






论文标题:
Learning Affinity from Attention: End-to-End Weakly-Supervised Semantic Segmentation with Transformers
作者信息:

论文地址:
https://arxiv.org/abs/2203.02664
代码地址:
https://github.com/rulixiang/afa.
Abstract
作者认为现在的弱监督分割大多是基于卷积网络的,这些模型缺乏global 信息,从而导致分割中得到的图像不完整。作者引入了transfomer去整合全局信息,利用自注意机制和semantic affinity 以生成假标签。
作者提处理AFA (Affinity from Attention)module,利用transformer中多头注意力学习semantic affinity,refine初步生成的假标签。
还有PAR(Pixel-Adaptive Refinement ),利用像素的low-level image appearance(位置、颜色)也是去refine假标签。
Introduction
WSSS(weakly-supervised semantic segmentation)任务使用图像级标签获得分割结果。WSSS常见的有几种方法:
1.multi-stage方法:训练一个分类模型,生成CAM(假标签),refine假标签,最后再训练一个标砖赌地语义分割模型。缺点是,训练流复杂而且会降低运行效率。
2.end-to-end方法:仍然需要生成CAM,且和1相同大多采用CNN,fail to explore the global feature relations 。因此也会显著影响假标签的质量。
3.transformer结构:作者认为 discovering more integral object regions,克服了CNN的缺点;多头自注意力机制也可以 capture semantic level affinity,


作者进一步介绍了本文的贡献:
1.使用transformer生成初始的CAM(假标签)。
2.设计AFA,利用transformer机制, 获得pseudo affinity labels 去监督学习多头注意力中提取的semantic affinity。学到的affinity使用随机行走算法去refine初始假标签。
3.设计RAP,融入了RGB信息和位置信息,也用于refine假标签。
Methodology
下图为该论文的总体流程图:
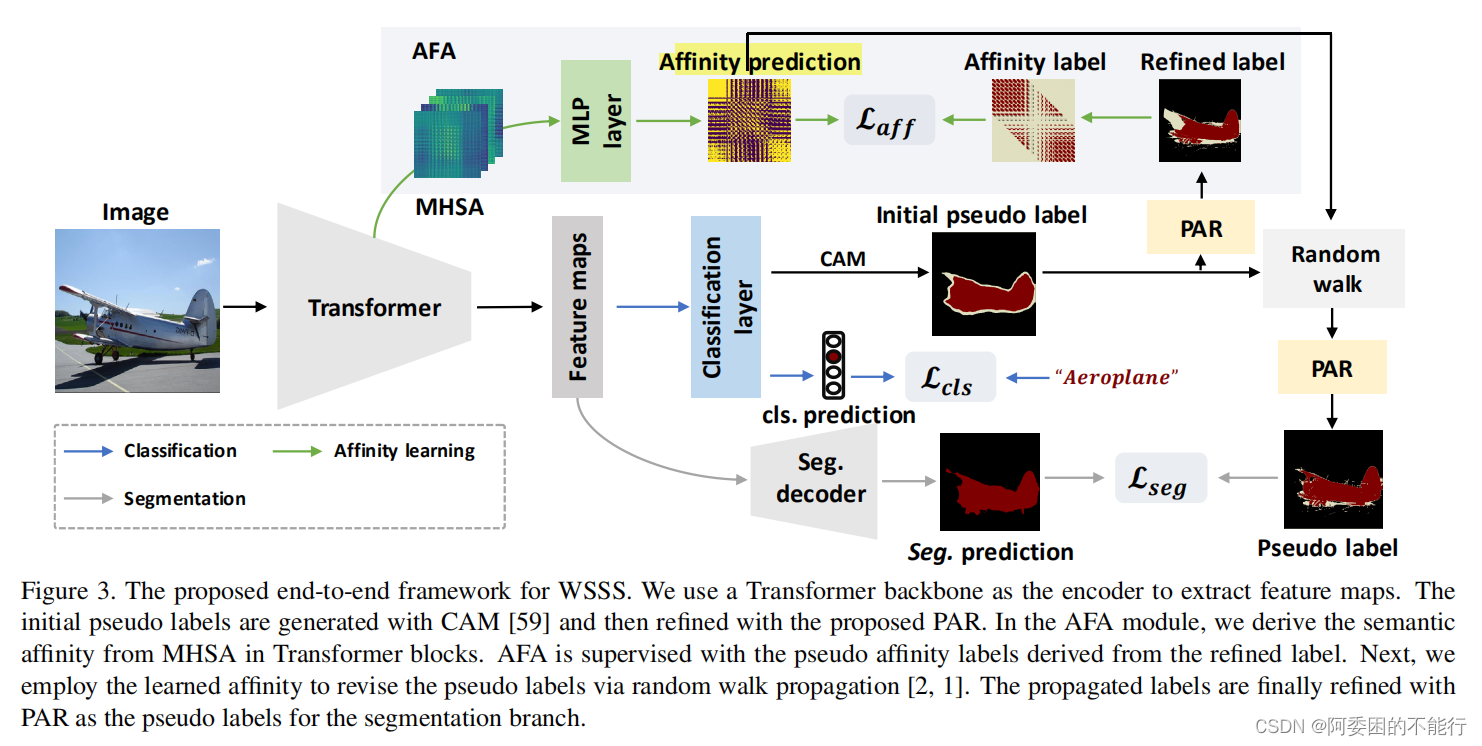
Transformer backbone
常规的transformer处理方式,将图片划分成patch进而映射成token,然后计算注意力获得feature maps

