







介绍
本篇实现了使用
logistic
回归进行真假币的判断,有关
logistic regression
的详细讲解见这里。本篇使用随机梯度下降算法
(SGD)
来求解
logistic regression
,使用的数据集为钞票数据集。该数据集有
1732
个样本, 每一个样本有
4
个特征。
本篇使用
26
个样本作为测试集,其余全部用作训练集来训练模型。
代码实现
1. 加载需要的模块
import numpy as np
import pandas as pd
from numpy import *
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap2. 使用 pandas 加载数据
def load_BankNodeData():
'''
加载钞票数据集的训练集
:return: 训练集的特征,训练集的label
'''
df = pd.read_csv(r'./data/train.txt', header=None)
# trainSet = np.array(df.loc[:][[0, 1, 2, 3]].values)
trainSet = np.array(df.loc[:][[0, 1, 2, 3]]) # trainSet.dtype = float64
print('train set: \n', trainSet)
labels = df.loc[:][4].values # labels.dtype = int64
labels = np.where(labels == 1, 1, -1)
print('lebel values: \n', labels)
return trainSet, labels3. 使用随机梯度下降算法求解 logistic regression
def logisticRegression_SGD(trainSet, labels, eta = 0.01, max_iter = 5000):
'''
:param trainSet: 训练集
:param labels: 训练集的y值
:param eta: 学习率,步长
:param iterTime: 最大迭代次数
:return: 权重;权重更新记录,用户观测是否收敛
'''
sampleSize = len(labels)
featureSize = len(trainSet[0]) + 1
weights = random.rand(featureSize) # 权重
weightsRecord = [[x] for x in weights] # 权重更新记录
print('initial weights: ', weights)
count = 0
while(count < max_iter):
sample = random.randint(0, sampleSize - 1)
update = logisticFunction(-labels[sample] * (np.dot(weights[1:], trainSet[sample]) + weights[0]))
weights[1:] = weights[1:] - eta * update * (-labels[sample] * trainSet[sample])
weights[0] = weights[0] - eta * update * (-labels[sample])
count += 1
if count % 500 == 0:
for i in range(featureSize):
weightsRecord[i].append(weights[i])
fout = open(r'./data/weightRecord.txt', 'w', encoding='utf-8')
for i in range(featureSize):
fout.write(','.join([str(i) for i in weightsRecord[i]]) + '\n')
fout.close()
return weights, weightsRecord
def logisticFunction(inputV):
'''
logistic函数
:param inputV: logistic函数输入
:return: logistic函数值
'''
return 1.0 / (1.0 + np.exp(-inputV))4. 可视化权重的变化趋势,观察其是否收敛
一个判断优化算法优劣的可靠方法就是看它是否收敛
def plotWeightTrend():
'''
:return:
'''
df = pd.read_csv(r'./data/weightRecord.txt', header=None)
featureSize = df.values.shape[0]
iter_n = df.values.shape[1]
for i in range(featureSize):
plt.plot(range(iter_n), df.loc[i], lw = 1.5, label = 'w_' + str(i))
plt.legend(loc = 'upper left')
plt.show()
5. 计算模型在测试集上的表现
def preformence_BankNodeData(weights):
'''
:param weights: 模型的权重
:return: None
'''
df = pd.read_csv(r'./data/test.txt', header=None)
testSet = df.loc[:][[0, 1, 2, 3]].values # shape = 26, 4, dtype = float64
label = df.loc[:][4].values
pre = np.dot(testSet, weights[1:]) + weights[0] # pre.shape = (26, ), dtype = float64
error = 0
for i in range(pre.__len__()):
print('true labels\t:',label[i], 'predict\t:', np.where(logisticFunction(pre[i]) > 0.5, 1, 0), '(', logisticFunction(pre[i]), ')')
error += np.where((np.where(logisticFunction(pre[i]) > 0.5, 1, 0)) != label[i], 1, 0)
print('\033[1;32;40m error is', error / len(label), '\033[0m')
6. 主函数,使用logistic regression辨别真假钞票
if __name__ == '__main__':
trainSet, labels = load_BankNodeData()
weights, weights_record = logisticRegression_SGD(trainSet, labels, 0.1, 1500000)
plotWeightTrend()
preformence_BankNodeData(weights)运行程序会得到权重的变化情况如下:

