






Datawhale 知识图谱组队学习 Task 4 用户输入->知识库的查询语句
一、引言
本部分任务主要是将用户输入问答系统的自然语言转化成知识库的查询语句,因此本文将分成两部分进行介绍。
- 第一部分介绍任务所涉及的背景知识;
- 第二部分则是相应的代码和其注释
二、什么是问答系统?
2.1 问答系统简介
问答系统(Question Answering System,QA System)是用来回答人提出的自然语言问题的系统。根据划分标准不同,问答系统可以被分为各种不同的类型。
-
问答系统从知识领域划分:
- 封闭领域:封闭领域系统专注于回答特定领域的问题,由于问题领域受限,系统有比较大的发挥空间,可以导入领域知识或将答案来源全部转换成结构性资料来有效提升系统的表现;
- 开放领域:开放领域系统则希望不设限问题的内容范围,因此其难度也相对较大。
-
问答系统从实现方式划分:
- 基于流水线(pipeline)实现:如下图 1 所示,基于流水线实现的问答系统有四大核心模块,分别由自然语言理解(NLU)、对话状态跟踪器(DST)、对话策略(DPL)和自然语言生成(NLG)依次串联构成的一条流水线,各模块可独立设计,模块间协作完成任务。
- 基于端到端(end-to-end)实现:基于端到端实现的问答系统,主要是结合深度学习技术,通过海量数据训练,挖掘出从用户自然语言输入到系统自然语言输出的整体映射关系,而忽略中间过程的一种方法。但就目前工业界整体应用而言,工业界的问答系统目前大多采用的还是基于流水线实现的方式。

图 1 基于流水线(pipeline)实现
- 问答系统从答案来源划分:
- 「知识库问答」。是目前的研究热点。知识库问答(knowledge base question answering, KB-QA)即给定自然语言问题,通过对问题进行语义理解和解析,进而利用知识库进行查询、推理得出答案。如下图 2 所示:
- 「常问问题问答」;
- 「新闻问答」;
- 「网际网路问答」;

图 2 知识库问答
2.2 Query理解
2.2.1 Query理解介绍
Query理解 (QU,Query Understanding),简单来说就是从词法、句法、语义三个层面对 Query 进行结构化解析。
- 搜索 Query 理解包含的模块主要有:
- Query预处理
- Query纠错
- Query扩展
- Query归一
- 意图识别
- 槽值填充
- Term重要性分析;
- …
由于本任务后面代码主要涉及意图识别和槽位解析,因此这里仅对这两部分内容做介绍:
2.2.2 意图识别
- 介绍:意图识别是用来检测用户当前输入的意图,通常其被建模为将一段自然语言文本分类为预先设定的一个或多个意图的文本分类任务。
- 所用方法:和文本分类模型的方法大同小异,主要有:
- 基于词典模板的规则分类
- 传统的机器学习模型(文本特征工程+分类器)
- 深度学习模型(Fasttext、TextCNN、BiLSTM + Self-Attention、BERT等)

图 3 意图识别
2.2.3 槽值填充
- 介绍:槽值填充就是根据我们既定的一些结构化字段,将用户输入的信息中与其对应的部分提取出来。因此,槽值填充经常被建模为序列标注的任务。
- 举例介绍:例如下图所示的 Query “北京飞成都的机票”,通过意图分类模型可以识别出 Query 的整体意图是订机票,在此基础上进一步语义解析出对应的出发地 Depart=“北京”,到达地 Arrive=“成都”,所以生成的形式化表达可以是:Ticket=Order(Depart,Arrive),Depart={北京},Arrive={成都}。
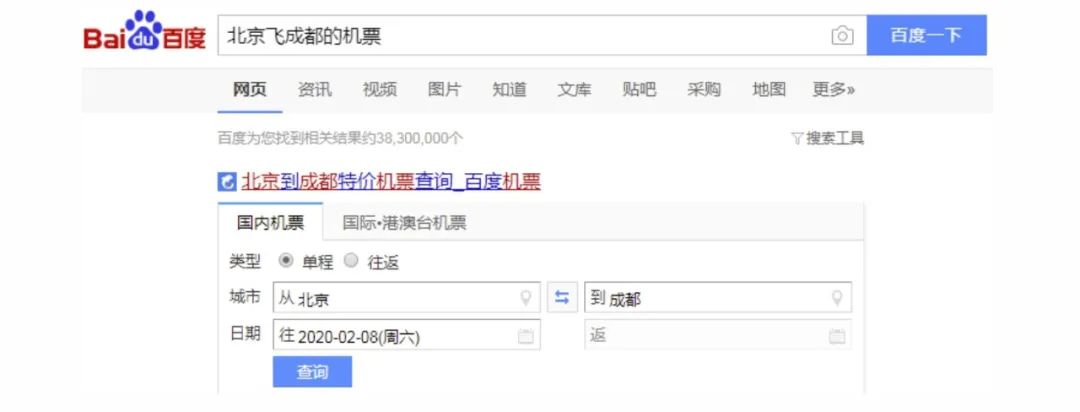
图 4 槽值填充
- 序列标注的任务常用的模型有:【注:这部分内容,第二期知识图谱组队学习将进行介绍】
- 词典匹配;
- BiLSTM + CRF;
- IDCNN
- BERT等。
三、任务实践
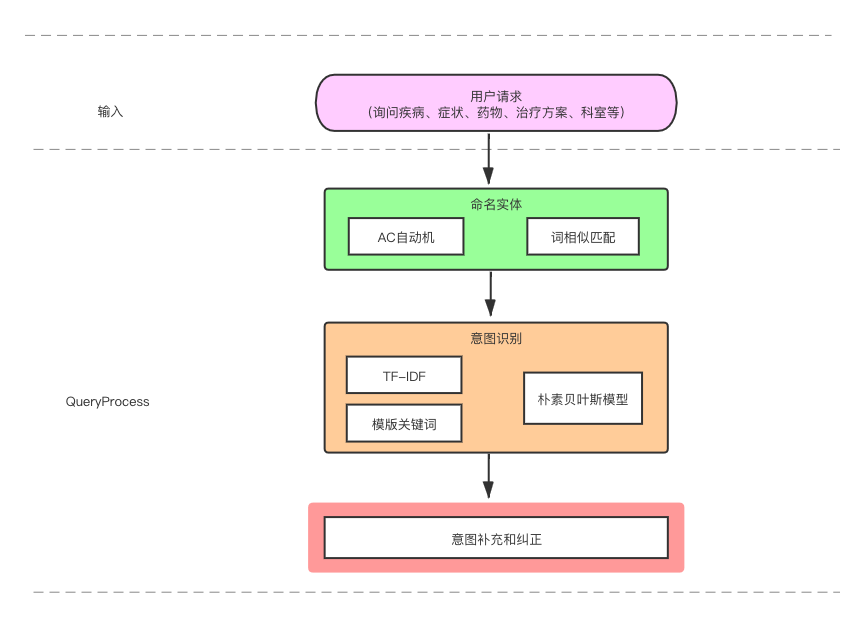
图 5 基于知识图谱的问答系统框架
四、 主体类 EntityExtractor 框架介绍
#!/usr/bin/env python3
# coding: utf-8
import os
import ahocorasick
from sklearn.externals import joblib
import jieba
