






多年以前,我在开发一个C++的应用程序。我的同伴Jim Newkirk(当时的)过来告诉说,我们的一个公用函数运行得非常的缓慢。这个函数是用来转换二进制的树结构数据为普通文本,并存储到文件中的。(这是在XML出现之前,但概念类似于XML)
我审视了这个函数一会儿,发现了一个线性查找算法,于是毫无疑问的将这个线性查找算法替换为二分查找法(译注:binary search),然后就把这个函数交回给了Jim。Jim几小时后就回来了,问我是否有做过任何的改进,因为这个函数还是迟缓如初。
看来是我没找到关键,于是就一遍又一遍的研究了这个函数,然后发现并改进了一些其它很明显的算法问题,可是性能依然没有丝毫改进。函数依然缓慢,看到我对这个函数的无计可施,Jim也越来越沮丧。
最后,Jim终于找到了一个能够去分析这个函数性能的办法,就发现这个问题出自一个底层的叫strstream的C++库(译注1)。这个库函数随着文本数据的不断增加,它不停的一次又一次的申请内存块。这个函数单纯根据即将读入的文本数据大小来预先申请内存块,速度也迅速的随之以数量级的趋势降低。
很久以前,曾有一次我要写一个计算任意多边形面积的算法。我想出了一个不断的把这个任意多边形细分为三角形的主意。每次细分一个三角形,多边形就会减少一个顶点,而它的面积就可以由此累加起来。由于不得不处理很多不规则的形状,好久我才把这个功能写好。一、两天后,我就完成了这个厉害的算法,它能计算任意的多边形的面积。
几天后,我的一个同事过来找我,说:“我新画了多边形的一条边,可它花了45分钟才计算出面积。所以,我要是重新绘制这条线断或是调整它,面积都显示不出。”45分钟啊,很长的时间了,所以我就问她这个多边形有多少个顶点,她告诉我有超过1,000个的。
看了看算法,我认识到这个算法的复杂度是O(N^3)的(译注2),所以对于小多边形来说很快,但对于大型的来说速度就慢得无法忍受了。我一遍又一遍的思考着这个问题,但却找不到一个更好的算法。(现今我们只要用google搜索就好了,可那是现在而这是那时...)于是我们就把这个自动显示面积的功能去掉,然后告诉客户这太耗时了。
两周之后,纯属偶然机会, 我正翻阅一本关于prolog编程语言的书(一个可爱又另类的编程语言,我建议你也学习学习它),然后就发现了一个计算多边形面积的算法。它优雅,简单,而且是线性阶(译注2)的,我是从来都没写出过这么漂亮的算法。我用了几分钟时间就实现了它,哇!即使拖动多边形一个顶点绕着屏幕乱转,面积竟然也可以及时更新。
昨天晚上,我坐在一辆豪华轿车里,从O'Hare驶向我在芝加哥北部郊区的家。I-294公路正在施工,而我们凑好赶上交通阻塞。于是我拿出我的Macbook Pro,然后开始即兴的编写Ruby程序。为了好玩,我开始编写埃拉托色尼质数过滤算法(译注:Sieve of Eratosthenes)。我想让程序一跑起来就能看到Ruby有多快,所以就在程序中增加了benchmark模块来度量速度。它相当快!能在两秒钟内算出所有在百万以内的素数!对于一个解释型语言来说还不错。
我想知道这个算法的复杂度O(x)是什么样的。坐在车里不好算出来,于是我决定通过一些设定点采样的方法来测出它。我从100,000开始到5,000,000,每间隔100,000运行一次这个算法采样,然后把这些采样点绘在了一个图上。竟然是线性阶!