CAM 生成
常规的CAM生成方式,根据输出的类的权重对由特征图进行加权求和。
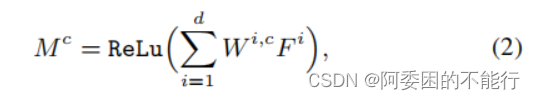
Affinity from Attention
作者认为图1和图2中反映了Transformer的多头自注意力机制能够体现出sematic level affinity。
记transformer获得的特征图为S,首先求取初始emantic affinity matrix—A。
affinity是一个对称的概念,如像素1和像素2是互相affinity的,但是多头注意力可视为有向图模型 (单向的,我不太理解,这里作者给出了相关文献可供查阅),这里将S和S的转置输入到一个MLP层中获得A。
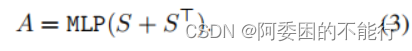
a.Pseudo Affinity Label Generation
需要寻找一个对Affinity的监督信息,这个信号从CAM的假标签经refine后获得(如图3)。这里给出了具体的获得方法:
记CAM为M,则设置两个参数
β
h
\beta_h
βh和
β
t
\beta_t
βt 类似于分段限幅,由M生成假标签
Y
p
Y_p
Yp 。
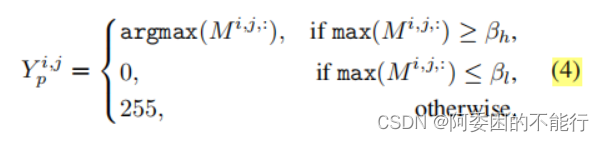
对假标签
Y
p
Y_p
Yp 继续处理生成affinity label
Y
a
f
f
Y_{aff}
Yaff:
如果像素1和2同数值,affinity 记为正向,否则记为负向;
如果两个像素其中一个位于 ignored region 则忽略他们之间的affinity (应该是赋值255,和公式(4)一致);
另外也只考虑同一个windows下 (不懂啥是同一个window) 的像素的affinity,
最后获得也是矩阵
Y
a
f
f
Y_{aff}
Yaff。
b.Affinity Loss
对获得的A在监督信号下
Y
a
f
f
Y_{aff}
Yaff进行学习,损失函数设计如下:
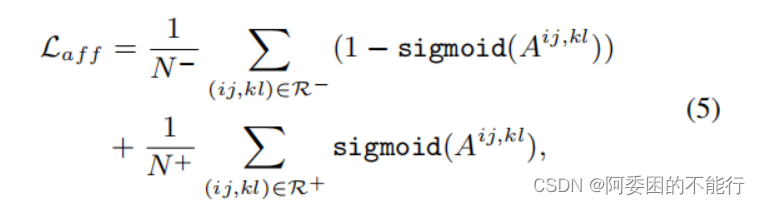
就是说对正向affinity和负向affinity分别求sigmoid或者其相反数,然后取均值。
(我不太理解它的原理,尤其这个
A
A
A上面的这个逗号是做个什么运算,是计算两个像素的差值?或者?)
作者认为这个公式可以保证网络可以confident的学习语义亲和关系。
c.Propagation with Affinity
这里要将学到的semantic affinity用于refine初始的CAM,使用的是random Walk算法:
对于semantic affinity 矩阵A,定义semantic transition matrix矩阵T:
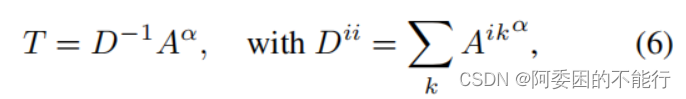