import numpy as np
class EntityExtractor:
def __init__(self):
pass
# 构造actree,加速过滤
def build_actree(self, wordlist):
"""
构造actree,加速过滤
:param wordlist:
:return:
"""
pass
# 模式匹配, 得到匹配的词和类型。如疾病,疾病别名,并发症,症状
def entity_reg(self, question):
"""
模式匹配, 得到匹配的词和类型。如疾病,疾病别名,并发症,症状
:param question:str
:return:
"""
pass
# 当全匹配失败时,就采用相似度计算来找相似的词
def find_sim_words(self, question):
"""
当全匹配失败时,就采用相似度计算来找相似的词
:param question:
:return:
"""
pass
# 采用DP方法计算编辑距离
def editDistanceDP(self, s1, s2):
"""
采用DP方法计算编辑距离
:param s1:
:param s2:
:return:
"""
pass
# 计算词语和字典中的词的相似度
def simCal(self, word, entities, flag):
"""
计算词语和字典中的词的相似度
相同字符的个数/min(|A|,|B|) + 余弦相似度
:param word: str
:param entities:List
:return:
"""
pass
# 基于特征词分类
def check_words(self, wds, sent):
"""
基于特征词分类
:param wds:
:param sent:
:return:
"""
pass
# 提取问题的TF-IDF特征
def tfidf_features(self, text, vectorizer):
"""
提取问题的TF-IDF特征
:param text:
:param vectorizer:
:return:
"""
pass
# 提取问题的关键词特征
def other_features(self, text):
"""
提取问题的关键词特征
:param text:
:return:
"""
pass
# 预测意图
def model_predict(self, x, model):
"""
预测意图
:param x:
:param model:
:return:
"""
pass
# 实体抽取主函数
def extractor(self, question):
pass
五、命名实体识别任务实践
5.1 命名实体识别整体思路介绍
- step 1:对于用户的输入,先使用预先构建的疾病、疾病别名、并发症和症状的AC Tree进行匹配;
- step 2:若全都无法匹配到相应实体,则使用结巴切词库对用户输入的文本进行切分;
- step 3:然后将每一个词都去与疾病词库、疾病别名词库、并发症词库和症状词库中的词计算相似度得分(overlap score、余弦相似度分数和编辑距离分数),如果相似度得分超过0.7,则认为该词是这一类实体;
- step 4:最后排序选取最相关的词作为实体(项目所有的实体类型如下图所示,但实体识别时仅使用了疾病、别名、并发症和症状四种实体)

图 6 实体介绍
本部分所有的代码都来自 entity_extractor.py 中的 EntityExtractor 类,为了方便讲解,对类内的内容进行重新组织注释
5.2 结合代码介绍
5.2.1 构建 AC Tree
先通过 entity_extractor.py 中 类 EntityExtractor 的 build_actree 函数构建AC Tree
- 函数模块
def build_actree(self, wordlist):
"""
构造actree,加速过滤
:param wordlist:
:return:
"""
actree = ahocorasick.Automaton()
# 向树中添加单词
for index, word in enumerate(wordlist):
actree.add_word(word, (index, word))
actree.make_automaton()
return actree
- 函数调用模块
def __init__(self):