这个算法怎能是线性阶呢?它有一个嵌套的循环!难道不应该是复杂度类似于O(N^2),或者至少也应该是O(N log N)啊?这里就是代码,你自己来看看:
require 'benchmark'
def sievePerformance(n)
r = Benchmark.realtime() do
sieve = Array.new(n,true)
sieve[0..1] = [false,false]
2.upto(n) do |i|
if sieve[i]
(2*i).step(n,i) do |j|
sieve[j] = false
end
end
end
end
r
end
我的儿子Micah就坐在我旁边,他看了看然后说:“这个循环最多只应做到n平方根。”我惭愧的意识到这一定是导致线性阶的原因。这个循环本应该在它刚到n平方根的时候就结束了的,可却陷入了无用的线性迭代之中一直到n。
这个简单的改变应该不仅仅能在采样图表上展现出原本的曲线形状,算法的性能也应能提高不少。如下:
require 'benchmark'
def sievePerformance(n)
r = Benchmark.realtime() do
sieve = Array.new(n,true)
sieve[0..1] = [false,false]
2.upto(Integer(Math.sqrt(n)) do |i|
if sieve[i]
(2*i).step(n,i) do |j|
sieve[j] = false
end
end
end
end
r
我把这两幅采样图表拼接在了一起,如下: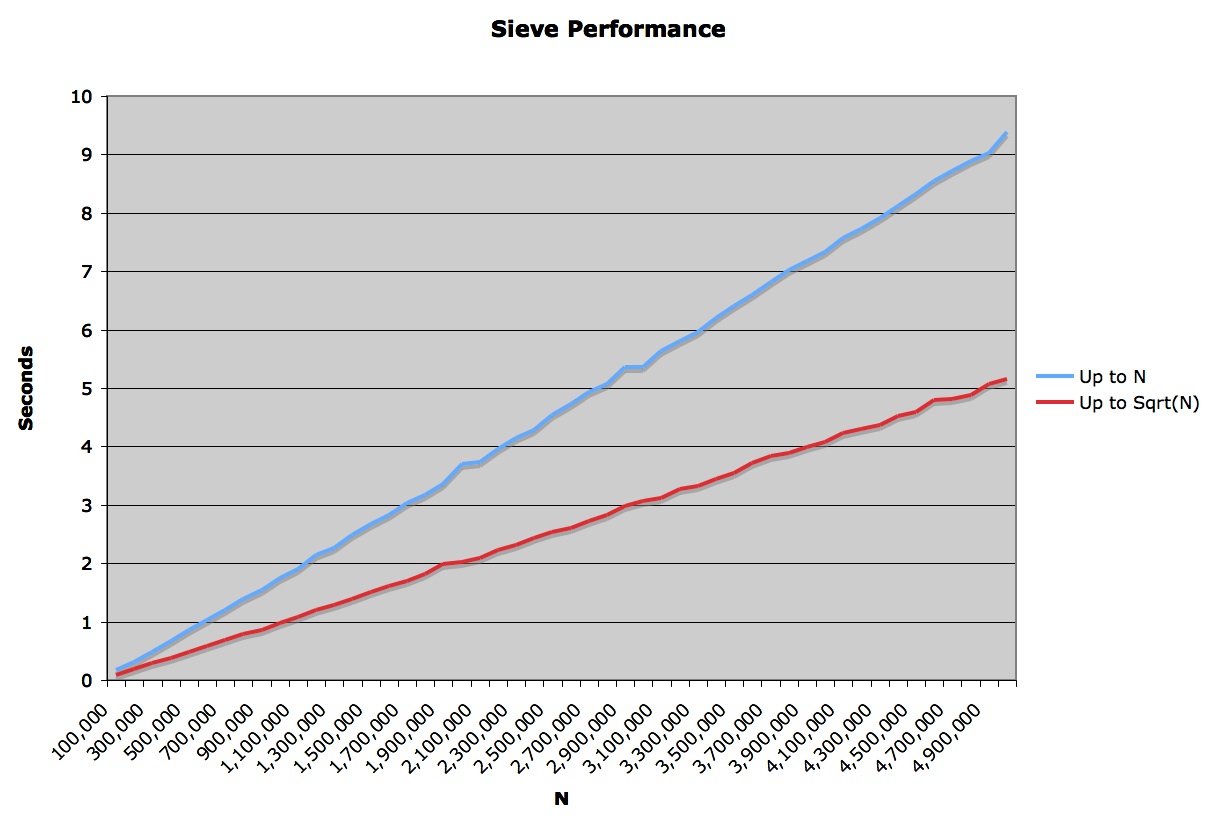
真令人失望。首先,在图上的sqrt(n)没有展现出曲线来;其次,sqrt(n)的性能仅仅是原先的两倍!一个函数的外循环上限在指数级别上变为的一半(即原来的平方根),可是速度的提升却怎能只有2倍?