通过下图可以看到算法在测试集上的error为
0
,即准确的判断对了所有的真假币。

logistic regression 二分类实例
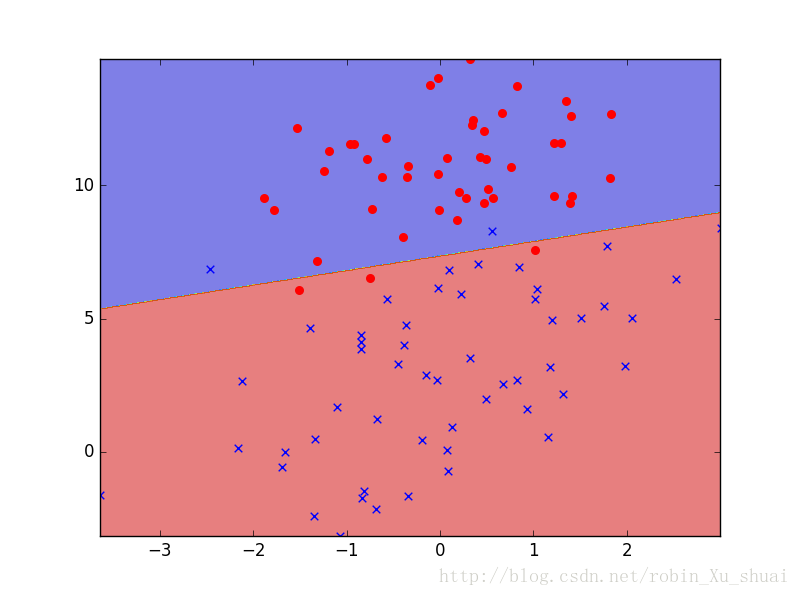
为了看到 logistic regression 分类的实际的效果,这里给出样本中只有两个特征的例子,这样便于我们进行可视化观察最后得到的分类边界。
原始的数据是长这样的:

我们的目的便是使用 logistic regression 来帮我们找到一条分类边界,可以很好的划分两个不同的类别的数据点。具体的程序实现如下:
def load_data():
'''
加载数据
:return: 返回训练集和相应的y值
'''
df = pd.read_table(r'./data/testSet.txt', header=None)
trainSet = df.loc[:][[0, 1]].values #trainSet.dtype = float64
labels = df.loc[:][2] # labels.dtype = int64
labels = np.where(labels == 1, 1, -1)
return trainSet, labels
def fit():
'''
使用SGD算法进行模型的训练,并绘制权重更新趋势和分界面
:return:
'''
trainSet, labels = load_data()
weights, weightRecord = logisticRegression_SGD(trainSet, labels, 0.1, 100000)
print('\033[1;32;40m weights: ', weights, '\033[0m')
plotWeightTrend() # 绘制权重的更新趋势
plot_decision_regions(trainSet, labels, weights) # 绘制分界面
def plot_decision_regions(X, y, weights, resolution = 0.02):
'''
绘制分类的边界
:param X:
:param y:
:param weights: 训练得到的模型的参数
:param resolution: 固定参数,绘图使用
:return:
'''
colors = ['red', 'blue', 'black']
markers = ['o', 'x', '+']
# colorMap = ListedColormap(colors[:2])
x1_min, x1_max = X[:, 0].min(), X[:, 0].max()
x2_min, x2_max = X[:, 1].min(), X[:, 1].max()
X1, X2 = np.meshgrid(np.arange(x1_min, x1_max, resolution), np.arange(x2_min, x2_max, resolution))
Z = np.array([X1.ravel(), X2.ravel()]).T
Z = predict(weights, Z)
Z = Z.reshape(X1.shape)
plt.contourf(X1, X2, Z, alpha = 0.5)
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
y = np.array(y)
for i, ylabel in enumerate(np.unique(y)):
plt.scatter(x = X[y == ylabel, 0], y = X[y == ylabel, 1], marker = markers[i], color = colors[i], s = 30)
plt.show()
def predict(weights, X):
'''
:param weights: 权重
:param X: 特征
:return: 类别
'''
return np.where(logisticFunction(np.dot(X, array(weights[1:]).T) + weights[0]) > 0.5, 1, 0)
if __name__ == '__main__':
fit()
pass运行程序首先得到的是权重的变化趋势得到如下的结果图:

然后绘制出使用
logistic regression
训练得到的分类边界,虽然有一些错误的点, 但是总体上还是对的。















 2502
2502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