...
self.disease_path = cur_dir + 'disease_vocab.txt'
self.symptom_path = cur_dir + 'symptom_vocab.txt'
self.alias_path = cur_dir + 'alias_vocab.txt'
self.complication_path = cur_dir + 'complications_vocab.txt'
self.disease_entities = [w.strip() for w in open(self.disease_path, encoding='utf8') if w.strip()]
self.symptom_entities = [w.strip() for w in open(self.symptom_path, encoding='utf8') if w.strip()]
self.alias_entities = [w.strip() for w in open(self.alias_path, encoding='utf8') if w.strip()]
self.complication_entities = [w.strip() for w in open(self.complication_path, encoding='utf8') if w.strip()]
self.region_words = list(set(self.disease_entities+self.alias_entities+self.symptom_entities))
# 构造领域actree
self.disease_tree = self.build_actree(list(set(self.disease_entities)))
self.alias_tree = self.build_actree(list(set(self.alias_entities)))
self.symptom_tree = self.build_actree(list(set(self.symptom_entities)))
self.complication_tree = self.build_actree(list(set(self.complication_entities)))
...
5.2.2 使用AC Tree进行问句过滤
- 函数模块
def entity_reg(self, question):
"""
模式匹配, 得到匹配的词和类型。如疾病,疾病别名,并发症,症状
:param question:str
:return:
"""
self.result = {}
for i in self.disease_tree.iter(question):
word = i[1][1]
if "Disease" not in self.result:
self.result["Disease"] = [word]
else:
self.result["Disease"].append(word)
for i in self.alias_tree.iter(question):
word = i[1][1]
if "Alias" not in self.result:
self.result["Alias"] = [word]
else:
self.result["Alias"].append(word)
for i in self.symptom_tree.iter(question):
wd = i[1][1]
if "Symptom" not in self.result:
self.result["Symptom"] = [wd]
else:
self.result["Symptom"].append(wd)
for i in self.complication_tree.iter(question):
wd = i[1][1]
if "Complication" not in self.result:
self.result["Complication"] = [wd]
else:
self.result["Complication"] .append(wd)
return self.result
- 函数调用模块
def extractor(self, question):
self.entity_reg(question)
...
