







1、TinyXML
引用网上的原话:TinyXML是目前非常流行的一款基于DOM模型的XML解析器,简单易用且小巧 玲珑,非常适合存储简单数据,配置文件,对象序列化等数据量不是很大的操作。支持对XML的读取和修改,不直接支持XPath,需要借助另一个相关的类库TinyXPath才可以支持XPath。
TinyXML源码是使用C++语言编写的,这对于C++应用来说是很好的XML操作工具了。TinyXML附带的文档中给出了它的类组织形式:
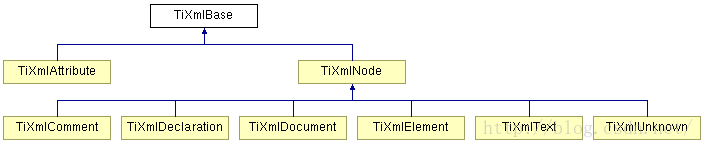
TiXmlDocument : XML文档类,它一般用于指示一个文档对象;
TiXmlDeclaration: XML标识类,也就是XML文件第一行中标注的相关信息;
TiXmlElement: XML节点类,这个类用来表示一个节点;
TiXmlText: XML节点类的文本信息类,标注了XML节点类的文本信息;
TiXmlComment: XML的注释信息类,用来标识XML文档类的注释信息;
上述的这些类全部组织在如下的几个文件中,在使用这个小巧的工具的时候只需要将这4个.cpp文件和2个.h添加到工程中,非常的方便。