随着我对这个算法理解的加深,我认识到外层循环的迭代次数的增加,内层循环所耗用时间会因为两个因素而减少。首先,步长增大了;其次,在筛选过程中出现了更多的'false'值,因此判断语句会更少频率的被执行。这两个导致时间耗用降低的因素一定是导致算法保持线性阶的某种平衡因素。
我不是计算机科学家,而且对鉴别这个算法到底是线性与否的数学问题我也不是非常感兴趣。谁能猜出当外部循环的范围缩小到原来上限值的平方根而性能却只有2倍增长的原因?谁能猜到算法本身竟然是线性阶的?!
六年前,当大家刚开始沉迷于XP的时候,Kent Beck(译注3)要在一组学生(大概30个左右)前示意一个算法,我就为他写了这个埃拉托色尼质数过滤算法的Java例程。我惊讶的看到他从函数中把n的平方根删掉,并替换成了n。他说“我不知道这是不是真的能让算法加快,不管如何,把上限设为n使得可读性更好。”于是,他删掉了这个特别的注释,那是我在平方根周围注释来解释为何不把上限设为n的聪明之处。
那时我眼珠子乱转而且还在一旁偷偷傻笑。我确信,如果n很大的时候,上限是n平方根会让算法的效率在数量级上大于n的,我还深信n每扩大一百倍,它所耗费的时间只会随之增加大概十倍。六年后(昨晚),我终于知道了程序的结果,而且知道了增幅是2倍线性阶的,而对此Kent一直都是对的。
译注:
1,strstream,标准C/C++的字符串流类,派生自iostream。因性能问题,C++标准委员会做了修补,用stringstream替换之,因此也不建议再使用strstream。
2,复杂度(本文指时间复杂度),以算法中基本运算的重复执行次数作为算法时间复杂度的时间量度,并以符号O(x)来表示。通常,时间复杂度由小到大分为几个等级,a)常量阶 O(c),b)对数阶 O(log2n),c)线性阶 O(n),d)多项式阶 O(nm)等。
3,Kent Beck,是软件开发方法学的泰斗、XP的创始人,长期致力于软件工程的理论研究和实践,并具有讲授XP的丰富经验。作为软件业内最富创造,哇和最有口碑的领导人之一,KentBeck极力推崇模式、极限编程和测试驱动开发。他现在加盟于ThreeRivers研究所,是多部畅销书如《Smalltalk Best PracticePatterns》、《解析极限编程——拥抱变化》和《规划极限编程》(和Martin Fowler合著)的作者,并且是超级畅销书《重构——改善既有代码的设计》(中国电力出版社出版中英文版)的特约撰稿人。
(原文链接网址:http://www.butunclebob.com/ArticleS.UncleBob.PerformanceTuning; Robert C. Martin的英文blog网址: http://www.butunclebob.com/ArticleS.UncleBob)
作者简介:Robert C. Martin是Object Mentor公司总裁,面向对象设计、模式、UML、敏捷方法学和极限编程领域内的资深顾问。他不仅是Jolt获奖图书《敏捷软件开发:原则、模式与实践》(中文版)(《敏捷软件开发》(英文影印版))的作者,还是畅销书Designing Object-Oriented C++ Applications Using the Booch Method的作者。Martin是Pattern Languages of Program Design 3和More C++ Gems的主编,并与James Newkirk合著了XP in Practice。他是国际程序员大会上著名的发言人,并在C++ Report杂志担任过4年的编辑。















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