5.2.3 使用 相似度进行实体匹配
当AC Tree的匹配都没有匹配到实体时,使用查找相似词的方式进行实体匹配
def find_sim_words(self, question):
"""
当全匹配失败时,就采用相似度计算来找相似的词
:param question:
:return:
"""
import re
import string
from gensim.models import KeyedVectors
# 使用结巴加载自定义词典
jieba.load_userdict(self.vocab_path)
# 加载词向量
self.model = KeyedVectors.load_word2vec_format(self.word2vec_path, binary=False)
# 数据预处理,正则去除特殊符号
sentence = re.sub("[{}]", re.escape(string.punctuation), question)
sentence = re.sub("[,。‘’;:?、!【】]", " ", sentence)
sentence = sentence.strip()
# 使用结巴进行分词
words = [w.strip() for w in jieba.cut(sentence) if w.strip() not in self.stopwords and len(w.strip()) >= 2]
alist = []
# 对每个词,都让其与每类实体词典进行相似对比,
# 最终选取分数最高的实体和其属于的实体类型
for word in words:
temp = [self.disease_entities, self.alias_entities, self.symptom_entities, self.complication_entities]
for i in range(len(temp)):
flag = ''
if i == 0:
flag = "Disease"
elif i == 1:
flag = "Alias"
elif i == 2:
flag = "Symptom"
else:
flag = "Complication"
scores = self.simCal(word, temp[i], flag)
alist.extend(scores)
temp1 = sorted(alist, key=lambda k: k[1], reverse=True)
if temp1:
self.result[temp1[0][2]] = [temp1[0][0]]
# 计算词语和字典中的词的相似度
def simCal(self, word, entities, flag):
"""
计算词语和字典中的词的相似度
相同字符的个数/min(|A|,|B|) + 余弦相似度
:param word: str
:param entities:List
:return:
"""
a = len(word)
scores = []
for entity in entities:
sim_num = 0
b = len(entity)
c = len(set(entity+word))
temp = []
for w in word:
if w in entity:
sim_num += 1
if sim_num != 0:
score1 = sim_num / c # overlap score
temp.append(score1)
try:
score2 = self.model.similarity(word, entity) # 余弦相似度分数
temp.append(score2)
except:
pass
score3 = 1 - self.editDistanceDP(word, entity) / (a + b) # 编辑距离分数
if score3:
temp.append(score3)
score = sum(temp) / len(temp)
if score >= 0.7:
scores.append((entity, score, flag))
scores.sort(key=lambda k: k[1], reverse=True)
return scores
六、意图识别任务实践
6.1 意图识别整体思路介绍
- step 1:利用TF-IDF表征文本特征,同时构建一些人工特征(每一类意图常见词在句子中出现的个数);
- step 2:训练朴素贝叶斯模型进行意图识别任务;
- step 3:使用实体信息进行意图的纠正和补充。

图 7 意图识别整体举例介绍
该项目通过手工标记210条意图分类训练数据,并采用朴素贝叶斯算法训练得到意图分类模型。其最佳测试效果的F1值达到了96.68%。
6.2 意图识别整体思路介绍
6.2.1 特征构建
- TF-IDF特征
# 提取问题的TF-IDF特征
def tfidf_features(self, text, vectorizer):
"""
提取问题的TF-IDF特征
:param text:
:param vectorizer:
:return:
"""
jieba.load_userdict(self.vocab_path)
words = [w.strip() for w in jieba.cut(text) if w.strip() and w.strip() not in self.stopwords]
sents = [' '.join(words)]
tfidf = vectorizer.transform(sents).toarray()
return tfidf
- 人工特征
self.symptom_qwds = ['什么症状', '哪些症状', '症状有哪些', '症状是什么', '什么表征', '哪些表征', '表征是什么',
'什么现象', '哪些现象', '现象有哪些', '症候', '什么表现', '哪些表现', '表现有哪些',
'什么行为', '哪些行为', '行为有哪些', '什么状况', '哪些状况', '状况有哪些', '现象是什么',
'表现是什么', '行为是什么'] # 询问症状
self.cureway_qwds = ['药', '药品', '用药', '胶囊', '口服液', '炎片', '吃什么药', '用什么药', '怎么办',
'买什么药', '怎么治疗', '如何医治', '怎么医治', '怎么治', '怎么医', '如何治',
'医治方式', '疗法', '咋治', '咋办', '咋治', '治疗方法'] # 询问治疗方法
self.lasttime_qwds = ['周期', '多久', '多长时间', '多少时间', '几天', '几年', '多少天', '多少小时',
'几个小时', '多少年', '多久能好', '痊愈', '康复'] # 询问治疗周期
self.cureprob_qwds = ['多大概率能治好', '多大几率能治好', '治好希望大么', '几率', '几成', '比例',
'可能性', '能治', '可治', '可以治', '可以医', '能治好吗', '可以治好吗', '会好吗',
'能好吗', '治愈吗'] # 询问治愈率
self.check_qwds = ['检查什么', '检查项目', '哪些检查', '什么检查', '检查哪些', '项目', '检测什么',
'哪些检测', '检测哪些', '化验什么', '哪些化验', '化验哪些', '哪些体检', '怎么查找',
'如何查找', '怎么检查', '如何检查', '怎么检测', '如何检测'] # 询问检查项目
self.belong_qwds = ['属于什么科', '什么科', '科室', '挂什么', '挂哪个', '哪个科', '哪些科'] # 询问科室
self.disase_qwds = ['什么病', '啥病', '得了什么', '得了哪种', '怎么回事', '咋回事', '回事',
'什么情况', '什么问题', '什么毛病', '啥毛病', '哪种病'] # 询问疾病
def other_features(self, text):
"""
提取问题的关键词特征
:param text:
:return:
"""
features = [0] * 7
for d in self.disase_qwds:
if d in text:
