一组画图的函数,用的时候可以拿来直接用
plot_tuple (WindowHandle1, ImageSize$'d', [SpeedupNil,SpeedupThresh,SpeedupLinear,SpeedupMLP], 'Image Size', ' Speedup factor', Colors, ['grid_y','ticks_y','start_y'], [1,1,0])
disp_message (WindowHandle1, Legend, 'window', 280, 300, Colors, 'false')
plot_tuple (WindowHandle2, ImageSize$'d', [UsedThreadsNil,UsedThreadsThresh,UsedThreadsLinear,UsedThreadsMLP], 'Image Size', '# Threads', Colors, ['grid_y','ticks_y','start_y'], [1,1,0])
disp_message (WindowHandle2, Legend, 'window', 280, 300, Colors, 'false')
*
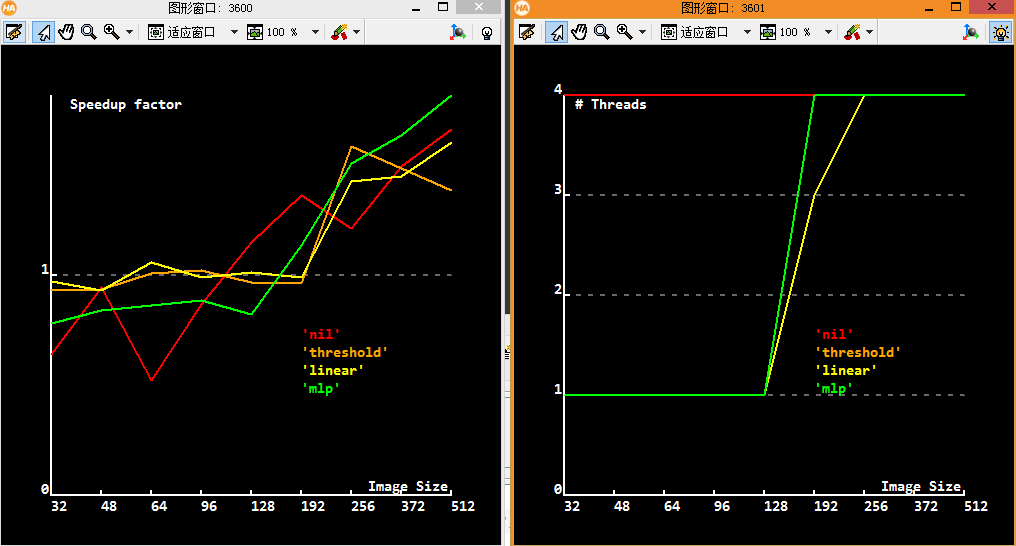
从图上看,图像大时用mlp合适,但是mlp也是高级插值方法。线程数都还是很智能的调节的。
做处理的猴子图片















 6239
6239











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