对于初始的CAM记为M,利用公式:
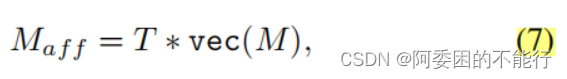
(公式(6)和公式(7)的原理我不懂,应该就是random Walk算法) 这个传播算法可以扩散高affinity semantic信息而抑制错误的
激活区域,来使activate map获得更好的边界。
Pixel-Adaptive Refinement
作者受pixel-adaptive convolution(参考文献4和37)的启发,设计了RAP,参考图3,RAP融合了空间位置和RGB信息,定义了一种 low level 的affinity pairwise,其作用还是对pseudo labels做refine,
CRF是一种典型的refine处理方式,但是它并不适合端到端网络,另外它的运行效率也比较的低。
PAR的具体做法:
对于一个输入图像I,其中的两个像素位置(i,j)和(k,l)和,定义RGB和空间位置计算对为:
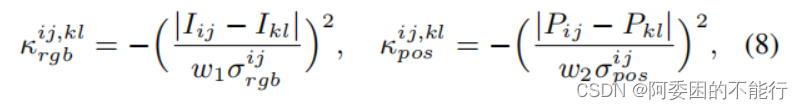
之后构建affinity的核心算子(类似于卷积核),主要是在一个像素点的邻域中,norm公式(8),并做softmax处理。
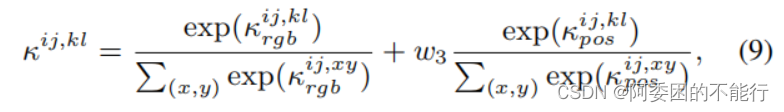
基于公式(8)的affinity kernal ,作者refine了初始的CAM和propagated CAM(参考图3),采用公式(10)进行多代的优化:
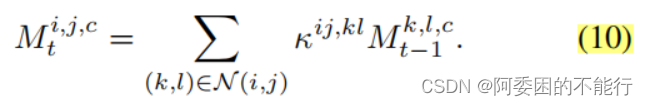
(公式10的原理我也没看懂(本质应该是做卷积),以及要具体怎么迭代计算也不懂) 可以理解为,利用当前位置(像素/特征)和邻域内其他位置处间的联系,来更新当前l位置的label。对于一个邻域
N
(
.
)
N(.)
N(.),作者设计了多个不同的不同的空洞卷积rate,来保证训练的效率。
Network Training
该模型主要涉及三种损失函数,分别使分类损失函数
L
c
l
s
L_{cls}
Lcls、分割损失函数
L
s
e
g
L_{seg}
Lseg和affinity训练损失函数
L
a
f
f
L_{aff}
Laff,其中:
分类损失函数见公式(11)
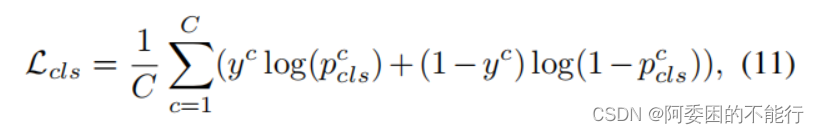
分割损失是cross-entropy loss,affinity损失就是公式(5),另外作者引入了正则化损失
L
r
e
g
L_{reg}
Lreg,总的损失函数就是公式(12):
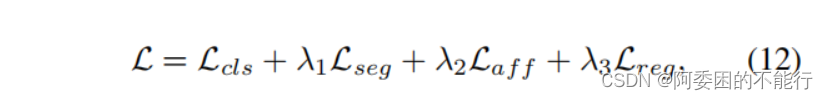















 618
618











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