2、使用TinyXML写文件
XML的文件结构一般都如下面这段内容所示,第一行表明的是xml的文件版本,编码方式等重要信息。在我们自己写XML的时候可以不写着一行,但是为了通用性,以及后续的可修改性,最好要加上这些必要的信息,毕竟有些XML操作工具对这些是有严格限定的。
<Persons> abc </Persons> 这一行信息中<></>标记的是一个XML的结点,结点的名称就是在<>中的内容,abc就是这个结点的一个属性了。XML的详细文件结构可以看XML的文件结构说明。
<?xml version="1.0" encoding="UTF-8" ?>
<Persons>
<Person Number="1">
<name>sunsusn</name>
<price>22.5</price>
</Person>
</Persons>
创建一个工程,然后使用上面介绍过的相关类来创建一个XML文件,并且写入相关信息到XML文档中。
#include <iostream>
#include <string>
#include "xml/tinyxml.h"
#include "xml/tinystr.h"
using namespace std;
int main()
{
string fileName = "test.xml";
TiXmlDocument *doc = new TiXmlDocument(); //创建xml文档对象
TiXmlDeclaration *pDeclaration = new TiXmlDeclaration("1.0","UTF-8","");
doc->LinkEndChild(pDeclaration);
TiXmlElement *RootLv1 = new TiXmlElement("Numbers"); //创建一个根结点
doc->LinkEndChild(RootLv1); //链接到文档对象下
TiXmlElement *RootLv2 = new TiXmlElement("number"); //创建一个节点
RootLv1->LinkEndChild(RootLv2); //链接到节点RootLv1下
RootLv2->SetAttribute("Number", "1"); //设置节点RootLv2属性
TiXmlElement *Name = new TiXmlElement("name"); //创建节点
RootLv2->LinkEndChild(Name); //链接节点到RootLv2下
TiXmlElement *Price = new TiXmlElement("price"); //创建节点
RootLv2->LinkEndChild(Price); //链接节点到RootLv2下
TiXmlText *NameText = new TiXmlText("Robin"); //创建XmlText文本
Name->LinkEndChild(NameText); //链接到Name下
TiXmlText *PriceText = new TiXmlText("22.5"); //创建XmlText
Price->LinkEndChild(PriceText); //链接到Price下
doc->SaveFile("c:\\test.xml"); //保存到文件
return 0;
}
运行程序就可以在C盘根目录下找到那个命名为test.xml的XML文件了。使用记事本或者类似的文本工具就可以查看文件中的内容,如果写入成果文本的内容应该是和上面说给的一段XML内容一致了。
3、使用TinyXML读XML文件
有了上面写XML的经验,读XML文件相比更加的容易了。读XML文件相比写XML文件可能用的场合要更多一些。使用TinyXML读XML可以分为以下几个步骤:
1、创建一个TiXmlDocument文档对象;
2、加载XML文件;
3、获取文件根节点;
4、从根节点开始遍历读取。
直接使用一个比较复杂的XML文件来作为案例:
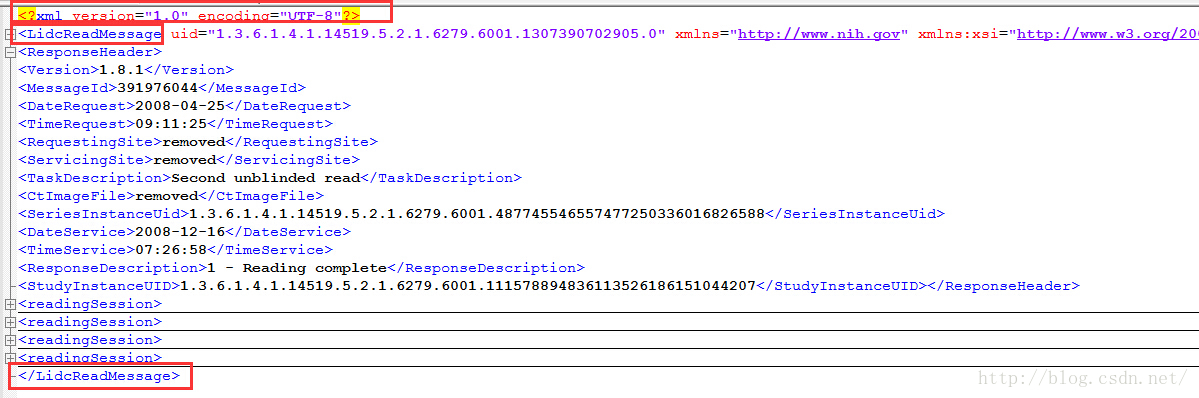
XML文件比较长不直接贴出,先从结构上来分析一下要读的这个XML文件。第一行是XML标识信息。然后上图中表红框的一对节点就是根节点了,读取的时候找到根节点,然后再去读取根节点下的子节点,依次进行下去就可以读取到我们想要的信息了。这里我想要的信息时存在于readingsession节点下的。
readingseassion节点下的内容前部分可以预览一下,文件太长不便于贴出。
<readingSession>
<annotationVersion>3.12</annotationVersion>
<servicingRadiologistID>302474490</servicingRadiologistID>
<unblindedReadNodule>
<noduleID>Nodule 001</noduleID>
<characteristics>
<subtlety>5</subtlety>
<internalStructure>1</internalStructure>
<calcification>6</calcification>
<sphericity>3</sphericity>
<margin>3</margin>
<lobulation>3</lobulation>
<spiculation>5</spiculation>
<texture>5</texture>
<malignancy>5</malignancy>
</characteristics>
<roi>
<imageZposition>-93.250000</imageZposition>
<imageSOP_UID>1.3.6.1.4.1.14519.5.2.1.6279.6001.190268484503749714760575440541</imageSOP_UID>
<inclusion>TRUE</inclusion>
<edgeMap>
<xCoord>311</xCoord>
<yCoord>226</yCoord>
</edgeMap>
<edgeMap>
<xCoord>310</xCoord>
<yCoord>225</yCoord>
</edgeMap>
<edgeMap>
<xCoord>309</xCoord>
<yCoord>226</yCoord>
</edgeMap>下面就可以写代码了,按照我们之前分析的读取顺序:
TiXmlDocument doc(pFile); //pFile表示文件的路径 //创建读取XML临时对象
BOOL loadOK = doc.LoadFile(); //加载XML文件
if (!loadOK) //加载失败弹出提示并退出该函数
{
MessageBox(NULL, "xml文件读取失败!", "RBDcm提示您", MB_OK);
return FALSE;
}
TiXmlElement* root = doc.RootElement(); //XML的根节点
for (TiXmlNode* SpecialistItem = root->FirstChild("readingSession"); //对readingSession节点进行循环
SpecialistItem; SpecialistItem = SpecialistItem->NextSibling("readingSession"))
{
TiXmlNode* unblindedReadNodule = SpecialistItem->FirstChild("unblindedReadNodule");
TiXmlNode* nonNodule = SpecialistItem->FirstChild("nonNodule");
while (unblindedReadNodule) //节点unblindedReadNodule循环
{
TiXmlNode* roi = unblindedReadNodule->FirstChild("roi");
while (roi) //节点roi循环
{
SingleImgNodule single;
TiXmlNode* imageZposition = roi->FirstChild("imageZposition"); //imageZposition信息
const char* Zposition = imageZposition->ToElement()->GetText();
single.ZPosition = CType::pChar2Double(Zposition);
TiXmlNode* edgeMap = roi->FirstChild("edgeMap");
while (edgeMap) //edgeMap节点循环
{
TiXmlNode* xCoord = edgeMap->FirstChild("xCoord");
TiXmlNode* yCoord = edgeMap->FirstChild("yCoord");
const char* szX = xCoord->ToElement()->GetText();
const char* szY = yCoord->ToElement()->GetText();
NodulePoint pt;
pt.nt = ISNODULE;
pt.x = CType::pChar2int(szX);
pt.y = CType::pChar2int(szY);
single.vcNodulePoint.push_back(pt);
edgeMap = edgeMap->NextSibling("edgeMap");
}
m_vSingle.push_back(single);
roi = roi->NextSibling("roi");
}
unblindedReadNodule = unblindedReadNodule->NextSibling("unblindedReadNodule");
}上述代码来自于项目中的一小段源码,中间的有些量都是其它地方定义的,不必纠结于此,重要的是这个读取的流程。















 628
628











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