features[0] += 1
for s in self.symptom_qwds:
if s in text:
features[1] += 1
for c in self.cureway_qwds:
if c in text:
features[2] += 1
for c in self.check_qwds:
if c in text:
features[3] += 1
for p in self.lasttime_qwds:
if p in text:
features[4] += 1
for r in self.cureprob_qwds:
if r in text:
features[5] += 1
for d in self.belong_qwds:
if d in text:
features[6] += 1
m = max(features)
n = min(features)
normed_features = []
if m == n:
normed_features = features
else:
for i in features:
j = (i - n) / (m - n)
normed_features.append(j)
return np.array(normed_features)
6.2.2 使用朴素贝叶斯进行文本分类
- 项目没有给出训练过程,可参考下面sklearn的例子
# 项目没有给出训练过程,可参考下面sklearn的例子
from sklearn.naive_bayes import MultinomialNB
mnb = MultinomialNB()
mnb.fit(X_train,y_train)
y_predict = mnb.predict(X_test)
# 意图分类模型文件
self.tfidf_path = os.path.join(cur_dir, 'model/tfidf_model.m')
self.nb_path = os.path.join(cur_dir, 'model/intent_reg_model.m') #朴素贝叶斯模型
self.tfidf_model = joblib.load(self.tfidf_path)
self.nb_model = joblib.load(self.nb_path)
# 意图预测
tfidf_feature = self.tfidf_features(question, self.tfidf_model)
other_feature = self.other_features(question)
m = other_feature.shape
other_feature = np.reshape(other_feature, (1, m[0]))
feature = np.concatenate((tfidf_feature, other_feature), axis=1)
predicted = self.model_predict(feature, self.nb_model)
intentions.append(predicted[0])
- 根据所识别的实体进行补充和纠正意图
# 已知疾病,查询症状
if self.check_words(self.symptom_qwds, question) and ('Disease' in types or 'Alia' in types):
intention = "query_symptom"
if intention not in intentions:
intentions.append(intention)
# 已知疾病或症状,查询治疗方法
if self.check_words(self.cureway_qwds, question) and \
('Disease' in types or 'Symptom' in types or 'Alias' in types or 'Complication' in types):
intention = "query_cureway"
if intention not in intentions:
intentions.append(intention)
# 已知疾病或症状,查询治疗周期
if self.check_words(self.lasttime_qwds, question) and ('Disease' in types or 'Alia' in types):
intention = "query_period"
if intention not in intentions:
intentions.append(intention)
# 已知疾病,查询治愈率
if self.check_words(self.cureprob_qwds, question) and ('Disease' in types or 'Alias' in types):
intention = "query_rate"
if intention not in intentions:
intentions.append(intention)
# 已知疾病,查询检查项目
if self.check_words(self.check_qwds, question) and ('Disease' in types or 'Alias' in types):
intention = "query_checklist"
if intention not in intentions:
intentions.append(intention)
# 查询科室
if self.check_words(self.belong_qwds, question) and \
('Disease' in types or 'Symptom' in types or 'Alias' in types or 'Complication' in types):
intention = "query_department"
if intention not in intentions:
intentions.append(intention)
# 已知症状,查询疾病
if self.check_words(self.disase_qwds, question) and ("Symptom" in types or "Complication" in types):
intention = "query_disease"
if intention not in intentions:
intentions.append(intention)
# 若没有检测到意图,且已知疾病,则返回疾病的描述
if not intentions and ('Disease' in types or 'Alias' in types):
intention = "disease_describe"
if intention not in intentions:
intentions.append(intention)
# 若是疾病和症状同时出现,且出现了查询疾病的特征词,则意图为查询疾病
if self.check_words(self.disase_qwds, question) and ('Disease' in types or 'Alias' in types) \
and ("Symptom" in types or "Complication" in types):
intention = "query_disease"
if intention not in intentions:
intentions.append(intention)
# 若没有识别出实体或意图则调用其它方法
if not intentions or not types:
intention = "QA_matching"
if intention not in intentions:
intentions.append(intention)
self.result["intentions"] = intentions
后续就是通过上述得到的意图信息和实体信息选择对应的模版,并将实体信息填充入组成查询语句进行数据库查询。














 576
576











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









